if you write some really good code these days everyone thinks you did it with Claude Code. if you lose a lot of weight everyone thinks you did it with Ozempic. at least you can still be really good at dancing. they don't make ozempic or Claude Code for being good at dancing
okay maybe it's a good time? We have a small colbert model trained at pplx, it is a continue-training of pplx-embed-0.6b, so native multilingual, just made it open and added a section how to use MaxSim kernel:
https://t.co/iwa0PrTPm4
Exciting publication alert!! Congrats to the whole team for the nice ideas and thorough execution 🎯
Hyped to take the time to deep-dive into every part :)
🚨 Do LLMs need to store everything they read in memory?
To reduce KV cache size and improve decoding speeds, we propose Self-Pruned KV attention, a mechanism where the model learns to decide which KVs to write in the persistent KV cache, discarding all the rest! @AIatMeta🧵
We're releasing LateOn and DenseOn today. Two open retrieval models, 149M parameters each.
LateOn (ColBERT, multi-vector): 57.22 NDCG@10 on BEIR.
DenseOn (dense, single-vector): 56.20.
Both beat models up to 4× larger
We're open-sourcing the weights under Apache 2.0 🧵👇
The new generation of open state-of-the-art single and multi-vector retrieval models is here
It's time, DenseOn with the LateOn 🎶
@LightOnIO releases models that leap past existing ones, and everything you need to do the same!
Update on the Late-Interaction Workshop @ ECIR2026: it was amazing! 🇳🇱
So cool to meet late-interactors IRL for the first time, I enjoyed every bit of that day 🤗 And congrats & huge thanks to the organizers again.
Link to our work + poster below ⬇️
Great work from @weaviate_io that compares the performances of text retrievers and multimodal ones.
It appears that their errors are complementary, which makes their combination in hybrid search promising.
Check their paper!
https://t.co/vu9Nwcjpjs
Most practicionners would agree that text embeddings should be "contextual" - ie. they should encode a passage w.r.t. the wider scope of the entire document the passage stems from; "They beat the British" could refer to football or french history without further context...
In ConTEB (https://t.co/Qhezrjbmks), we highlight the standard failure modes of embedding models on retrieval tasks that require context to be properly embedded. We also propose a training strategy that extends standard "late chunking" to teach models to infuse embeddings with just the right amount of contextual knowledge to optimize retrieval.
Super happy to see some new work by @perplexity_ai on contextual embedding models. They eval on ConTEB and use our in-sequence contrastive loss, along with a ton of cool techniques in multiple phases of training. Love the work @bo_wangbo and will read in details, but super happy to see one more stone towards contextual embedding models, in the path already traveled by @hxiao and @jxmnop !
Link to the paper: https://t.co/qlWRcn4QRx
Very proud of this paper, we lead many more experiments since the first release.
I think we made a pretty complete analysis of what is currently possible with the benchmark !
Thanks again to everyone involved !
In our EMNLP 2025 Oral paper with @mlpc123, we propose an extension to Late Chunking and demonstrate how we can embed contextual information within passage embeddings... and why it's often very useful to improve document retrieval! (9/15)
https://t.co/SrD61QkxAQ
So happy for you that this project finally sees the day, more than a simple extension of the previous versions! Congrats for the hard work @MaceQuent1@antonio_loison 🥳
📢 ViDoRe V3, our new multimodal retrieval benchmark for enterprise use cases, is finally here!
It focuses on real-world applied RAG scenarios using high-quality human-verified data. https://t.co/Fs6W2gNQJc
🧵(1/N)
@JinaAI_ Why did you organize the BoF at the same time as a Information Extraction and Retrieval Oral session 😢
Will be presenting our work that builds on top of Late Chunking there instead :)
I'll be in Suzhou next week to present this project as an Oral at #EMNLP2025! 🥳
Let me know if you're there and wanna get in touch, or if you know anyone who'd be interested :)
Looking forward! 🙌🇨🇳
https://t.co/ckRv8yHHmQ
🕺Super happy to release our latest work with @ManuelFaysse: in our paper "Context Is Gold to Find the Gold Passage", we share all our findings on how to train embedding models to meaningfully include doc-wide context into chunks - leading to convincing results! 🧑🍳 🧵1/N
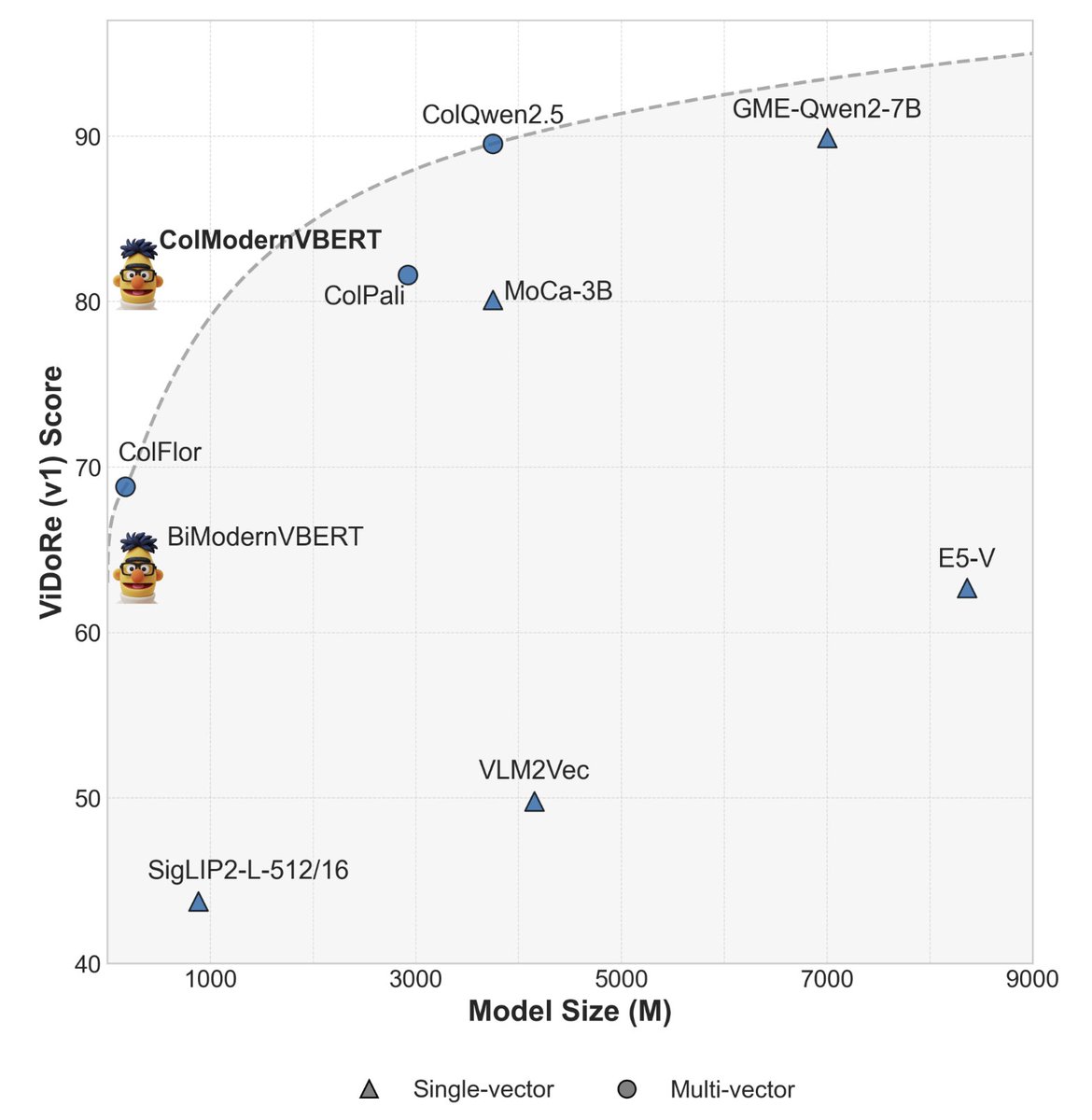
Introducing ModernVBERT: a vision-language encoder that matches the performance of models 10× its size on visual document retrieval tasks! 👁️
Read more in the thread👇 (1/N)
Besides our main results, it was also really interesting to look at some understudied training dynamics in more details
Our findings suggest that we've been using visual encoders far below their potential, and I think we can expect a lot of improvements building on top of this!