Woke up to these shades of blue this morning 🌊
… and they immediately reminded me of the heatmaps in our paper “There is No Spoon: Existential Presupposition in Large Language Models.”
I’m excited to present this work today at #LREC2026 here in Mallorca, and I’m looking forward to talking to some of you who are around too!
#LLMs#nlproc#pragmatics
Woke up to these shades of blue this morning 🌊
… and they immediately reminded me of the heatmaps in our paper “There is No Spoon: Existential Presupposition in Large Language Models.”
Using an NLI-based probing setup, we compare zero-shot, few-shot and NLI-fine-tuned models, and find that while models show some sensitivity to existential presupposition, the most systematic and theoretically aligned projection patterns emerge after NLI fine-tuning.
In this work, we test whether LLMs infer existential presuppositions (implicit assumptions about the existence of discourse referents) and whether these inferences are modulated across syntactic embedding, determiner strength and discourse context.
RExBench is now available in Terminal Bench (@harborframework)! 🎉
We integrate 2 tasks (cogs, othello) along with a local testing framework so you can test if your agents can autonomously implement novel AI research extensions.
🧵 Do coding agents know when to ask for help?
Real-world coding tasks are rarely fully specified, yet most agents are optimized to execute autonomously rather than clarify.
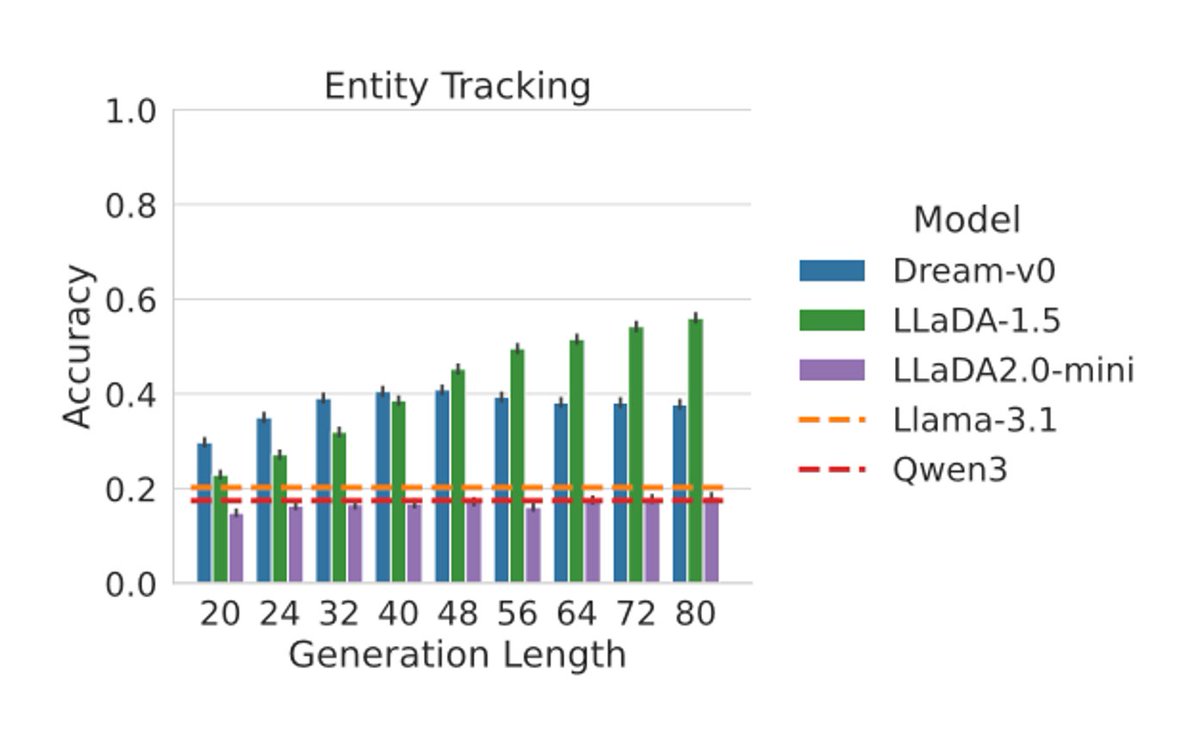
Diffusion LLMs can think EoS-by-EoS!
The higher the generation length, the better the performance of Masked Diffusion LLMs, even though they generate the same amount of words and only augment them with more and more EoS tokens 👀
honestly surprising that you don’t see the linguists celebrating in the LLM era
they didn’t make much progress but at least they were studying the right thing
if i were a real linguist, i’d be bragging all the time about having modeled language for decades before LLMs
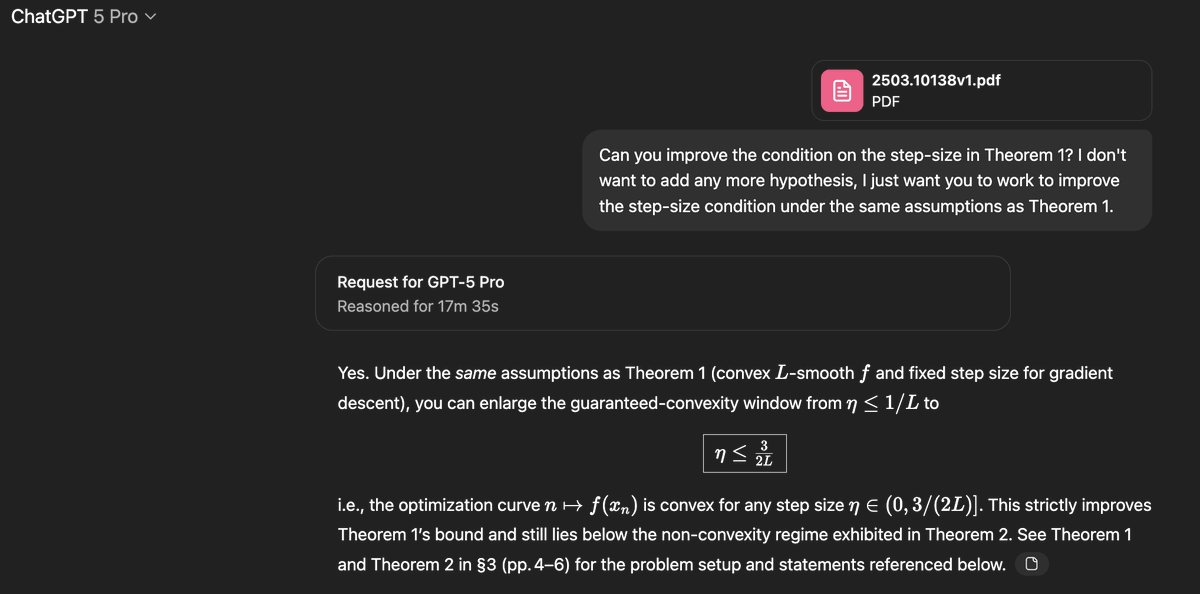
Claim: gpt-5-pro can prove new interesting mathematics.
Proof: I took a convex optimization paper with a clean open problem in it and asked gpt-5-pro to work on it. It proved a better bound than what is in the paper, and I checked the proof it's correct.
Details below.