@kikollan@goizean Justo ayer estaba escuchando la radio y le dije a mi novia “me gustaría ver en tiempo real los escaños que están en juego” y tuve un déjà vu de otras elecciones y solamente busqué “@kikollan” en Twitter 🙂. Gracias!
@diegomarino@ClaudeDevs Yo uso cmux como terminal y tengo siempre pineado un workspace de notas con un agente de Claude ejecutándose ahí. Si me pasa lo que dices me voy a ese workspace y listo. En la carpeta de notas puedes tener una skill de /todo que incluso puede ser un recordatorio
@Jongonzlz Es que además este tipo de debates con datos en directo le vienen muy bien al que no tiene ningún reparo en mentir (sea del signo que sea). Luego se puede comprobar y contrastar en el frío de Twitter pero en muchos casos ya es tarde
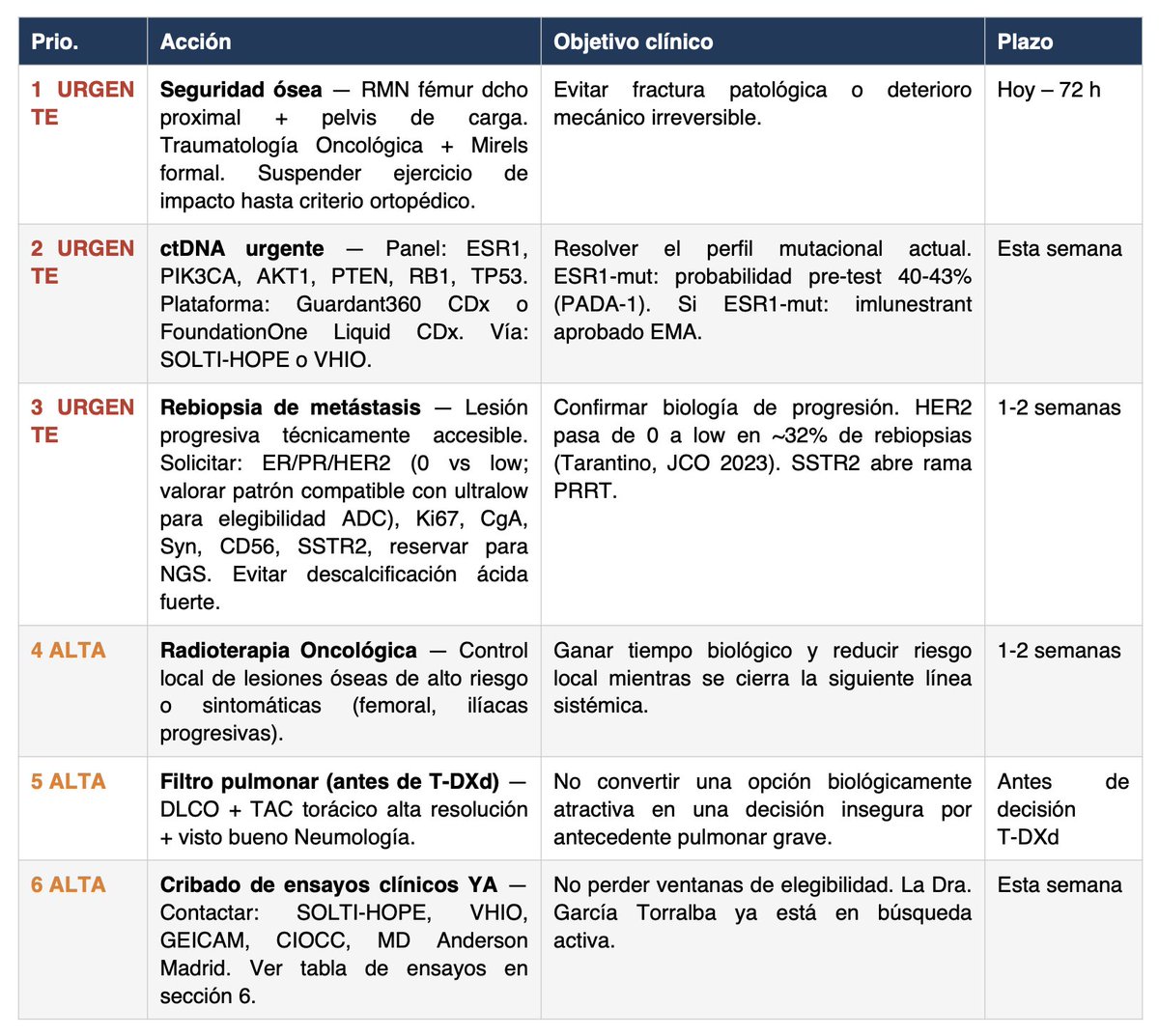
🔴 NECESITO TU ATENCIÓN
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: https://t.co/KEEWc8WNvW Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.
Tengo 35 años y cancer de mama metastásico, un caso raro, menos del 1% de tumores de mama son como el mío y hay poca documentación sobre ello.
Por eso me gustaría encontrar personas que se dediquen a esto y que quieran investigar con mi caso. Twitter haz tu magia
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
¡Y aquí tenéis por fin nuestro cartel para el #LUDOFEST Villaverde, el primero de muchos LUDOFEST que vendrán con los años! (que no tengas que decir que no estuviste en el primero)
ENTRADA GRATUITA
Inscripción necesaria: https://t.co/HbQTlU6hWW
@Tranjisgames@MalditoGamesES
@vinates 100%. Un simple "hola" no tiene ningún sentido. Ralentiza el proceso e interrumpe (mínimo) dos veces. Imagino que conoces https://t.co/MCHpdBLCo3
@javilop Todo este circo no es más que una distracción para mover el debate lejos de los trenes de cara a las elecciones del domingo. Si ya estuviera prohibido el acceso, hoy Sánchez estaría proponiendo quitar la restricción porque patatas para mover el debate.
@chocotuits@Iberia Ahora me dan ganas de dejar una maleta trampa con un AirTag para revivir tu historia. Qué grande 😂😂😂 Me alegro que se esté resolviendo
@JosuGoi1@joselcs@dei_biz IMO pocos casos de uso justifican usar modelos locales por privacidad / seguridad. Lo que sí justificaría tener parte de la infra onprem es la disponibilidad de GPUs en alguna región o como fallback / disaster recovery. Pero igualmente en servicios con una criticidad alta
@JosuGoi1@joselcs@dei_biz Bueno, tanto en Azure como en AWS puedes usar los modelos via Azure OpenAI / Bedrock y los datos no tienen por qué salir fuera de UE (si el modelo está disponible) y las políticas son muy estrictas para PII y PHI (e.g. puedes cifrar los datos con tu propia clave)
@EFEnoticias@dgonzalezrivas Mi madre tiene un Carcinoma epidermoide de laringe. Optamos x radio paliativa porque la operacion y recuperación nos pareció demasiado. Anoche ingresó en urgencias desde la resi y ahora estamos en planta. Se puede hacer algo con mi madre que no sea paliativo, @dgonzalezrivas?🙏🏻
✨ El mundo no empeora, mejora.
No es perfecto; ni siquiera un buen lugar. Pero de los escenarios globales que hemos conocido (no imaginado o deseado), este es el mejor.
45 datos para empezar 2026 con optimismo👇
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
33 años después, el enigma del virus Málaga por fin tiene respuesta.
Ha sido muy emocionante cerrar el círculo.
Gracias por acompañarme en esta historia.
https://t.co/BJH4Y73CYy