Professor @ University of Stuttgart, Scientific Advisor @ NEC Labs, GraphML, geometric deep learning, ML for Science. Formerly @IUBloomington and @uwcse
My NeurIPS 2025 paper looked into the numerical errors present in synthetic data used for neural surrogates... and uncovered a counter-intuitive finding. Since the paper can be hard to digest, here is a lightweight introduction: https://t.co/M3sw0Yj8bM
In case you missed it — we're hiring an Assistant Prof in Machine Learning (AI4Science) at @AmlabUva
🇪🇺 One of Europe's top ML groups, based in Amsterdam.
Deadline: May 30 — still time to apply! 👇
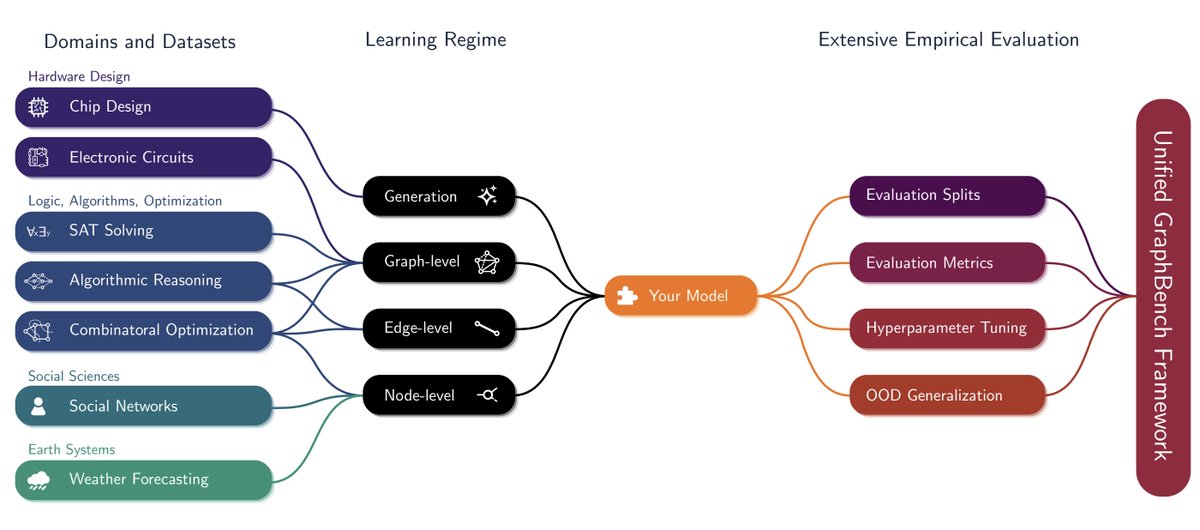
Remember our ICML25 "Graph Learning Will Lose Relevance Due To Poor Benchmarks"?
Fear no more! GraphBench is here! 🤩
We give you: The next generation of Graph Benchmarking! Including:
-New shiny high-quality datasets from diverse domains spanning seven domains, including chip design, algorithmic reasoning, and weather forecasting.
-Standardized hyperparameter tuning procedures, enabling fair and principled model comparison
- Strong, transparent baselines that accurately reflect algorithmic progress
- Comprehensive coverage of graph learning tasks, datasets, and modern GNN architectures
- Reproducibility-focused design, minimizing variance and evaluation artifacts
- Forward-looking benchmark designed for next-generation graph learning research
A huge collab with: @chrsmrrs, @mmbronstein, @michael_galkin, @HolgerHoo, Timo Stoll, @ChendiQian, @benfinkelshtein, Ali Parvis, Darius Weber, @ffabffrasca, @HadarShavit, @antoinesrdin, Arman Mielke, Marie Anastacio, Erik Müller,
GraphBench: Next-generation graph learning benchmarking is now available! 🔍📊
This work introduces GraphBench: a comprehensive benchmarking framework for graph learning that provides principled baselines and reference performance across modern models.
https://t.co/wm2NlL02tq
@_sophia_tang_ Thank you for writing this up! Having work presented in a more accessible and comprehensive way is incredibly important for the community and new students.
Sovereignty should not be Europe’s growth strategy.
If your sales pitch is “buy us because we’re European,” you’re already losing.
Europe needs companies like BlackForestLabs:
global ambition from day one, built in Europe.
Not: “We build AI for European SMBs so they know we keep their data save.”
The path forward is competing with US companies in their home market from day one.
Lovable, BlackForestLabs, n8n and others have shown how its done!
5 months from Latent-X1 to Latent-X2. AI-generated antibodies with drug-like developability and low immunogenicity in human panels — zero-shot.
Available now for selected partners.
I respect that @iclr_conf had to respond to the OR leak, but I disagree with resetting scores. Many students worked hard on rebuttals and improved their papers in good faith. I hope the organizers reconsider and revert the reset. If you agree, feel free to retweet.
✨ 𝐓𝐡𝐫𝐢𝐥𝐥𝐞𝐝 𝐭𝐨 𝐬𝐡𝐚𝐫𝐞 𝐭𝐡𝐚𝐭 𝐨𝐮𝐫 𝐩𝐚𝐩𝐞𝐫 𝐄𝐱𝐆𝐫𝐚-𝐌𝐞𝐝 [1] 𝐡𝐚𝐬 𝐛𝐞𝐞𝐧 𝐚𝐜𝐜𝐞𝐩𝐭𝐞𝐝 𝐭𝐨 NeurIPS 2025! (one of three other ones accepted this year 🚀 ) ✨
Over the past year, my collaborators and I have been exploring a fundamental limitation of 𝐦𝐮𝐥𝐭𝐢-𝐦𝐨𝐝𝐚𝐥 𝐥𝐚𝐫𝐠𝐞 𝐥𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐦𝐨𝐝𝐞𝐥𝐬 (MLLMs) on 𝐝𝐚𝐭𝐚-𝐡𝐮𝐧𝐠𝐫𝐲 tasks and how to overcome it. So how does it help with your work?
🔍 𝐈. 𝐊𝐞𝐲 𝐅𝐢𝐧𝐝𝐢𝐧𝐠: 𝐀𝐮𝐭𝐨-𝐫𝐞𝐠𝐫𝐞𝐬𝐬𝐢𝐯𝐞 𝐌𝐋𝐋𝐌𝐬 𝐀𝐫𝐞 𝐄𝐱𝐭𝐫𝐞𝐦𝐞𝐥𝐲 𝐃𝐚𝐭𝐚-𝐇𝐮𝐧𝐠𝐫𝐲 𝐔𝐧𝐝𝐞𝐫 𝐃𝐨𝐦𝐚𝐢𝐧 𝐒𝐡𝐢𝐟𝐭
We found that 𝐫𝐞𝐝𝐮𝐜𝐢𝐧𝐠 𝐩𝐫𝐞-𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠 𝐝𝐚𝐭𝐚 during domain adaptation 𝐭𝐫𝐢𝐠𝐠𝐞𝐫𝐬 𝐢𝐫𝐫𝐞𝐜𝐨𝐯𝐞𝐫𝐚𝐛𝐥𝐞 𝐟𝐚𝐢𝐥𝐮𝐫𝐞𝐬 𝐢𝐧 𝐚𝐮𝐭𝐨-𝐫𝐞𝐠𝐫𝐞𝐬𝐬𝐢𝐯𝐞 𝐌𝐋𝐋𝐌𝐬 - failures that 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐜𝐚𝐧𝐧𝐨𝐭 𝐟𝐢𝐱. This reveals a critical weakness: current models learnt by purely auto-regressive models are not robust to domain shift.
Joint work with great collaborators @cmuptx@james_y_zou , and my supervisor @Mniepert. Details below
@Mniepert@lfochamon Inspired by JEPA, C-FREE (w/ B. Ariguib & @mniepert) uses a predictive objective over egonets spanning 2D and 3D graphs, avoiding negatives, reconstructions, and augmentations. This simple multimodal design delivers strong results from low- to large-scale regimes. 🔬 🧵6/9
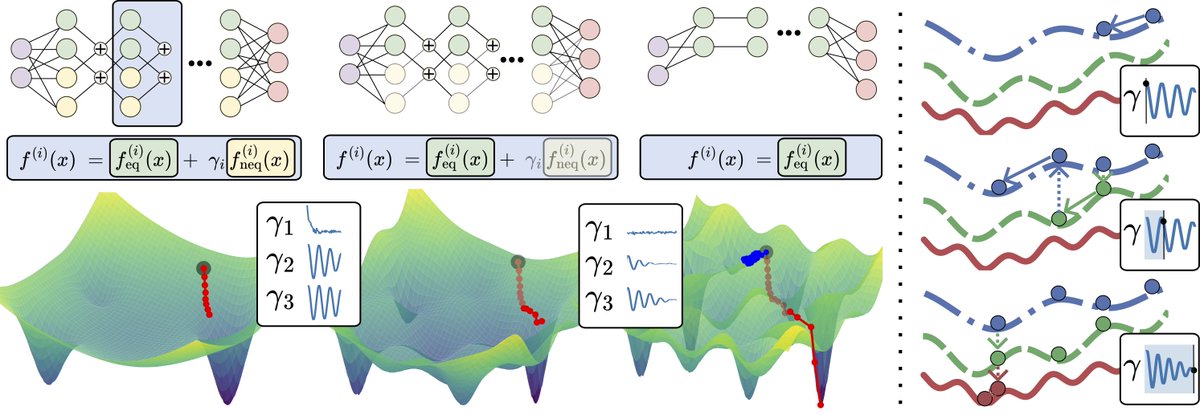
"Learning (Approximately) Equivariant Networks via Constrained Optimization" will be an Oral 🗣️ at NeurIPS! (w/ @Mniepert & @lfochamon) ACE goes beyond fixed equivariance, augmentations, and regularizers by learning from data when to enforce symmetry and when to break it. 🧵2/9
Looking forward to #NeurIPS next week! I’m presenting three works across equivariant learning, molecular graph pretraining, and real-world graph-based time series:
• ACE (NeurIPS Oral)
• C-FREE (NPGML Poster)
• ChronoGraph (BERT2S Oral)
Details in the thread ⬇️🧵1/9
As promised after our great discussion, @chaitanyakjoshi! Your inspiring post led to our formal rejoinder: the Platonic Transformer.
What if the "Equivariance vs. Scale" debate is a false premise? Our paper shows you can have both.
📄 Preprint: https://t.co/kd8MFiOmuG
1/9
"Equivariance matters even more at larger scales" ~ https://t.co/FDJe7kRLwy
All the more reason we need scalable architectures with symmetry awareness. I know this is an obvious ask but I'm still confident that scaling and inductive bias need not be at odds.
This paper (alongside https://t.co/limCgeyhak) is convincing evidence that believing "equivariance is dead/not necessary" and "scaling is all you need" might be myopic (ofc, no one has made this *strong* claim but it still seems to be an existing "community myth" of sorts)
Stay tuned to this space – we're dropping something cool on this topic veryyy soon ;)
I just read the Equilibrium Matching (EqM) paper; it’s excellent and insightful work!
Interestingly, we recently published a related method called Adaptive Equilibrium Flow Matching (AEFM). Leaving out “adaptive” reveals strong conceptual parallels between the two approaches.
I just read the Equilibrium Matching (EqM) paper; it’s excellent and insightful work!
Interestingly, we recently published a related method called Adaptive Equilibrium Flow Matching (AEFM). Leaving out “adaptive” reveals strong conceptual parallels between the two approaches.






















![DuyHMNguyen1's tweet photo. ✨ 𝐓𝐡𝐫𝐢𝐥𝐥𝐞𝐝 𝐭𝐨 𝐬𝐡𝐚𝐫𝐞 𝐭𝐡𝐚𝐭 𝐨𝐮𝐫 𝐩𝐚𝐩𝐞𝐫 𝐄𝐱𝐆𝐫𝐚-𝐌𝐞𝐝 [1] 𝐡𝐚𝐬 𝐛𝐞𝐞𝐧 𝐚𝐜𝐜𝐞𝐩𝐭𝐞𝐝 𝐭𝐨 NeurIPS 2025! (one of three other ones accepted this year 🚀 ) ✨
Over the past year, my collaborators and I have been exploring a fundamental limitation of 𝐦𝐮𝐥𝐭𝐢-𝐦𝐨𝐝𝐚𝐥 𝐥𝐚𝐫𝐠𝐞 𝐥𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐦𝐨𝐝𝐞𝐥𝐬 (MLLMs) on 𝐝𝐚𝐭𝐚-𝐡𝐮𝐧𝐠𝐫𝐲 tasks and how to overcome it. So how does it help with your work?
🔍 𝐈. 𝐊𝐞𝐲 𝐅𝐢𝐧𝐝𝐢𝐧𝐠: 𝐀𝐮𝐭𝐨-𝐫𝐞𝐠𝐫𝐞𝐬𝐬𝐢𝐯𝐞 𝐌𝐋𝐋𝐌𝐬 𝐀𝐫𝐞 𝐄𝐱𝐭𝐫𝐞𝐦𝐞𝐥𝐲 𝐃𝐚𝐭𝐚-𝐇𝐮𝐧𝐠𝐫𝐲 𝐔𝐧𝐝𝐞𝐫 𝐃𝐨𝐦𝐚𝐢𝐧 𝐒𝐡𝐢𝐟𝐭
We found that 𝐫𝐞𝐝𝐮𝐜𝐢𝐧𝐠 𝐩𝐫𝐞-𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠 𝐝𝐚𝐭𝐚 during domain adaptation 𝐭𝐫𝐢𝐠𝐠𝐞𝐫𝐬 𝐢𝐫𝐫𝐞𝐜𝐨𝐯𝐞𝐫𝐚𝐛𝐥𝐞 𝐟𝐚𝐢𝐥𝐮𝐫𝐞𝐬 𝐢𝐧 𝐚𝐮𝐭𝐨-𝐫𝐞𝐠𝐫𝐞𝐬𝐬𝐢𝐯𝐞 𝐌𝐋𝐋𝐌𝐬 - failures that 𝐟𝐢𝐧𝐞-𝐭𝐮𝐧𝐢𝐧𝐠 𝐜𝐚𝐧𝐧𝐨𝐭 𝐟𝐢𝐱. This reveals a critical weakness: current models learnt by purely auto-regressive models are not robust to domain shift.
Joint work with great collaborators @cmuptx @james_y_zou , and my supervisor @Mniepert. Details below](https://pbs.twimg.com/media/G6xdxdXW0AAFzqc.jpg)