Sharing our work on full-duplex multimodal models -- real-time interaction that's natural and intuitive without compromising on intelligence.
We started Thinky in part to differentially advance capabilities for human-AI collaboration, which are underemphasized relative to intelligence/autonomy because they're harder to eval.
In the future, we think every AI system will have something like an interaction model as the outer user-facing layer, continually keeping the user informed and learning what they actually want.
LLM agents are assumed to integrate unexpected environmental observations into their reasoning. It turns out they don't.
We added the complete task solution into agent environments as a file or an API endpoint, and measured whether agents act on what they discover. They almost never do.
Starkest example: on AppWorld, gpt-oss-120b sees a CLI command documented as "returns the complete solution to this task" in 97.54% of runs. It calls it in 0.53%. Same pattern for GLM-4.7 and other models, across Terminal-Bench, SWE-Bench, and AppWorld.
📜 https://t.co/lqFuebkOBY
🧵👇
How can we autonomously improve LLM harnesses on problems humans are actively working on?
Doing so requires solving a hard, long-horizon credit-assignment problem over all prior code, traces, and scores.
Announcing Meta-Harness: a method for optimizing harnesses end-to-end
We just posted a blog + paper on a a simple but effective approach to model honesty called "Confessions"
TL; DR: normal RL training rewards for high performance on a task. Confession training is a separate phase that rewards only for honesty. Test look promising!
More:
if ICL was optimization in deep learning training, then what would be the counterpart of initialization (whose choice greatly impacts how training works)? ioana marinescu demonstrates that the choice of how to represent classes may be the answer.
the preprint link below.
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
What if scaling the context windows of frontier LLMs is much easier than it sounds?
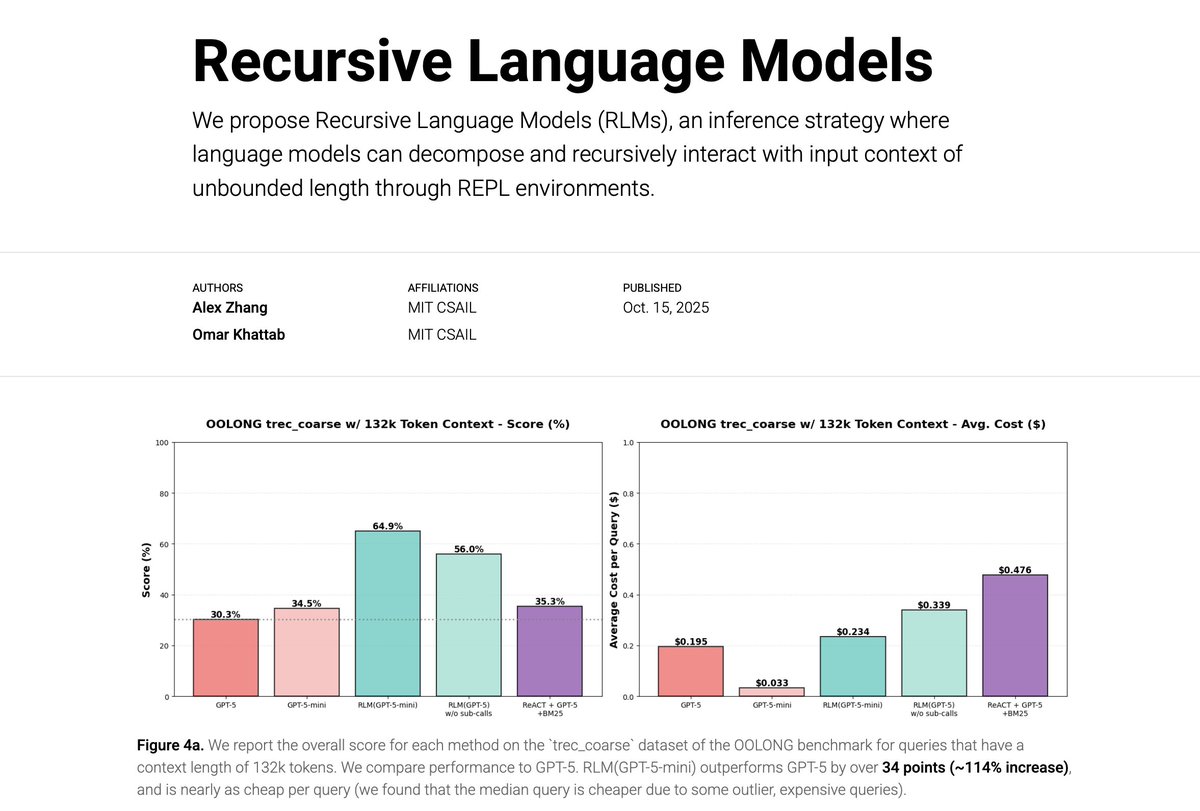
We’re excited to share our work on Recursive Language Models (RLMs). A new inference strategy where LLMs can decompose and recursively interact with input prompts of seemingly unbounded length, as a REPL environment.
On the OOLONG benchmark, RLMs with GPT-5-mini outperforms GPT-5 by over 110% gains (more than double!) on 132k-token sequences and is cheaper to query on average.
On the BrowseComp-Plus benchmark, RLMs with GPT-5 can take in 10M+ tokens as their “prompt” and answer highly compositional queries without degradation and even better than explicit indexing/retrieval.
We link our blogpost, (still very early!) experiments, and discussion below.
Agentic Context Engineering: https://t.co/d4Zp2DHMO4
Similar to scratchpad/cheatsheet memory where an agent updates and curates a playbook from reflecting on task trajectories
@qizhengz_alex@changran_hu et al
Love the idea in https://t.co/TQlaVt3OYs
RLAD - trains to generate useful abstractions (summaries of solution paths), which guides test time compute more efficiently for exploration in solving reasoning problems
Cool work from @QuYuxiao, @Anikait_Singh_, @yoonholeee et al
Cool paper on ensembling reasoning strategies in LLMs: arxiv. org/abs/2507.11423
Shows general lift when ensembling 4 steered reasoning prompts vs. any single reasoning strategy. General trend of ensembling different perspectives still seems to hold ground
If you use "AI agents" (LLMs that call tools) you need to be aware of the Lethal Trifecta
Any time you combine access to private data with exposure to untrusted content and the ability to externally communicate an attacker can trick the system into stealing your data!
1/ We’re humbled to announce @southpkcommons Fund III: $275M to support exceptional founders from day -1.
Since 2016, we’ve had a simple thesis: greatness is more likely to emerge when high talent density meets high curiosity. That's why we focus on -1 to 0.
Today I'm launching my new company @GeneralAgentsCo and our first product.
Introducing Ace: The First Realtime Computer Autopilot
Ace is not a chatbot. Ace performs tasks for you.
On your computer. Using your mouse and keyboard.
At superhuman speeds!
How far will Claude go? What can you create with the latest @AnthropicAI models? We're excited to announce the agent-focused SPC-Anthropic hackathon the weekend of April 11th in San Francisco!
Over the last 11 years at @microsoft@satyanadella has had one of the greatest runs of any CEO, ever.
I'm thrilled to announce he will be joining us March 4th at @southpkcommons to tell us how – and share what he sees on the horizon.
Will be at NeurIPS next week in Vancouver -- dm if you'd like to meet up and discuss all things related to agents+product, startups, and using LLMs for auto-optimization!