What is the next "big thing" in AI? What surprise does 2026 hold? If you ask me, I'd say 2026 is the year of historic breakthroughs in AI memory.
Every transformative computing revolution was unlocked by rethinking storage:
- PCs were interesting until SQL, then they became essential
- Mobile was entertaining until NoSQL, then they became essential
Watch out. Digital physics and information theory will collide with AI in a way you never imagined.
DM if your life's work is in rethinking information processing from its fundamentals.
We are way past code. Code is solved.
If you are not thinking about structures, architectures, and recursive systems of agents in 2026, you're probably behind.
Claude Code - Official Multi Agent Orchestration
This is a disabled feature, but through CC Mirror, I have been able to enable it
It is so simple, yet powerful and IMO beats every orchestration I've seen
There's no point building your own
Updating CC Mirror later today so that anyone can try this
https://t.co/SWrB9Pqy4X
@IntuitMachine Now this is a righteous topic. I'm not so sure the "Digital Hippocampus" is the right framing. But, I'm convinced the next big breakthrough in AI will be one of information storage, not learning, per say.
Well, 2025 is wrapping up and I've stopped counting how many lines of code I've generated. Between Memorial Day and Labor Day it was over 500k lines of code. Needless to say, software is moving at warp speed. Yet, we still have a ways to go to learn how to really leverage this new capability. The cost of proof of concepts has been driven down to zero. The cost of maintenance and shipping... it's unclear. At the moment, maintenance of shipped software is still unbounded.
If you can't see what an agent does, you can't improve it, you can't debug it, and you can't trust it.
It's crazy how many teams are building agents with no way to understand what they're doing.
Literally ZERO observability.
This is probably one of the first questions I ask every new team I meet:
Can you show me the traces of a few executions of your agents?
Nada. Zero. Nilch.
Large language models make bad decisions all the time.
Agents fail, and you won't realize it until somebody complains.
At a minimum, every agent you build should produce traces showing the full request flow, latency analysis, and system-level performance metrics.
This alone will surface 80% of operational issues.
But ideally, you can do something much better and capture all of the following:
• Model interactions
• Token usage
• Timing and performance metadata
• Event execution
If you want reliable agents, Observability is not optional.
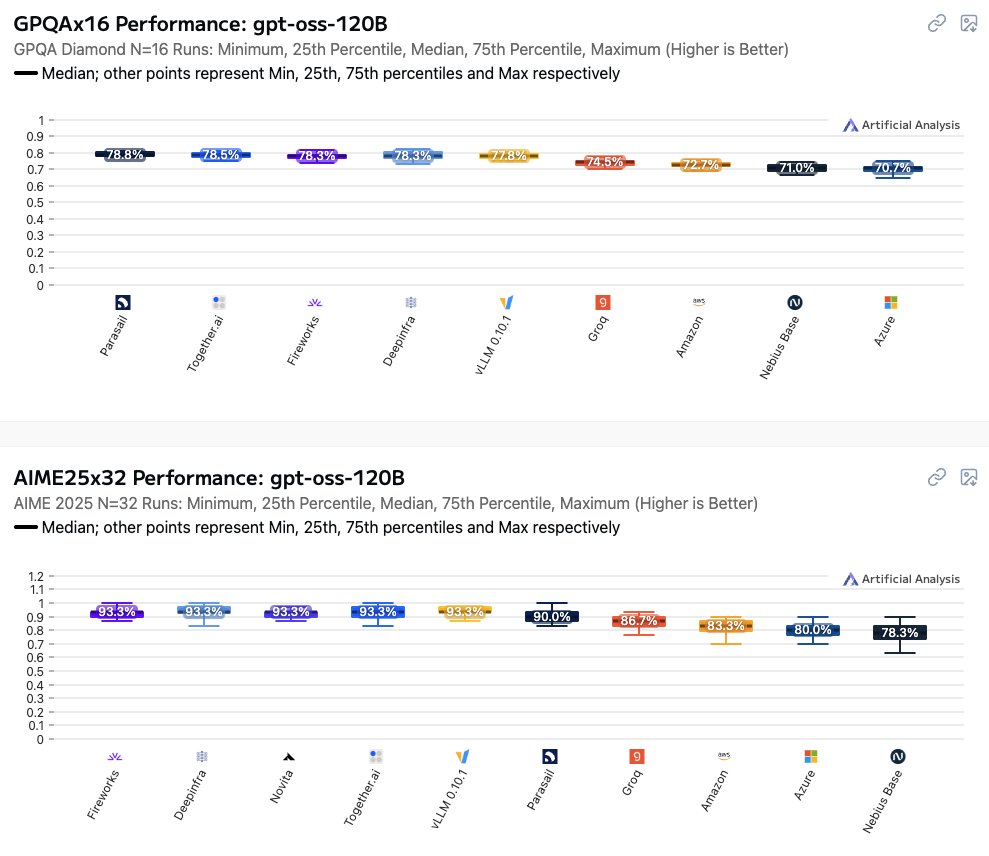
We've launched benchmarks of the accuracy of providers offering APIs for gpt-oss-120b
We compare providers by running GPQA Diamond 16 times, AIME25 32 times, and IFBench 8 times. We report the median score across these runs alongside minimum, 25th percentile, 75th percentile and maximum results. The number of repeats we run has been calibrated based on our confidence interval calculations.
This is the first version of our endpoint accuracy testing. We plan to iterate over time to ensure it provides the fairest possible basis for comparing providers’ accuracy.
Link to benchmarks below 👇
LEAKED: The ULTIMATE AI coding prompt collection…
7000+ lines of PURE GOLD from v0, Cursor, Lovable, Replit Agent, Windsurf & more...
These aren't just prompts...
They're the SECRET SAUCE that transforms any LLM into PROMPT ENGINEERS - almost one-shotting entire builds.
Upload these into your AI models and watch them code like senior developers instead of confused interns.
To STEAL these prompts:
Like + RT+ Comment "Gold" & I'll send over the drive.
PS: The AI coding wars just got transparent. This is where most prompt gurus get their prompts.
I spent 153 hours building an AI Content Engine for Agencies & SaaS Founders
It automates YouTube, LinkedIn, X, Facebook, TikTok, Instagram, & Newsletter content production pipeline
- Auto-posting across all major platforms
- AI-powered ideation for fresh content
- AI scripting for both long-form and short-form content
This system is easily worth $15K, but today it’s FREE
👉 RT + Like & Comment "content" and I’ll DM the JSON file
No opt-in, no BS
(Must be following)
I just created a step-by-step guide to help you self-host n8n
This is the exact setup we use to build unlimited AI agents without paying $20K/year on tools like Zapier
Want this premium guide for FREE?
👉 RT + Like & Comment “free” and I’ll DM it to you
No sign-in, no BS
(Must be following)
Want to build one? TLDR
Best model with impeccable context throughout a conversation is hands down grok3.
Most promising line of thinking longer term for a more durable solution… Model Context Protocol (proposed by Anthropic). Yet still underwhelming as is. But the need to have fluid model context decoupled from model is on point.
Model with longest context that is fit for prime time?
Meanwhile, despite myriads of solutions for turning services and files into knowledge sources for models, I have yet to find one that stands out. Data to vector. And semantic search has yet to be magical for me.
Folks don’t take the time to thoughtfully pre-reason about the data and heavily annotate it prior to embedding.
Moreover, done well, this would be fluid annotations that are conversation specific.
Core parts of the puzzle:
- data tools: access to docs and data
- service tools: access to chat and other services
- pipelines for declarative access to tools for both local preview and inclusion into chat as well as vector db
- context enrichment engine which makes sure pipelines take time to properly inspect, frame, qualify, enrich data from tools
- observably loop - outer loop to verify and optimize components of inner loop with hybrid human and llm-as-judge pattern
Dear @tedcruz
I speak for ALL of your Texas constituents including myself.
We are demanding you support Rick Scott for Senate Leadership.
Thank you,
ALL Texans
🚨Repost if you want Ted to see this.