DX12 Bindless Plugin for Unity3D is now open source, and you can use it in your projects! Can be useful for writing a custom GPU Driven Renderer. (github below)
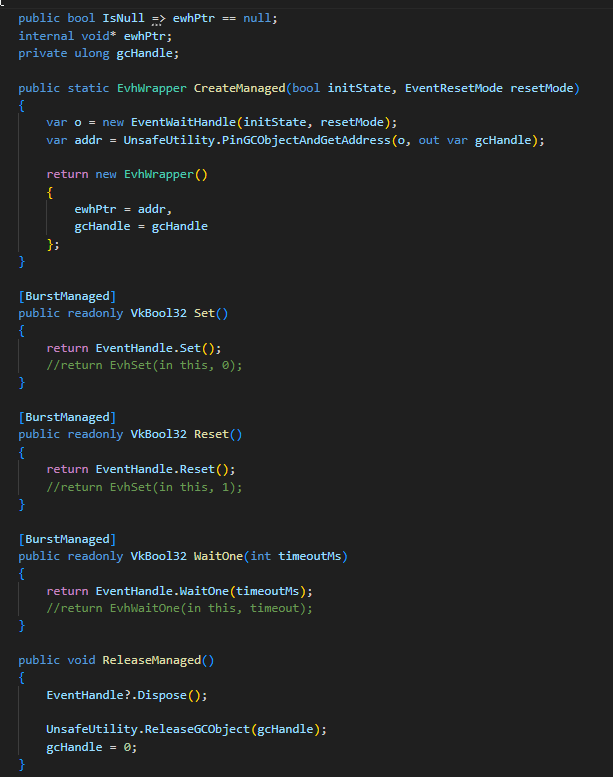
@s4schoener I do that quite a lot, instead of using those handles I prefer to make an ManagedField struct with the same logic + pinned handle, because in that case it's possible to call a C# callback accepting a reference.
One of the prime cases were calling EventWaitHandle from Burst.
That’s true. I’ve asked Josh Peterson if they will remove compacting from GC, and he atm told no. I think I would’ve just remove the compacting entirely and it’s quite easy to do in coreclr.
On IL2CPP perf though I don’t think IL2CPP will beat coreclr nativeaot in all the circumstances
@SebAaltonen Interesting, last time Ive checked structured buffers in Compute pipeline they were a little bit faster. Probably they are using a different path in compute. Interesting why is that.
@SoftEngineer Ah, Ive got it. I did something similar for Unity implementing NICE filter on gpu. Constructing a little smaller kernel and take max(currentMip-3, 0) as a source
Продолжая тему взвешенного подхода к использованию AI. Наткнулся тут на интересную заметку - "Breaking the Spell of Vibe Coding". Довольно интересный текст о рисках бездумного вайбкодинга. Всем разработчикам (и не только им, конечно) известно понятие flow state ("состояние потока"), то самое, когда хорошим программистам удаётся "своротить горы". Автор статьи рассматривает вариант этого состояния - dark flow, типа того, что испытывает лудоман, взаимодействуя с игровым автоматом, и утверждает, то же самое человек испытывает при вайбкодинге - когда ты вообще не смотришь на результирующий код, но крайне увлечён реализацией своей наверняка великой идеи. В результате такой работы получается "дом на песке", некая конструкция без внятной архитектуры, с кучей воркэраундов и багов, разваливающаяся под собственным весом по мере роста объёма кода. Примерно тот же результат, если вдуматься, что и у лудомана с голой жопой и коллекторами у входной двери.
Думается мне, что что-то в этом есть.
@James_M_South Getting a better performance for drawing is usually simple, what’s complicated is getting results back without a huge delay from GPU while also maintaining the frontend similar to CPU
@unitycoder_com Yeah funny thing they are still using cpu to submit drawcalls, and only sub cull draw calls with occlusion culling. Sorting/filtering is basically impossible to get done on gpu with the current API design. At least when I checked it (~half year ago)