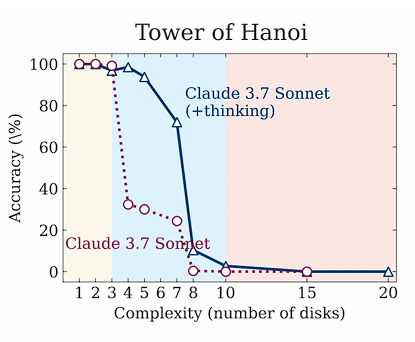
A few more observations after replicating the Tower of Hanoi game with their exact prompts:
- You need AT LEAST 2^N - 1 moves and the output format requires 10 tokens per move + some constant stuff.
- Furthermore the output limit for Sonnet 3.7 is 128k, DeepSeek R1 64K, and o3-mini 100k tokens. This includes the reasoning tokens they use before outputting their final answer!
- all models will have 0 accuracy with more than 13 disks simply because they can not output that much!
- the max solvable sizes WITHOUT ANY ROOM FOR REASONING (floor(log2(output_limit/10)))
DeepSeek: 12 disks
Sonnet 3.7 and o3-mini: 13 disks
- If you actually look at the output of the models you will see that they don't even reason about the problem if it gets too large:
"Due to the large number of moves, I'll explain the solution approach rather than listing all 32,767 moves individually"
- At least for Sonnet it doesn't try to reason through the problem once it's above ~7 disks. It will state what the problem and the algorithm to solve it and then output its solution without even thinking about individual steps.
- it's also interesting to look at the models as having a X% chance of picking the correct token at each move
- even with a 99.99% probability the models will eventually make an error simply because of the exponentially growing problem size
We’re way more patient in training human employees than AI employees.
We will spend weeks onboarding a human employee and giving slow detailed feedback. But we won’t spend just a couple of hours playing around with the prompt that might enable the LLM to do the exact same job, but more reliably and quickly than any human.
The first innings of AGI development was Mathematics (linalg + calc)
The second was Computer Science (parallelization, tensor ops)
The final third may turn out to be Philosophy
Thoughts about o3: I'll skip the obvious part (extraordinary reasoning, FrontierMath is insanely hard, etc). I think the essence of o3 is about *relaxing a single-point RL super intelligence* to cover more points in the space of useful problems.
The world of AI is no stranger to RL achieving god-level stunts.
AlphaGo was a super intelligence. It beats the world champion in Go - well above 99.999% of regular players.
AlphaStar was a super intelligence. It bests some of the greatest e-sport champion teams on StarCraft.
Boston Dynamics e-Atlas was a super intelligence. It performs perfect backflips. Most human brains don't know how to send such sophisticated control signals to their limbs.
Similar statement can be made for AIME, SWE-Bench, and FrontierMath - they are like Go, which requires exceptional domain expertise above 99.99....% of average people. o3 is a super intelligence when operating in these domains.
The key difference is that AlphaGo uses RL to optimize for a simple, almost trivially defined reward function: winning the game gives 1, losing gives 0. Learning reward functions for sophisticated math and software engineering are much harder. o3 made a breakthrough in solving the reward problem, for the domains that OpenAI prioritizes. It is no longer an RL specialist for single-point task, but an RL specialist for a bigger set of useful tasks.
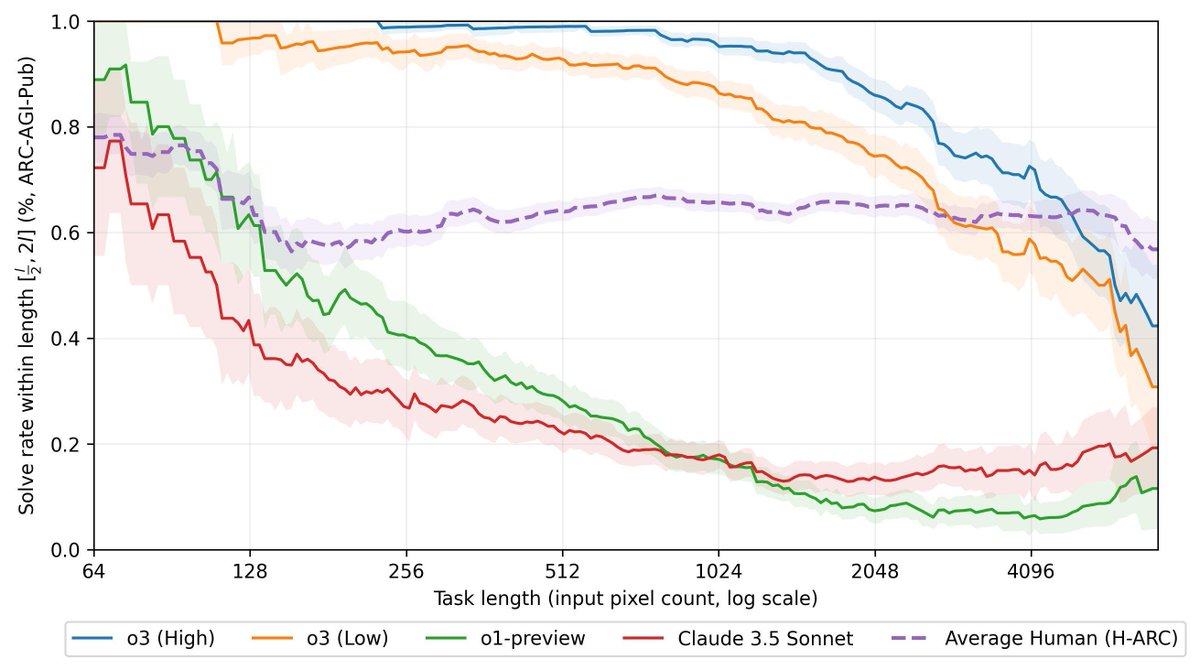
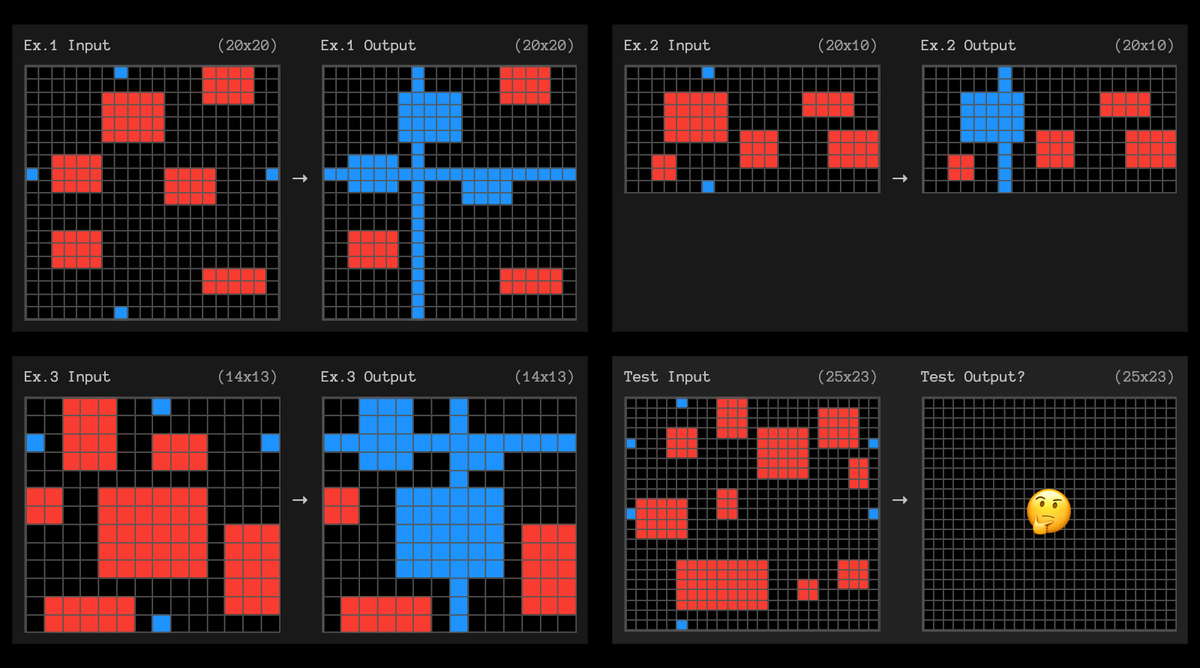
Yet o3's reward engineering could not cover ALL distribution of human cognition. This is why we are still cursed by Moravec's paradox. o3 can wow the Fields Medalists, but still fail to solve some 5-yr-old puzzles like the one below. I am not at all surprised by this cognitive dissonance, just like we wouldn't expect AlphaGo to win Poker games.
Huge milestone. Clear roadmap. More to do.
also: the model we used for all of our o3 evals is fully general; a subset of the arc-agi public training set was a tiny fraction of the broader o3 train distribution, and we didn’t do any additional domain-specific fine-tuning on the final checkpoint
o3 and o3-mini are my favorite models ever.
o3 essentially solves AIME (>90%), GPQA (~90%), ARC-AGI (~90%), and it gets 1/4th of the Frontier Maths.
To understand how insane 25% on Frontier Maths is, see this quote by Tim Gowers.
The sparks are intensifying ...
o3, our latest reasoning model, is a breakthrough, with a step function improvement on our hardest benchmarks. we are starting safety testing & red teaming now.
So, is this AGI?
While the new model is very impressive and represents a big milestone on the way towards AGI, I don't believe this is AGI -- there's still a fair number of very easy ARC-AGI-1 tasks that o3 can't solve, and we have early indications that ARC-AGI-2 will remain extremely challenging for o3.
This shows that it's still feasible to create unsaturated, interesting benchmarks that are easy for humans, yet impossible for AI -- without involving specialist knowledge. We will have AGI when creating such evals becomes outright impossible.
Everything you love about generative models — now powered by real physics!
Announcing the Genesis project — after a 24-month large-scale research collaboration involving over 20 research labs — a generative physics engine able to generate 4D dynamical worlds powered by a physics simulation platform designed for general-purpose robotics and physical AI applications.
Genesis's physics engine is developed in pure Python, while being 10-80x faster than existing GPU-accelerated stacks like Isaac Gym and MJX. It delivers a simulation speed ~430,000 faster than in real-time, and takes only 26 seconds to train a robotic locomotion policy transferrable to the real world on a single RTX4090 (see tutorial: https://t.co/bEkIlCKqdf).
The Genesis physics engine and simulation platform is fully open source at https://t.co/DhBv7NdyqH. We'll gradually roll out access to our generative framework in the near future.
Genesis implements a unified simulation framework all from scratch, integrating a wide spectrum of state-of-the-art physics solvers, allowing simulation of the whole physical world in a virtual realm with the highest realism.
We aim to build a universal data engine that leverages an upper-level generative framework to autonomously create physical worlds, together with various modes of data, including environments, camera motions, robotic task proposals, reward functions, robot policies, character motions, fully interactive 3D scenes, open-world articulated assets, and more, aiming towards fully automated data generation for robotics, physical AI and other applications.
Open Source Code: https://t.co/DhBv7NdyqH
Project webpage: https://t.co/SBNyhFB0yn
Documentation: https://t.co/3yuBoaealV
1/n
I just cannot make myself code anymore. It feels too slow and requires too much energy. My brain refuses to concentrate and demands using an LLM shortcut. Do you feel something like this?
OpenAI CFO Sarah Friar says the company is leaving the door open to a $2000/month subscription to its AI product which could serve as a "replacement" to hiring humans due to its PhD-level intelligence
OpenAI has released ZERO features for developers in the last 7 days
They went from open source to closed source to no API access AND give us $200 to access our top LLM!!
EXTREMELY ALARMING!
New research collaboration: “Best-of-N Jailbreaking”.
We found a simple, general-purpose method that jailbreaks (bypasses the safety features of) frontier AI models, and that works across text, vision, and audio.
🎉 DeepSeek-VL2 is here! Our next-gen vision-language model enters the MoE era.
🤖 DeepSeek-MoE arch + dynamic image tilling
⚡ 3B/16B/27B sizes for flexible use
🏆 Outstanding performance across all benchmarks
🧵 1/n
📢 NEW LAUNCHES📢
1. ✋Rolling out: "Join" an audio overview+engage directly with the AI hosts
2. 😎New UI optimized for managing+generating new content based on your sources
3. 💪NotebookLM Plus: a premium version for businesses, teams & enterprises
Learn more ⬇️
https://t.co/1depPUsvpS