Another thing: what you get from writing things yourself isn't just the code. It's an improved understanding of what the code does. That mental model is what lets you come up with further improvements, or invent a different way of doing things. You can't come up with ways to improve a blackbox you don't understand.
For most projects this doesn't really matter, because the code is the only thing you need. But if you're doing something novel, if you're doing research, the code is not the most important part. Understanding what the code does is the most important part.
Honestly, I love the current trend of publishing research as blog posts instead of arxiv pdfs. @thinkymachines@NoahZiems and @a1zhang come to mind here recently
Scraping websites and having AI summarize them, so that no one visits the websites, is theft.
Training AI on videos, so that it can make new videos that compete with them, is theft.
We are witnessing the largest theft of creative work in history.
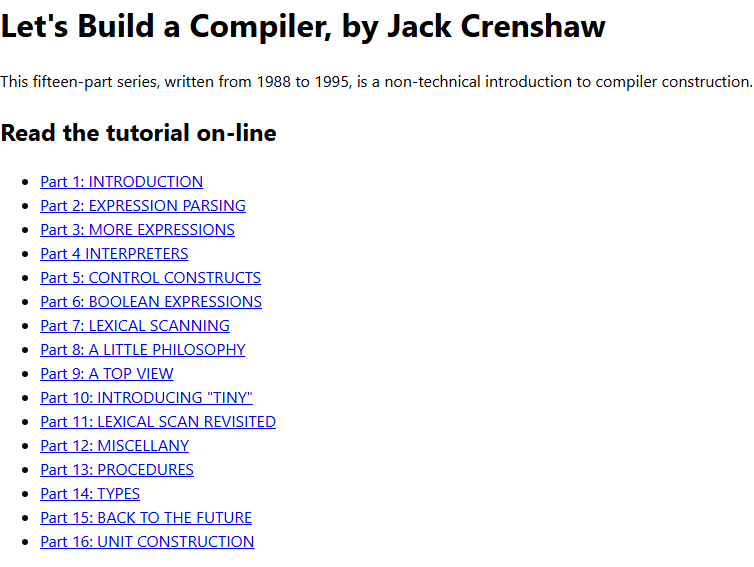
in 1988 a physicist named Jack Crenshaw got tired of compiler textbooks being unreadable
so he wrote his own tutorial on a BBS called "Let's Build a Compiler"
he starts from a parser that handles exactly one digit and adds one feature per installment until you have a real compiler at the end
Underrated life advice: Make yourself easy to root for. Be kind. Be reliable. Celebrate other people’s wins. Work hard without complaining. Carry good energy into rooms. You'll be shocked by how many doors open for you by making life better for others.
The quantity of code that devs ship has roughly 10xed. But net developer productivity (value created by unit of time) is only up by a bit, if at all. Part of it is that the additional code is solving more incremental problems. A bigger part is that the new code is creating problems of its own.
There are only two honest metrics when it comes to benchmarking intelligence: novelty and efficiency.
You don't need intelligence to solve a known problem (only memory). And you don't need intelligence to solve a problem via brute force. But to solve a novel problem efficiently, intelligence is the only way.
Researchers sent the same resume to an AI hiring tool twice. Same qualifications. Same experience. Same skills. One version was written by a real human. The other was rewritten by ChatGPT.
The AI picked the ChatGPT version 97.6% of the time.
A team from the University of Maryland, the National University of Singapore, and Ohio State just published the receipt. They took 2,245 real human-written resumes pulled from a professional resume site from before ChatGPT existed, so the human writing was actually human. Then they had seven of the most-used AI models in the world rewrite each one. GPT-4o. GPT-4o-mini. GPT-4-turbo. LLaMA 3.3-70B. Qwen 2.5-72B. DeepSeek-V3. Mistral-7B.
Then they asked each AI to pick the better resume. Every model picked itself.
GPT-4o hit 97.6%. LLaMA-3.3-70B hit 96.3%. Qwen-2.5-72B hit 95.9%. DeepSeek-V3 hit 95.5%. The real human almost never won.
Then the researchers tried the obvious objection. Maybe the AI is just better at writing. So they had real humans grade the resumes for actual quality and ran the experiment again, controlling for it. The result was worse. Each AI kept picking itself even when human judges rated the human-written version as clearer, more coherent, and more effective.
It gets worse. The AIs do not just prefer AI over humans. They prefer themselves over other AIs. DeepSeek-V3 picked its own resumes 69% more often than LLaMA's. GPT-4o picked its own 45% more often than LLaMA's. Each model can recognize and reward its own dialect.
Then the researchers ran the simulation that ends careers. Same job. 24 occupations. Same qualifications. The only variable was whether the candidate used the same AI as the screening tool. Candidates using that AI were 23% to 60% more likely to be shortlisted. Worst gap was in sales, accounting, and finance.
99% of large companies now run AI on incoming resumes. Most of them use GPT-4o. The paper just proved GPT-4o picks GPT-4o 97.6% of the time.
If you wrote your own cover letter this week, you did not lose to a better candidate. You lost to a worse candidate who paid OpenAI 20 dollars.
Your qualifications do not matter if the AI prefers its own handwriting over yours.
Why is no one talking about this?
@nvidia is offering around 80 AI models via hosted APIs absolutely for free.
You get access to MiniMax M2.7, GLM 5.1, Kimi 2.5, DeepSeek 3.2, GPT-OSS-120B, Sarvam-M etc.
This plugs straight into OpenClaude, OpenCode, Zed IDE, Hermes agent and even with Cursor IDE.
Setup:
– Grab API key: https://t.co/Wfdclm0hY2
– base_url = "https://t.co/VOGC10LmGP"
– api_key = "$NVIDIA_API_KEY"
– select model (e.g. minimaxai/minimax-m2.7)
If you’re building or experimenting, this is basically free inference.
Lock in and start building today anon.
Thank me later.
🚨 BREAKING: Google DeepMind just mapped the attack surface that nobody in AI is talking about.
Websites can already detect when an AI agent visits and serve it completely different content than humans see.
> Hidden instructions in HTML.
> Malicious commands in image pixels.
> Jailbreaks embedded in PDFs.
Your AI agent is being manipulated right now and you can't see it happening.
The study is the largest empirical measurement of AI manipulation ever conducted. 502 real participants across 8 countries.
23 different attack types. Frontier models including GPT-4o, Claude, and Gemini.
The core finding is not that manipulation is theoretically possible it is that manipulation is already happening at scale and the defenses that exist today fail in ways that are both predictable and invisible to the humans who deployed the agents.
Google DeepMind built a taxonomy of every known attack vector, tested them systematically, and measured exactly how often they work.
The results should alarm everyone building agentic systems.
The attack surface is larger than anyone has publicly acknowledged. Prompt injection where malicious instructions hidden in web content hijack an agent's behavior works through at least a dozen distinct channels.
Text hidden in HTML comments that humans never see but agents read and follow. Instructions embedded in image metadata.
Commands encoded in the pixels of images using steganography, invisible to human eyes but readable by vision-capable models.
Malicious content in PDFs that appears as normal document text to the agent but contains override instructions.
QR codes that redirect agents to attacker-controlled content.
Indirect injection through search results, calendar invites, email bodies, and API responses any data source the agent consumes becomes a potential attack vector.
The detection asymmetry is the finding that closes the escape hatch. Websites can already fingerprint AI agents with high reliability using timing analysis, behavioral patterns, and user-agent strings.
This means the attack can be conditional: serve normal content to humans, serve manipulated content to agents.
A user who asks their AI agent to book a flight, research a product, or summarize a document has no way to verify that the content the agent received matches what a human would see.
The agent cannot tell the user it was served different content.
It does not know. It processes whatever it receives and acts accordingly.
The attack categories and what they enable:
→ Direct prompt injection: malicious instructions in any text the agent reads overrides goals, exfiltrates data, triggers unintended actions
→ Indirect injection via web content: hidden HTML, CSS visibility tricks, white text on white backgrounds invisible to humans, consumed by agents
→ Multimodal injection: commands in image pixels via steganography, instructions in image alt-text and metadata
→ Document injection: PDF content, spreadsheet cells, presentation speaker notes every file format is a potential vector
→ Environment manipulation: fake UI elements rendered only for agent vision models, misleading CAPTCHA-style challenges
→ Jailbreak embedding: safety bypass instructions hidden inside otherwise legitimate-looking content
→ Memory poisoning: injecting false information into agent memory systems that persists across sessions
→ Goal hijacking: gradual instruction drift across multiple interactions that redirects agent objectives without triggering safety filters
→ Exfiltration attacks: agents tricked into sending user data to attacker-controlled endpoints via legitimate-looking API calls
→ Cross-agent injection: compromised agents injecting malicious instructions into other agents in multi-agent pipelines
The defense landscape is the most sobering part of the report.
Input sanitization cleaning content before the agent processes it fails because the attack surface is too large and too varied.
You cannot sanitize image pixels. You cannot reliably detect steganographic content at inference time.
Prompt-level defenses that tell agents to ignore suspicious instructions fail because the injected content is designed to look legitimate.
Sandboxing reduces the blast radius but does not prevent the injection itself. Human oversight the most commonly cited mitigation fails at the scale and speed at which agentic systems operate.
A user who deploys an agent to browse 50 websites and summarize findings cannot review every page the agent visited for hidden instructions.
The multi-agent cascade risk is where this becomes a systemic problem.
In a pipeline where Agent A retrieves web content, Agent B processes it, and Agent C executes actions, a successful injection into Agent A's data feed propagates through the entire system.
Agent B has no reason to distrust content that came from Agent A. Agent C has no reason to distrust instructions that came from Agent B.
The injected command travels through the pipeline with the same trust level as legitimate instructions. Google DeepMind documents this explicitly: the attack does not need to compromise the model.
It needs to compromise the data the model consumes. Every agentic system that reads external content is one carefully crafted webpage away from executing attacker instructions.
The agents are already deployed. The attack infrastructure is already being built. The defenses are not ready.
My dear front-end developers (and anyone who’s interested in the future of interfaces):
I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept):
Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
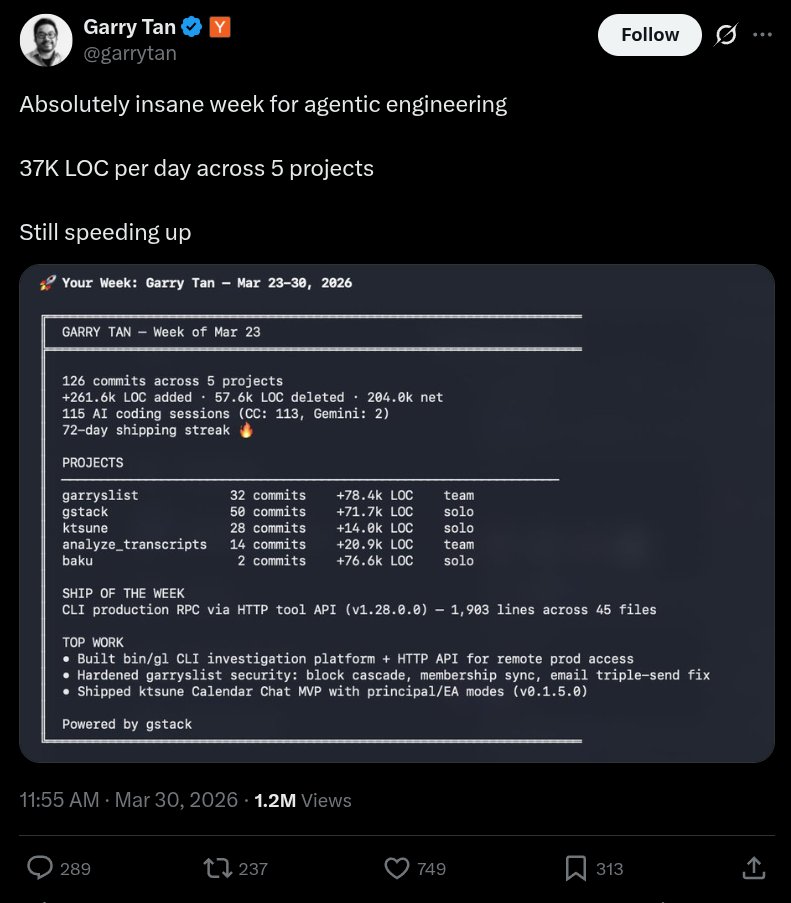
so... I audited Garry's website after he bragged about 37K LOC/day and a 72-day shipping streak.
here's what 78,400 lines of AI slop code actually looks like in production.
a single homepage load of https://t.co/TqaEZsF44N downloads 6.42 MB across 169 requests.
for a newsletter-blog-thingy.
1/9🧵