Come at the @gradle booth at @scaladays for breakfast!
Freshly baked croissants 🥐 and Swiss chocolate 🍫, all paired with tips and tricks to improve your #sbt#Gradle#Maven#npm#Python builds!
🎧 In < 5 hours!
Join @Gradle creator @hans_d with @scala_lang creator @odersky for a fireside chat on #GenAI and developer productivity, hosted by @trisha_gee!
Don't miss a chance to hear from these industry luminaries in person!
Register 👇 👇 👇
https://t.co/kSk50fx44y
Gradle joining the #Scala Center advisory board means that we get to work more closely with @odersky and the @scala_lang team!
https://t.co/vrc54Rna37
p.s. Take a look at the latest #Scala builds and tests at https://t.co/bhDbKx7Sxx
The way Datadog calculates percentiles at scale is very innovative 🔥
Usually, calculating the percentiles of large datasets is very expensive.
To know the 99th percentile of a stream of values, you need to:
- keep all the values
- sort them
- return the value whose rank matches the percentile (e.g 99th item)
Datadog cannot afford to do this with the many millions of data points that come in every second - the space and CPU requirements are not practical for a company with thousands of customers. 🐾
Naturally, they opted for sketch algorithms - those should provide them with a good-enough probabilistic result while being vastly more efficient to compute.
Unfortunately - they couldn’t get satisfactory results.
The algorithms would produce results that were too inaccurate. ❌
Why?
Many percentile sketches had guarantees in terms of *rank error*.
A rank-error guarantee of 2% means that the p95 value returned by the sketch is somewhere between the p93-p97 value.
But system latencies exhibit very fat tails - the difference between the p97 and p99 values can be 2-10x!
So what did the dogs do? 🐶
They invented a new sketch algorithm - DDSketch.
Instead of rank error guarantees, they designed it for *relative error* guarantees.
If the p99 is 60s, a 2% error means the sketch would return 58.8-61.2s.
The algorithm is surprisingly pretty simple:
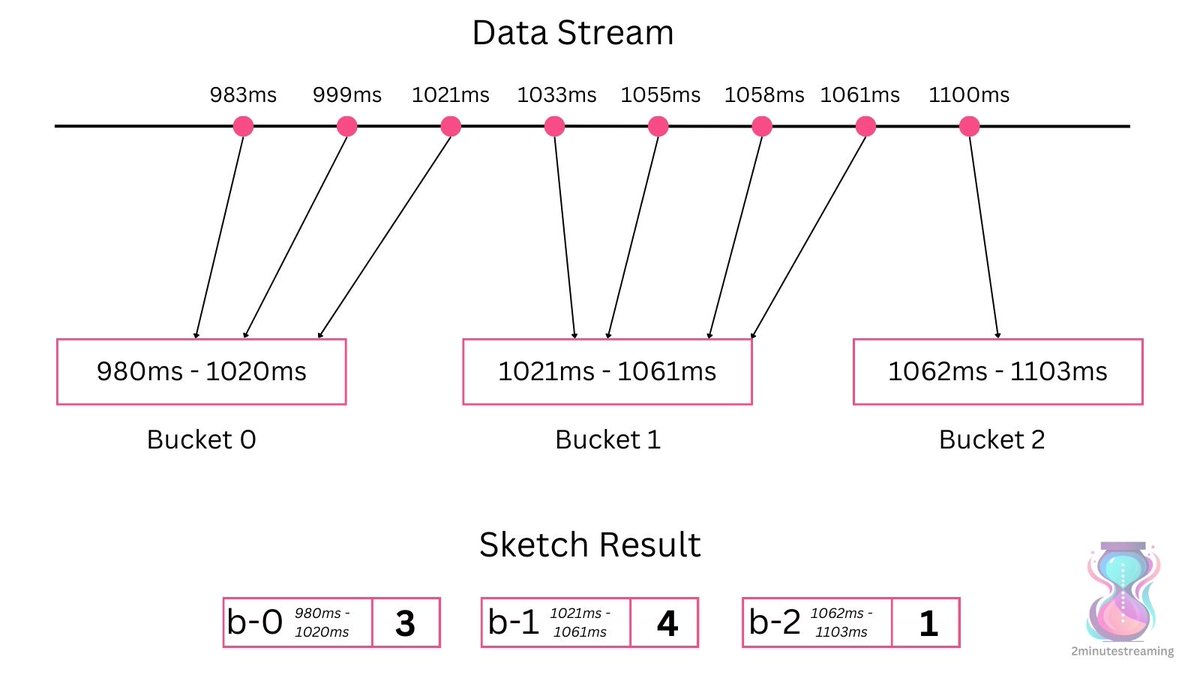
• They create buckets covering ranges of the desired error rate. (+- 2% in this case) 🪣
• Each bucket keeps a counter of the amount of data points within that range. 💯
• When processing an item (latency metric data point), increment the counter of the appropriate bucket. ➕
• To count the desired percentile, you sum up the bucket’s values until you get to the desired percentile. Whatever bucket that percentile is in - that’s your value. 🏆
In this example, the 50th percentile is 1033ms. (4th value out of our total of 8)
Going by count, the 4th value is in the second bucket (b-1) and the algorithm would produce a result of 1021-1061ms.
To cover the range from 1 millisecond to 1 minute, you only need 275 buckets.
With 64-bit counters, that's just ~2kB of memory, regardless of the amount of input data.
This is why we call sketch algorithms sublinear in space growth - memory requirements do NOT grow linearly with input.
The exponential nature of the bucket distribution makes it cheap to cover an even wider range: 1 nanosecond to 1 day takes just 3x more buckets:
• 802 buckets at ~6kB.
As you can probably tell, this is pretty easy to parallelize.
You can divide this bucket-building exercise into many parallel lightweight substreams, and then merge the results freely. 🕊
The merge operation is a simple sum of the buckets & their counters, which ensures that the accuracy is kept in the same range.
It is a very scalable and performant sketch algorithm.
Kudos to Datadog for inventing it.
Good boy! 🫳🐕🦺
Finally, Scala Italy returns with a 2023 edition in its birthplace, Milano! The event will be on 10-11 November. For updates, check our site https://t.co/081xJ0oZiC. Stay tuned!
Did you know that @gradle offers much more than a build tool? We caught up with @mircodotta at the Scala Tooling Summit where he explained that Gradle Enterprise is like a Swiss Army knife for developers' productivity.
#Scala@scala_lang
For everyone who has asked about the Safer Exceptions paper, here's a link that should work: https://t.co/F1oeUnHk4V
It seems there is a way to get open access to ACM papers but you have to go through some other link first.
@mariofusco Have you heard of checked exceptions in Scala 3? >> https://t.co/ISweRw4xga
I haven’t been following, so I don’t know whether the idea has been pushed forward or not. But I guess we would all love to listen to a talk on the subject. For sure it will be polarizing! 😅
@afaranwide@Livex EP demand for this chateau is far exceeding availability for the retailers I am a client of. Based on the few data points I have, the free market is proving them right.