INSTEAD OF WATCHING AN HOUR OF NETFLIX TONIGHT.
This 60-minute Cambridge lecture by Demis Hassabis will teach you more about the future of AI than most people will learn in the next 5 years.
Bookmark it and give it an hour, no matter what.
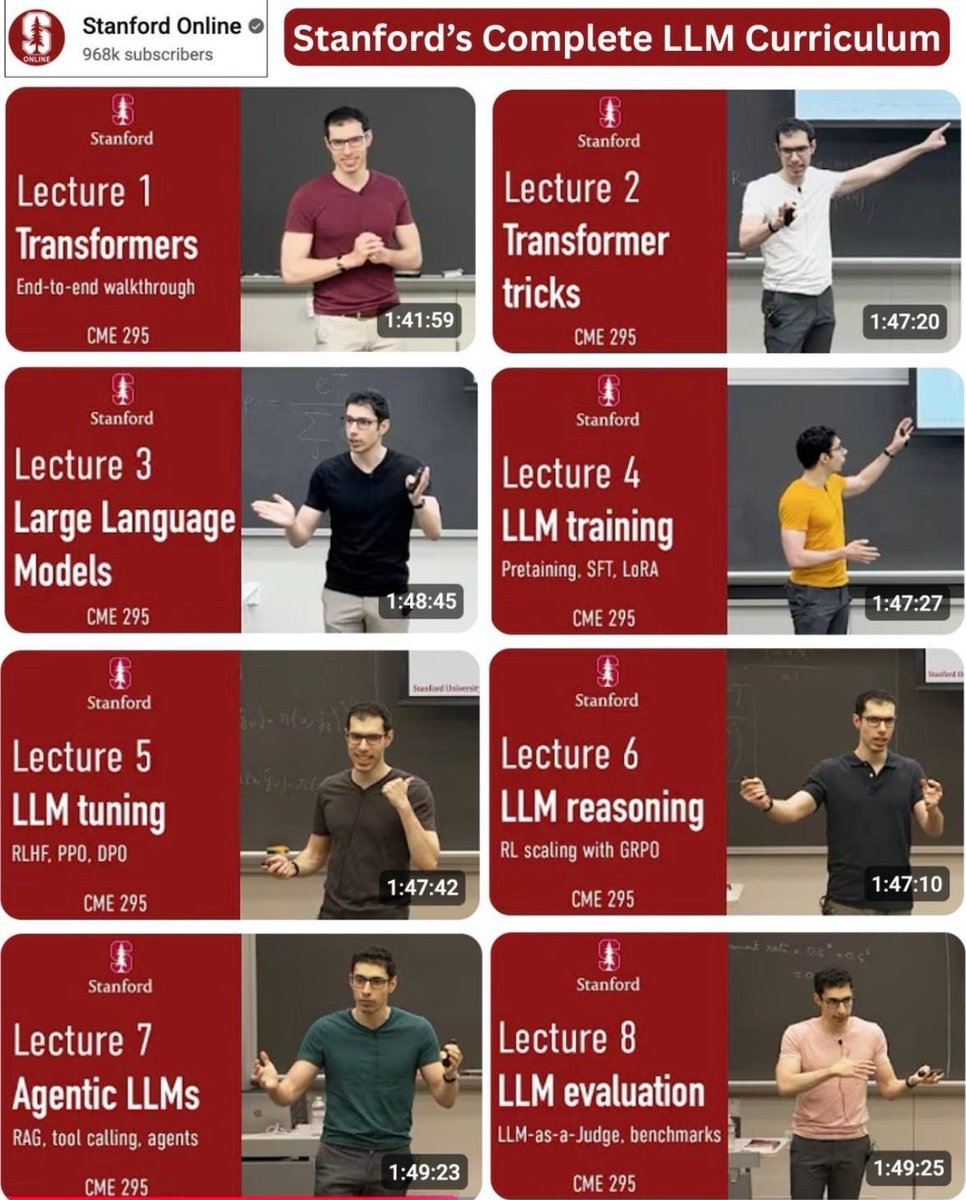
Instead of watching an hour of Netflix, watch this 2 hour hour Stanford lecture will teach you more about how LLMs like ChatGPT and Claude are built than most people working at top AI companies learn in their entire careers.
Anthropic pays engineers $750,000+ a year to understand how LLMs work.
Stanford just put a 2 hour lecture that covers 80% of it for FREE.
Bookmark this. Give it 2 hours today.
It might be the highest ROI thing you do this month:
> I don’t understand why people are still paying in dollars to learn LLMs.
> these 9 lectures from Stanford are a pure goldmine for anyone wanting to understand LLMs in depth.
step-by-step LLM Engineering Projects
each project = one concept learned the hard (i.e. real) way
Tokenization & Embeddings
> build byte-pair encoder + train your own subword vocab
> write a “token visualizer” to map words/chunks to IDs
> one-hot vs learned-embedding: plot cosine distances
Positional Embeddings
> classic sinusoidal vs learned vs RoPE vs ALiBi: demo all four
> animate a toy sequence being “position-encoded” in 3D
> ablate positions—watch attention collapse
Self-Attention & Multihead Attention
> hand-wire dot-product attention for one token
> scale to multi-head, plot per-head weight heatmaps
> mask out future tokens, verify causal property
transformers, QKV, & stacking
> stack the Attention implementations with LayerNorm and residuals → single-block transformer
> generalize: n-block “mini-former” on toy data
> dissect Q, K, V: swap them, break them, see what explodes
Sampling Parameters: temp/top-k/top-p
> code a sampler dashboard — interactively tune temp/k/p and sample outputs
> plot entropy vs output diversity as you sweep params
> nuke temp=0 (argmax): watch repetition
KV Cache (Fast Inference)
> record & reuse KV states; measure speedup vs no-cache
> build a “cache hit/miss” visualizer for token streams
> profile cache memory cost for long vs short sequences
Long-Context Tricks: Infini-Attention / Sliding Window
> implement sliding window attention; measure loss on long docs
> benchmark “memory-efficient” (recompute, flash) variants
> plot perplexity vs context length; find context collapse point
Mixture of Experts (MoE)
> code a 2-expert router layer; route tokens dynamically
> plot expert utilization histograms over dataset
> simulate sparse/dense swaps; measure FLOP savings
Grouped Query Attention
> convert your mini-former to grouped query layout
> measure speed vs vanilla multi-head on large batch
> ablate number of groups, plot latency
Normalization & Activations
> hand-implement LayerNorm, RMSNorm, SwiGLU, GELU
> ablate each—what happens to train/test loss?
> plot activation distributions layerwise
Pretraining Objectives
> train masked LM vs causal LM vs prefix LM on toy text
> plot loss curves; compare which learns “English” faster
> generate samples from each — note quirks
Finetuning vs Instruction Tuning vs RLHF
> fine-tune on a small custom dataset
> instruction-tune by prepending tasks (“Summarize: ...”)
> RLHF: hack a reward model, use PPO for 10 steps, plot reward
Scaling Laws & Model Capacity
> train tiny, small, medium models — plot loss vs size
> benchmark wall-clock time, VRAM, throughput
> extrapolate scaling curve — how “dumb” can you go?
Quantization
> code PTQ & QAT; export to GGUF/AWQ; plot accuracy drop
Inference/Training Stacks:
> port a model from HuggingFace to Deepspeed, vLLM, ExLlama
> profile throughput, VRAM, latency across all three
Synthetic Data
> generate toy data, add noise, dedupe, create eval splits
> visualize model learning curves on real vs synth
each project = one core insight. build. plot. break. repeat.
> don’t get stuck too long in theory
> code, debug, ablate, even meme your graphs lol
> finish each and post what you learned
your future self will thank you later
🏆📚This 200-Page LLM Paper Is a 𝗚𝗼𝗹𝗱𝗺𝗶𝗻𝗲 — and it’ll save you months
𝗣𝗿𝗼𝗺𝗽𝘁𝗶𝗻𝗴, 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴, 𝗮𝗹𝗶𝗴𝗻𝗺𝗲𝗻𝘁 — finally crystal clear.
If you don’t have time to read all 200+ pages, here are the most valuable 𝘁𝗮𝗸𝗲𝗮𝘄𝗮𝘆𝘀 ↓
》 𝗣𝗿𝗲-𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴:
How AI Gets Smart Before It Gets Useful Before an LLM can generate anything meaningful, it must pre-train—absorbing patterns from vast datasets. This paper breaks it down:
✸ Unsupervised, Supervised, and Self-Supervised Pre-training – Why AI learns better with less human labeling.
✸ Encoder vs. Decoder vs. Encoder-Decoder Models – The three fundamental architectures and when to use them.
✸ BERT & Transformers – How they rewrote the rules of AI understanding.
》 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝘃𝗲 𝗠𝗼𝗱𝗲𝗹𝘀:
Where AI Stops Memorizing and Starts Creating
Pre-training gives LLMs knowledge. Generative models give them a voice.
✸ Decoder-Only Transformers (GPT-style models) – The backbone of AI creativity.
✸ Training & Fine-tuning LLMs – How models evolve from generalists to specialists.
✸ Alignment & Safety – Why raw AI outputs need guardrails (and how RLHF fixes it).
》𝗣𝗿𝗼𝗺𝗽𝘁 𝗘𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴:
The Skill That Separates AI Users From AI Builders
If you’re not prompting correctly, you’re missing out on 90% of an LLM’s potential. This paper covers:
✸ In-Context Learning – Teaching AI on the fly without retraining.
✸ Chain of Thought & Self-Refinement – Making AI reason instead of regurgitate.
✸ RAG & Tool Use – Giving LLMs external memory for better accuracy.
》 𝗔𝗜 𝗔𝗹𝗶𝗴𝗻𝗺𝗲𝗻𝘁:
Teaching AI to Work for Humans (Not Against Them)
One of the biggest challenges in AI is getting it to follow human intent. The paper breaks down:
✸ Instruction Fine-Tuning – How models learn from curated data.
✸ Reinforcement Learning with Human Feedback (RLHF) – Why AI listens to your preferences.
✸ Inference-Time Alignment – Tweaking responses without retraining the whole model.
☆ 200-page paper: https://t.co/ml3bgZrlvS
≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣≣
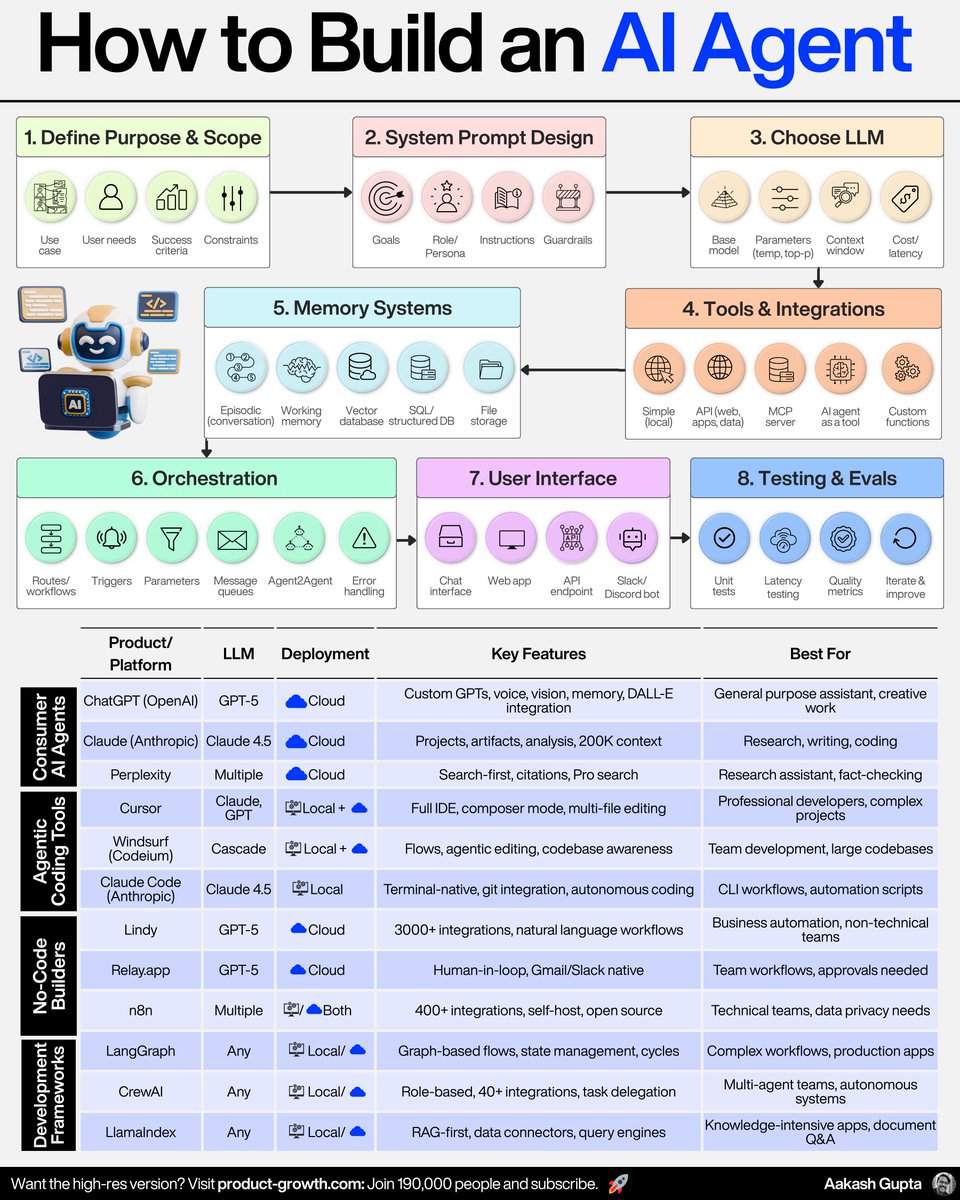
⫸ꆛ Want to build Real-World AI Agents?
Join My 𝗛𝗮𝗻𝗱𝘀-𝗼𝗻 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝟱-𝗶𝗻-𝟭 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴!
➠ Build Agents for Healthcare, Finance, Smart Cities & More
➠ Master 5 Modules: 𝗠𝗖𝗣 · LangGraph · PydanticAI · CrewAI · Swarm
➠ Includes 9 Full Projects
👉 𝗘𝗻𝗿𝗼𝗹𝗹 𝗡𝗢𝗪 (𝟱𝟲% 𝗢𝗙𝗙):
https://t.co/5i2v1fIrhJ
How to become an AI engineer in just 3 months?
A thread,
I literally spend 40 hours to find the perfect roadmap for beginners with a step by step weekly guide.
(1/n)