This is a foundational publication which taught me how to optimize code for speed on modern computers. CPUs are bottlenecked by slow memory access most of the time. Optimize the code for memory access and get >10x performance improvements.
I've read this publication ~19 years ago at https://t.co/oT6plLunJu - https://t.co/TaAW7GRdre
Missed our latest Virtual Meetup? 👀
Check out this short demo and see how you can now download massive logs in CSV format directly from VictoriaLogs without crashing your browser. 🚀
https://t.co/0lfyr7Lkym
#VictoriaLogs#Observability#LogManagement#OpenSource#DevOps #Kubernetes
Multi-tier observability is a practical way to handle diverse workloads without forcing every signal into the same storage and query path.
🔍 Multi-tier #observability matches the right setup to each workload.
⤴️ It helps balance performance, cost, and scalability.
📐 One size doesn’t fit every observability need.
When a noisy system overloads your observability stack, business-critical teams are most affected: their alarms fire with a lag or not at all. In general, the observability experience degrades when the backend is under heavy load, forcing operations to make compromises such as disconnecting non-critical systems, filtering data, or reducing retention.
If you are in this situation and your company expects more growth, adding more capacity isn’t likely to be the answer. This is the point where going multi-tier starts to make sense.
Read now 👇
https://t.co/xZnrsENb3R
The code is the truth, but it is not the whole truth.
A repository is the truth, but it is not the architecture: it represents only the development view of an architecture.
Therefore, by placing architectural description records as artifacts within a repository, you have a wonderful strange loop: the architecture is represented by multiple views, one of which contains a description of the entire architecture, including itself.
I've seen some confusion online on how to run llama.cpp with MTP (Multi-token prediction) in the simplest way possible.
ICYMI, MTP is a new flavor of speculative decoding built-in to the model itself, that ~2x your tokens per sec for most use cases.
2x generation speed = Truly a game changer. 🔥
How to run it?
brew upgrade llama.cpp
# or you might need to install from source until build 9200 is in your package manager:
brew install llama.cpp --HEAD
Then pick either the Dense 27B or the 35B A3B MoE.
Personally I tend to stick to the Dense model where I achieve ~30 tok/sec on my machine. The MoE is of course way faster at an impressive ~100 tok/sec on my machine. Truly rapid. ⚡️
In both cases you probably want 48GB or better 64GB RAM or VRAM, though 36GB might work with more strongly-quantized versions.
# Dense:
llama-server -hf ggml-org/Qwen3.6-27B-MTP-GGUF --spec-type draft-mtp --spec-draft-n-max 2
# MoE:
llama-server -hf ggml-org/Qwen3.6-35B-A3B-MTP-GGUF --spec-type draft-mtp --spec-draft-n-max 3
Enjoy!
Cloudflare's security team spent the last few weeks testing Anthropic's Mythos against fifty of our own repositories. What we learned about offensive AI, why faster patching is the wrong reaction, and what the architecture around vulnerabilities has to look like next. https://t.co/RSrRtIhgaV
Important to know that Postgres/MySQL on local SSD is *the* best way to get great performance.
The reason it could get *even faster* boils down to abstraction boundaries.
SSDs are built to be workload agnostic. They have their own controllers and garbage collectors meant to balance performance of many different I/O patterns.
DBMS are written to support arbitrary backing I/O devices: SSD, HDD, or even a remote storage system. It's good that they're written to be broadly performant!
The point of the paper was that, if you're willing to build something that specifically targets local SSDs (and even specific models of local SSDs) you can optimize the full DBMS -> OS -> hardware stack for the exact characteristics of a workload and hardware specifications.
This is a classic tradeoff. You can usually get better performance as you narrow scope for specific hardware, architectures, etc. Maintainers of OSS must walk a careful balance of optimizing for performance while also maintaining wide compatibility.
For the curious-minded, I wrote an interactive article on the history of I/O devices, and how that interplays with database performance:
https://t.co/D6xdZ4ijol
Saturday Go deep dive: the `select` statement
It looks like a switch, but it's really two features in one: the compiler rewrites the easy shapes away, and the runtime handles the rest in a single function called `selectgo`.
I'll explait it on my Monday's blog post!
Want it directly in your inbox? Subscribe here: https://t.co/vpnOuQRpUO
#golang #go #runtime
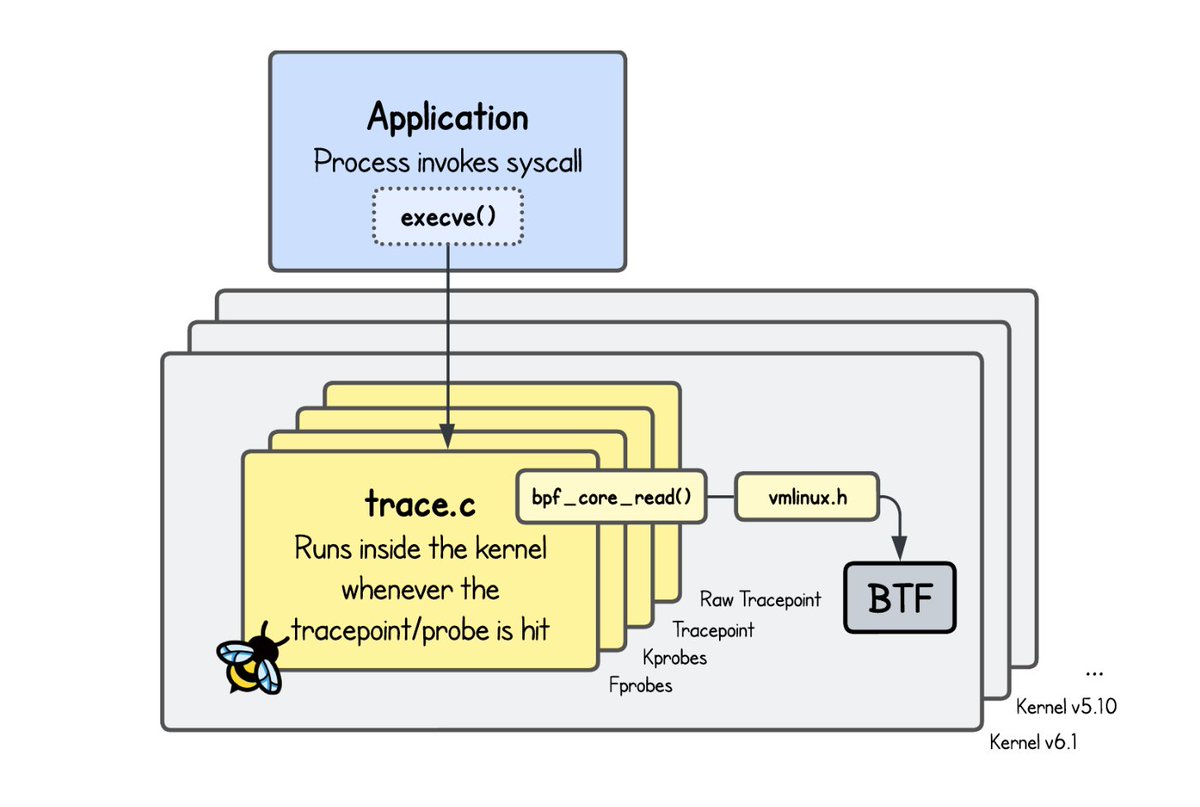
eBPF is much easier to understand when you stop treating it as magic and start building small, working programs with it.
Teodor Podobnik has been publishing a hands-on eBPF series on iximiuz Labs, with a strong focus on networking.
The tutorials start from the fundamentals - your first eBPF program, maps, the verifier, bpftool, portability, event delivery, and XDP basics — and then move into practical network programming projects:
- Implementing traffic rate limiting with eBPF/XDP
- Building an IP range firewall with LPM trie maps
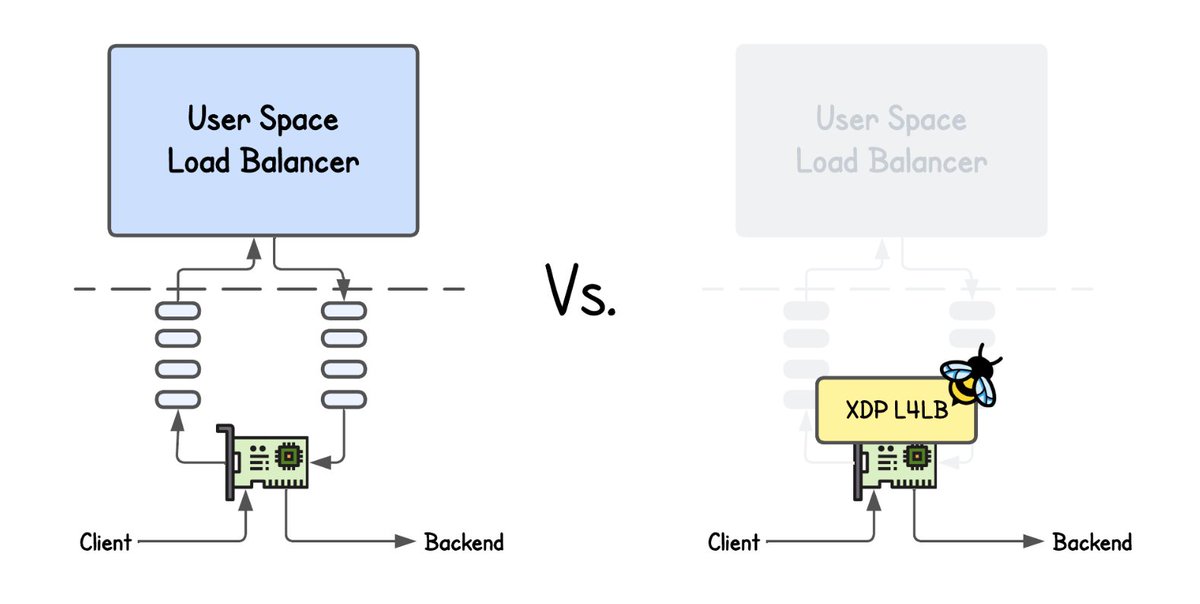
- Writing a NAT-based L4 load balancer
- Building Layer 2 and IP-in-IP DSR load balancers
- Adding round-robin and weighted backend selection
- Transparently redirecting ingress and egress traffic through Envoy
- Accelerating socket-to-socket traffic paths with eBPF
What I like about this series is that it doesn't just tell what eBPF can do. It shows how the pieces fit together in real Linux networking scenarios: packet parsing, connection tracking, IP/MAC rewriting, socket hooks, and more.
If you've been meaning to learn eBPF for networking, this is easily the best collection of hands-on learning materials on the entire Internet:
https://t.co/Ya0dHYQwGc
Porcupine linearizability tests & Antithesis are my heroes right now
It's REALLY easy to build a naive distributed system that you _think_ works. Support correcting data manually on support calls
Whether a DB or multi-API interaction. It's never been easier to test anomalies
New article: Inside ZFS 🔥
A walk through the three layers (SPA, DMU, DSL), the 128-byte block pointer that makes the whole pool a Merkle tree, the uberblock ring, and why snapshots are O(1).
👉 https://t.co/6IJMFnr5K4
#ZFS#Filesystems
every tech executive is talking about making it so anyone on the team can ship code
this means engineers focus on guardrails, patterns, etc to allow for this to happen safely
but this isn't new! this has always been the job of the senior people on the team, make the less experienced people more productive
and you do this by being really good at designing code, and you're gonna have to be really really really good to allow your marketing team to ship changes without things breaking