Scaling has done wonders for deep learning, but for a long time it failed in on-policy RL... until now! We show that when done appropriately, scaling leads to state-of-the-art results in a variety of continuous control tasks🔥
Introducing BRO: Bigger, Regularized, Optimistic! 🧵
A few years ago, learning robot learning meant stitching together dozens of papers and courses — with no clear path from the basics to what state-of-the-art systems actually do.
This was one of the motivations behind creating @ETH's course "Robot Learning: From Fundamentals to Foundation Models", to provide a structured path from first principles all the way to modern foundation models for robotics.
I strongly believe that education should be accessible to everyone, so I have made all lecture recordings publicly available on YouTube.
Creating this course was one of the most challenging projects I have taken on. It was my first time designing and teaching an entire curriculum from scratch, while simultaneously working full-time in industry. On top of that, the course proved to be more popular than expected and we had to scale it to almost 300 students, which was only possible thanks to an amazing team of TAs. Looking back, it was an absolute privilege to teach this class and an incredibly rewarding experience.
If you are getting into robot learning, this is the starting point I wish I had.
📚 Main lectures:
https://t.co/r1PpQASaJg
🎤 Guest lectures:
https://t.co/nh5Rm2P2Lz
🌐 Course website: https://t.co/DoQUYy3MjB
🚀 Excited to share REPPO, a new on-policy RL agent!
TL;DR: Replace PPO with REPPO for fewer hyperparameter headaches and more robust training.
REPPO, led by @c_voelcker, will be presented at #ICLR2026. How does it work? 🧵👇
Growing as an RL researcher---like many others---my work mostly following the following template:
1) formulate the right problem setting
2) come up with an algorithm that solves it
3) show that it works in simulation like (the amazing!) MuJoCo.
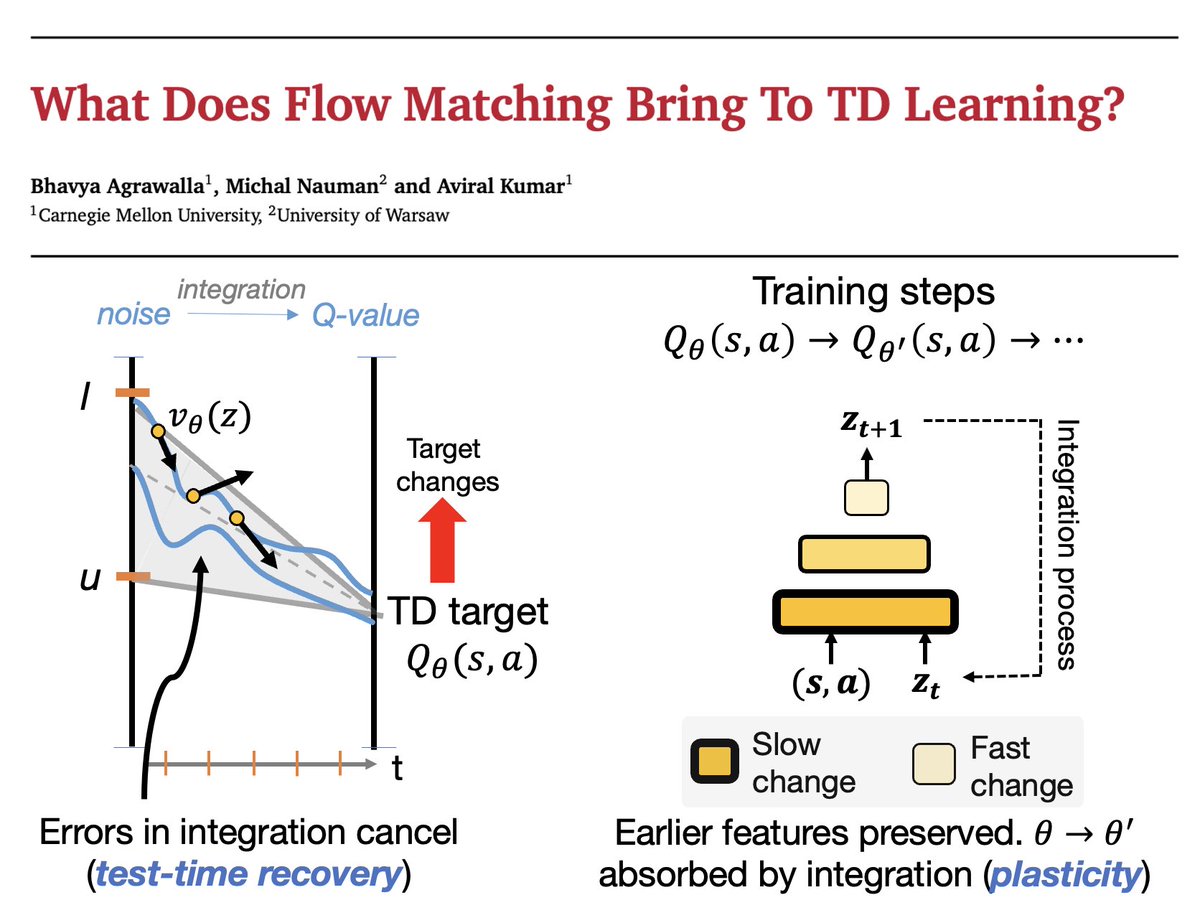
We have now released the code and wandbs for "What Does Flow-Matching Bring To TD Learning?" !
Code -- https://t.co/EUWSwRk0Q3
Wandbs -- https://t.co/G9zFIarEMX
Feel free to reach out if you have any questions or issues!
https://t.co/hxqq3fkI4g
Check out our new paper🔥
Here, we take a deeper look at why flow-matching works so well for modelling Q-values in RL. Surprisingly, we find that the iterative nature of flow matching improves plasticity of the learner, making it a great fit for value learning and RL in general
🚨🚨 New paper on flow-matching value functions
Last year, we showed training RL value functions with a flow-matching loss achieved SOTA results.
But why does it work? And what could it possibly tell us about other things that have nothing to do with VFs or even RL?
Short answer: iterative compute used correctly can address feature plasticity in continual learning! 🧵⬇️
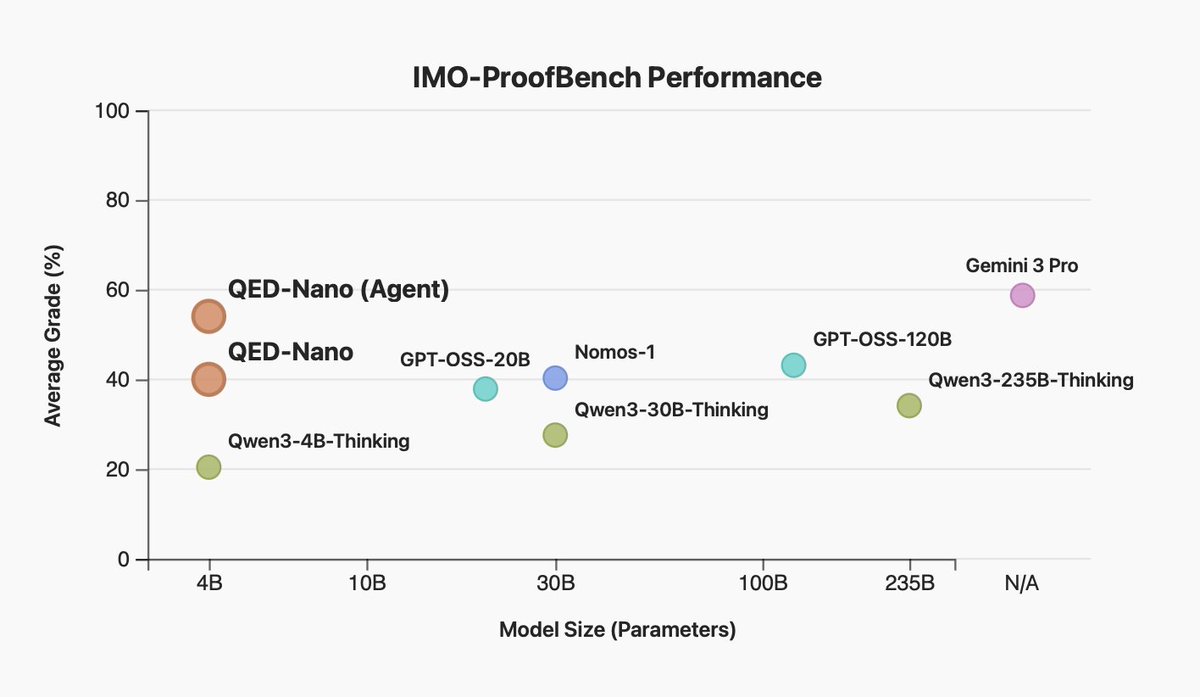
Can just a 4B model solve IMO-level proof problems at the level of much stronger LLMs like Gemini 3 Pro? Yes, if you can train the LLM to scale test-time compute well!
We're very excited to release our 4B model "QED-Nano", built via an awesome open collab! Details below🧵⬇️
🚀 Excited to share REPPO, a new on-policy RL agent!
TL;DR: Replace PPO with REPPO for fewer hyperparameter headaches and more robust training.
REPPO, led by @c_voelcker, will be presented at #ICLR2026. How does it work? 🧵👇
@ID_AA_Carmack@AgrawallaBhavya An interesting idiosyncrasy is that, due to the non-stationarity of Q-values, the scale of the noise used during flow matters much more in standard flow matching with stationary labels - we tried to show this in Figure 2
@ID_AA_Carmack@AgrawallaBhavya We used the 4-layer architecture to make it more "comparable" to architectures used in the baseline algorithms. While we did not study this, I would guess that a shallower, wider network would work equally well. @AgrawallaBhavya thoughts?
@ID_AA_Carmack Thanks for sharing our work! The intermediate supervision offered by flow-matching indeed seems to have a good effect on the training stability of TD learning - we are currently working on a follow-up that will go more in-depth on what is happening under the hood : )
llms sometimes lie even when they know the truth. activation steering can fix this, but where you intervene matters.
we introduce gaussian depth scheduling: improves honesty in all 7 models (up to +17.2 points), training-free and model-agnostic.
see: https://t.co/zhDHwgF1qM
Multi-task RL can be highly sample-efficient and when done right, it unlocks LLM-style transfer and fine-tuning.
We’re excited to introduce BRC, a simple recipe for multi-task RL that outperforms SOTA single-task agents while using less compute (!)
@codewithimanshu I’m convinced that MT is the way to go. It’s also already changed my day-to-day RL workflow - I recently generated an offline dataset with a MT setup instead of running a bunch of separate single-task models thus saving a lot of compute.
Multi-task RL can be highly sample-efficient and when done right, it unlocks LLM-style transfer and fine-tuning.
We’re excited to introduce BRC, a simple recipe for multi-task RL that outperforms SOTA single-task agents while using less compute (!)
When we released HumanoidBench, I was excited about the prospect of a benchmark using a single embodiment for many different tasks. With BRC, we show that learning across such diverse tasks is significantly more effective than training on each task separately.
Check out our work, led by @mic_nau on scaling up multi-task RL using some simple, but very effective design choices!
He will present this work at NeurIPS -- don't lose an opportunity to talk to him!!! 👇
I’ll be presenting this work next week at @NeurIPSConf - reach out to me if you’d like to chat or meet in San Diego!
This project was done during my visit to BAIR Berkeley. Huge thanks to my amazing coauthors: @pabbeel@aviral_kumar2@marek_a_cygan@carlo_sferrazza