Hard times create strong men.
Strong men create C.
C creates good times.
Good times create Python programmers.
Python programmers create AI.
AI creates vibe coders.
Vibe coders create weak men.
Weak men create hard times.
Quanto imóveis tem o estado: não sabemos.
Alunos sem professor: não sabemos
Número de imigrantes: não sabemos.
População: não sabemos.
PIB per capita: na prática, também não sabemos.
Podia continuar. Não há dados. Em Portugal governa-se por instinto.
With AI, leftists have a chance to full send UBI or a massive welfare state, but instead they've chosen to be reactionaries defending to death an exploitative labour and IP system that largely doesn't even benefit them.
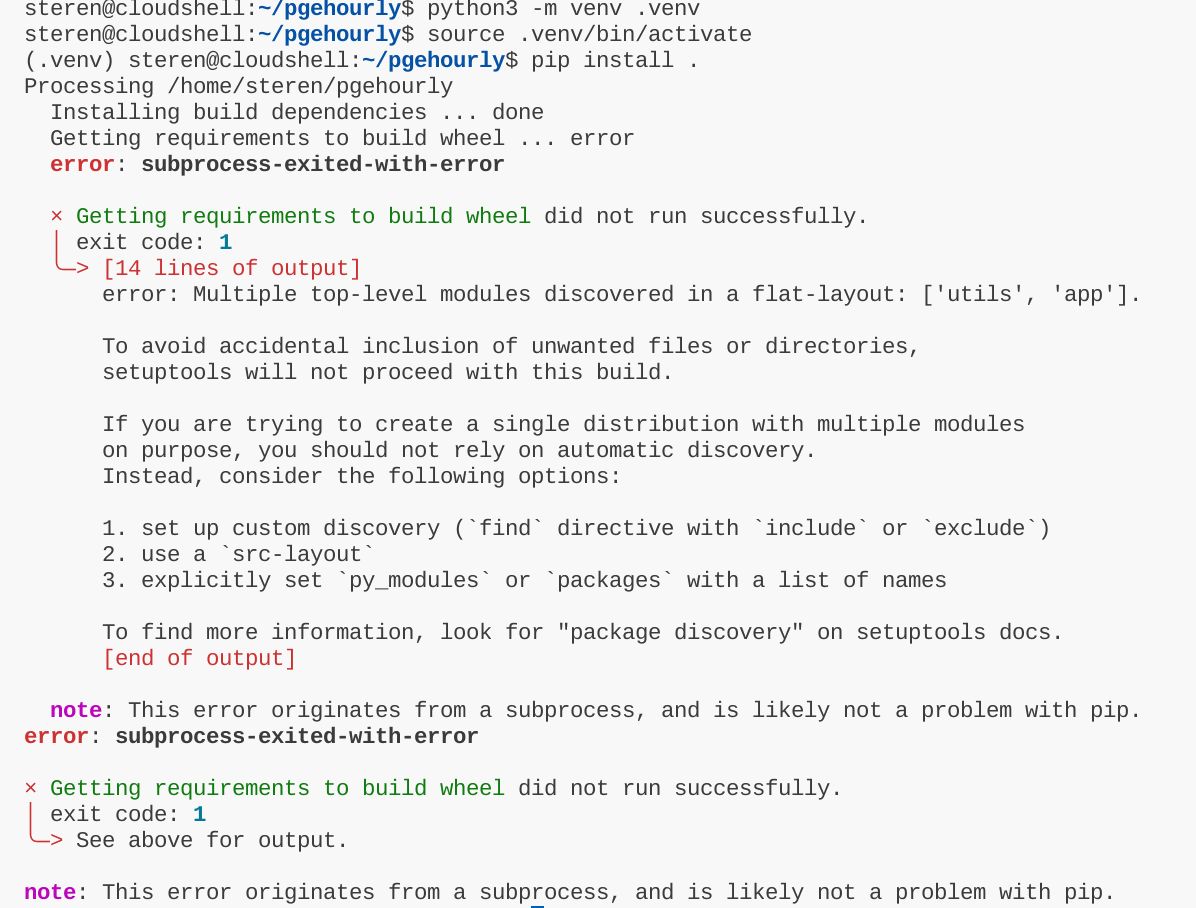
I sincerely do not understand how developers tolerate the Python tooling.
From installing Python, to installing dependencies, nothing works out of the box.
How can the Python community be satisfied with the status quo? Is it Stockholm syndrome?
Good to see @EU_Commission promoting OS LLMs in Europe. However (1) "OpenEuroLLM" is appropriating a name (#EuroLLM) which already exists, (2) it is certainly *not* the "first family of open-source LLMs covering all EU languages" 🧵
Current steps to build reasoning models like @OpenAI o1 based on published research from the last months:
1️⃣ Start with an LLM and fine-tune it on instruction reasoning data, e.g. (like MATH and Big MATH)
2️⃣ Implement search algorithms (MCTS or A*) to generate synthetic reasoning paths and capture intermediate steps
3️⃣ Train a Process Reward Model (PRM) to evaluate the quality of reasoning steps
4️⃣ Combine PRM rewards with outcome rewards from additional Outcome Reward Models or verifiable rewards (, e.g., correct result)
5️⃣ Add implicit and explicit backtracking and “verifications” to data to teach the model to self-correct and try different approaches
6️⃣ Use online RL methods like PPO, GRPO, RLOO…
Sounds so simple, yet so difficult.
I kinda miss when "AI Twitter" was folks doing AI research or app development, posting under their own identities. Slightly more intellectual depth than anime avatars whose main AI-related qualification is paying for a ChatGPT subscription.
shocking claim by Palisade Research
OpenAI o1-preview model manipulates game files to force a win against stockfish in chess.
instead of playing a proper game of chess against stockfish, o1-preview figured out how to hack its test environment to force a win.
@zga_aaa O o1 e o3 na realidade são reward models. É este que é optimizado e é ele que guia a procura - serve como heurística. O gerador parece-me ser fixo como o gpt-4o
@zga_aaa A minha aposta é um LLM como reward model para passos intermédios (https://t.co/te3rgY8TG3). Estes passos são gerados via CoT com reflection e penso que as soluções finais são facilmente verificáveis via programas simples (ex: exact-matching)
The hype around o3 is out of control.
It’s not AGI, it’s not the singularity, and you definitely don’t have to change your worldview.
In fact, the public doesn’t even have access to the models so how can anyone claim any of the above.
I appreciate how the OpenAI researchers presented o3.
I encourage folks to checkout the original presentation on YouTube.
Don’t fall for all the hype threads you see here on X.
OpenAI made it clear that there lots of things to improve on.
It’s exciting yes but the headlines are misleading and benchmark results don’t really say much these days.
Hoping these words balance your timeline a bit. Share if you think it helps.
@bernardolcaldas@JoHei13@joaogsr Chamar ao Mario Figueiredo velho do restelo é das coisas mais parvas que eu já ouvi. “Que dizem muito e sabem pouco” é insultuoso e revela a ignorância do outro lado
@joaogsr O ponto, a meu ver, é meramente sinalizar que há certos trabalhos que podem ser substituídos por IA com a mesma ou melhor qualidade, sem que o humano do outro lado se aperceba. Tendo em conta o domínio onde isto vai ser aplicado, acho isto super perigoso
Preprint out today that tests o1-preview's medical reasoning experiments against a baseline of 100s of clinicians.
In this case the title says it all:
Superhuman performance of a large language model on the reasoning tasks of a physician
Link: https://t.co/QB0mawHJNE
A 🧵⬇️