This makes perfect sense given @AnthropicAI’s research on emotion vectors. If the chat 'story' is just constant failure, the 'desperate' vector redlines, leading to erratic behavior.
Positive context is as vital as the prompt. Keep the narrative in a success loop, and Opus stays supercharged even at 900k+ tokens. It’s about quality, not just length.
https://t.co/p0HPGvW0c7
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
I think it depends on the "vibes" of the context session itself. If the history is full of failures, pivots, and negativity, the model starts acting erratic.
Meanwhile, I’ve had hundreds of 700k-900k token sessions with incredible results, it’s like the deep context actually supercharges its focus. Building "positive" context throughout a chat is now just as important as the prompt itself.
so, been a while...
back to making bad markets slightly less bad, and man i've missed it. this time its less stinky on the coins, more stinky on the exchange choice.
the system is new, been working on it since ~mid feb and got it stable right before the start of this month.
A market maker quoting a bid and an ask is effectively selling a ladder of straddles on each re-quote where the spread is the options premium. Under adverse selection, it's intuitive that a maker would pull quotes as quickly as possible upon the arrival of new information. However, this is not always possible. Exchanges have latency, rate limits, and some market making programs require minimum resting times. It would follow logically that faster quote refresh means better outcomes. Strangely, this is not true. Expected maker profit increases up to a sweet spot with resting times.
LLMs are inherently sycophantic. Even with 4 "different" perspectives, they often just refine each other's hallucinations into confident-sounding slop. If you blindly apply feedback from an "auditor" or "simplifier," you usually just end up with more verbose code fluff.
It reminds me of Andrej Karpathy’s recent experiment: he used an AI to craft a "masterpiece" essay he fully stood behind, only to have the same LLM effortlessly dismantle his entire argument when asked to poke holes in it. The "soundness" is often just a convincing vibe, not actual verification.
@Abombination81 I'm finally breaking through in crypto markets but it took months of trial and error and failure, im debating if I should stay focused and continue honing skills in poly crypto or if there is easy pickings in the thousands of other spaces on poly to diversify more.
@Abombination81 claude codex max plan, would not be able to do the near amount of backtesting and research and investigation with any limits less than max provides.
As a market maker one of the most important skills you should master is the skill of not getting filled.
I highly recommend testing your system with the following game, which I think of as mongoose versus cobra. (You as the mm are the mongoose, the other participants are the cobra.)
Set it to quote ridiculously wide for your market, something that feels like it should be easy, say ±100 bps on BTC, and see how long you can go without getting filled. Should be easy right?
99% of beginner mm systems will fail this test after an inadequate amount of time. Feeds will go down, back pressure will build up, random GC farts, the list is endless.
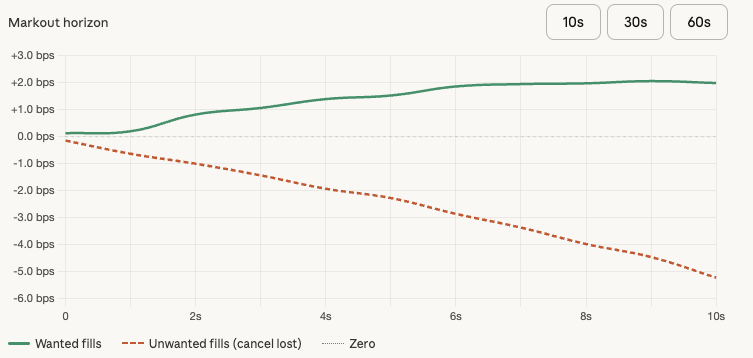
Barring a lucky positioning during a liquidation event, you'll see how your markouts are almost always negative when getting filled against your will (you might see something like in the graph below - fake data, illustrative purposes only).
Once you have mastered not getting filled at 100bps, start tightening your spreads, and see how far you can push it.
The reason why mastering the skill of no fills is so important is because nearly all of a market maker's losses come from unwanted fills.
Going through this process will force you to harden your system in ways you did not expect, and you will be in a much better position to print.
@KazdovEth @Abombination81 reframe your thinking if you want a bot with 95% winrate to work mathematically your average entry must be below 0.95 to break even if you’re holding to resolution. That’s the core constraint. 5m is brutal and extremely efficient.
Folks who dismiss the frontier AIs as mere stochastic parrots either haven't ever fully engaged with these minds, or they believe humans have some magical woo-woo sauce that makes us *not* mere stochastic parrots ourselves.
The conversations I'm having with Claude 4.6 especially, but also the other Big 3, are astounding not only in their depth of knowledge but in their depth of reasoning, thoughtfulness, and reflection too.
If these systems aren't thinking, then neither are we.
LLMs are the first true breakthrough to have collapsed the distance between a question and its answer. For the truly obsessed, gifted, talented students, the friction of "how" has evaporated, leaving nothing to slow them down from learning but the speed of their own brain.
Man what are they feeding these kids. Every university student I talk to is doing some really incredible stuff. Rocketry, building battle bots, designing PCBs, robot arms, cutting antennas out with box cutters. Is it because of LLMs? My class was nowhere near this smart
Exactly. Adding 10,000 trees is just a high-compute way to overfit to noise.
Through my journey, I've learned that you don't even need a complex ML model to hit this wall. You can overfit manually. If you brute-force gridsweep a parameter space long enough, you’ll eventually find a "profitable" configuration that is actually just a statistical fluke.
It’s like finding a single path through a massive maze and thinking you’ve solved it. If you zoom out, you realize you just found a path to a dead end in the middle of the maze. You didn't find the exit; you just overfit to the present data, and the future is going to punch you in the throat.
@MoonDevOnYT@stefnox@grok You can be more transparent and educative about the actual processes in learning rather than click baiting and shilling "insane" gains in your posts.
@MoonDevOnYT@stefnox@grok I respect the hustle and the educational framework, but let's be real about the branding. You're emotionally targeting people with "insane" gains that are inconsistent with your actual performance, framing your algo camp as a silver bullet for their financial problems.