We are looking for: PhD Student (starting as Research Assistant) and Postdoctoral Researcher in Stem Cell Biology and Mechanobiology. Please RT💕
🔗 About our lab: https://t.co/53gtr8qx68
🎓 PhD position: https://t.co/hL3Zfk7oII
🧪 Postdoc position: https://t.co/0mVS4ZaomG
EEE meeting is BACK! Early Embryogenesis & Epigenetics conference in Berlin 02/2026.
Checkout great program and over 12 slots for (not so) short talks for submitted abstracts!. Early registration now open - https://t.co/XZIEGUV11v
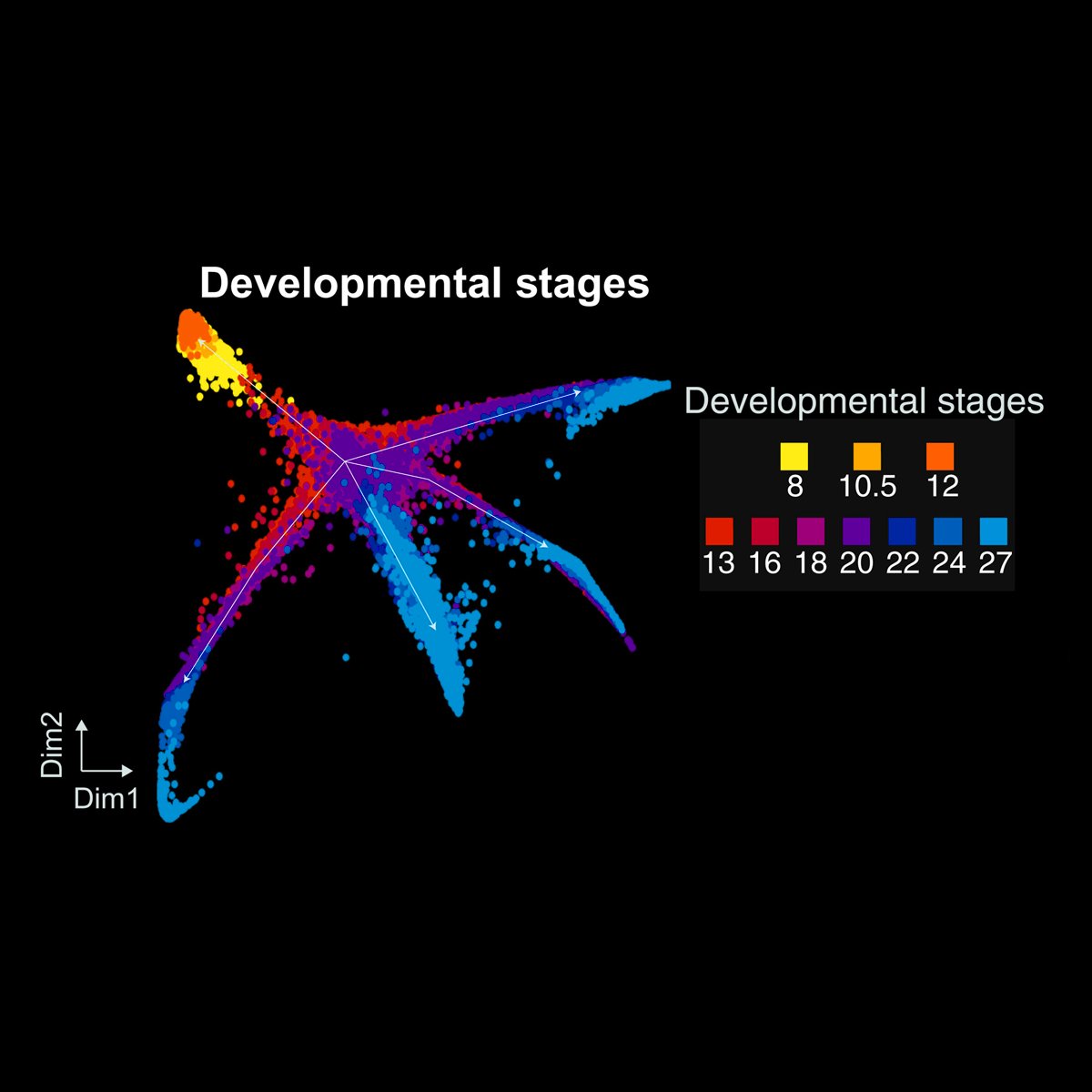
🧵1/14 Preprint thread! Can we predict a cell’s fate based on its dynamics? 🔮 Our new study unveils a framework for watching development unfold in real-time, revealing how a cell's shape and movement encode info about its future fate. 🔬📄 Preprint: https://t.co/84lDgRTJgc
We are hiring! Together with Ana Carolina de Sousa Leote, I am looking for two Computational Biology interns to join our group at Genentech in South San Francisco.
Deadline June 26. Apply here: https://t.co/UcuRfbx6I6
Have you ever wondered how the same pathway can elicit different responses in distinct contexts? Check out the second part of my PhD work, now available @Dev_journal
Read the full story here: https://t.co/FsAGpXhZjI
Or read the tweetorial below (1/7)
Lee et al. profile the developing Xenopus mucociliary epithelium (MCE) from pluripotent to mature stages by single-cell transcriptomics. https://t.co/PtvCBoWEjV #science#biology#devbio#xenopus#frogs
If you've ever manually annotated a 96-well plate in excel you know how painful it is. @parambulat0r wrote a webapp to make this easier (including an export feature!). https://t.co/ulj2Kvmeye
MASSIVE idea proposed in this paper.
Kolmogorov-Arnold Networks (KANs) as promising alternatives to Multi-Layer Perceptrons (MLPs) for approximating nonlinear functions 🤯
📌 Unlike MLPs which have fixed activation functions on nodes, KANs have learnable activation functions parametrized as splines on edges. This allows KANs to achieve higher accuracy and parameter efficiency compared to MLPs.
📌 The Kolmogorov-Arnold representation theorem states that any continuous function of n variables can be represented as a composition of 2n+1 univariate functions. The paper generalizes this to KANs of arbitrary widths and depths. A KAN layer with n_in inputs and n_out outputs is defined as a matrix of learnable 1D spline functions. Deep KANs are constructed by stacking multiple such layers.
📌 The key implementation tricks for optimizing KANs include: 1) Using residual activation functions that are a sum of a basis function (e.g. SiLU) and a learnable spline. 2) Careful initialization scales for the splines and weights. 3) Dynamically updating the spline grids based on the input activations during training to handle unbounded activation ranges.
📌 Theoretically, the paper proves an approximation bound for KANs showing that the approximation error in C^m norm scales as G^(-(k+1-m)) where G is the spline grid size and k is the spline order. Notably, this bound is independent of the input dimension, avoiding the curse of dimensionality that affects MLPs. Empirically, KANs are shown to achieve the theoretically optimal scaling exponent of k+1=4 (for cubic splines).
📌 On various experiments including regression, PDE solving, and continual learning, KANs demonstrate superior accuracy and parameter efficiency compared to MLPs. For example, on a PDE task, a 2-layer width-10 KAN achieves 100x lower MSE than a 4-layer width-100 MLP with 100x fewer parameters. KANs also exhibit better continual learning without catastrophic forgetting by leveraging the locality of the spline bases.
📌 The interpretability of KANs is highlighted through techniques like sparsification, pruning, and symbolic simplification of the learned splines. On real-world applications in knot theory and condensed matter physics, KANs are able to uncover known relations and phase transitions in a transparent manner, with the potential for scientific discovery through human-AI collaboration using the language of KANs.
Overall, KANs provide a powerful and interpretable alternative to MLPs by leveraging the Kolmogorov-Arnold theorem and spline approximations, demonstrating state-of-the-art performance on a range of tasks along with favorable scaling behavior and unique capabilities for interactivity and knowledge discovery.
one of the most important things I know about deep learning I learned from this paper: "Pretraining Without Attention"
this what I found so surprising:
these people developed an architecture very different from Transformers called BiGS, spent months and months optimizing it and training different configurations, only to discover that at the same parameter count, a wildly different architecture produces identical performance to transformers
this may imply that as long as there are enough parameters, and things are reasonably well-conditioned (i.e. a decent number of nonlinearities and and connections between the pieces) then it really doesn't matter how you arrange them, i.e. any sufficiently good architecture works just fine
i feel there's something really deep here, and we may be already very close to the upper bound of how well we can approximate a given function given a certain amount of compute. so we should spend more time thinking about other questions, such as what that function should actually look like (what data? which objective function?) and how to make it more efficient
Check out the latest new service on SciLifeLab Data Platform https://t.co/0K95Pye8MB AI4Life Bioimage Model Zoo https://t.co/PSWEofN86N
#bioimaging#AI#DDLS@imweio@scilifelab
I regularly hear people in ML+genomics complain that they're running out of memory or disk space. Frequently, the culprit is inefficient handling of RNA/DNA sequence and you can make big gains in compression with a few tricks. 1/