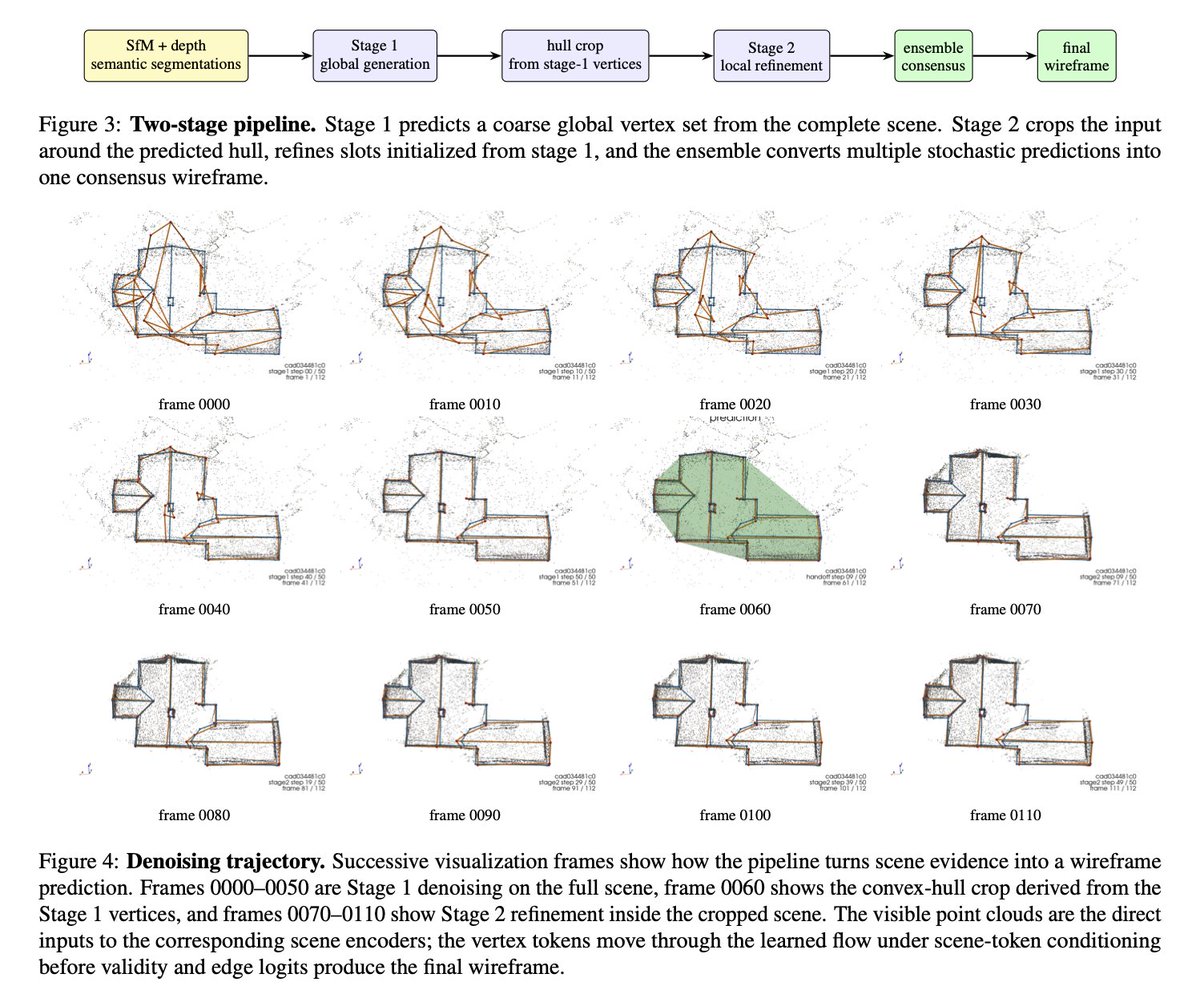
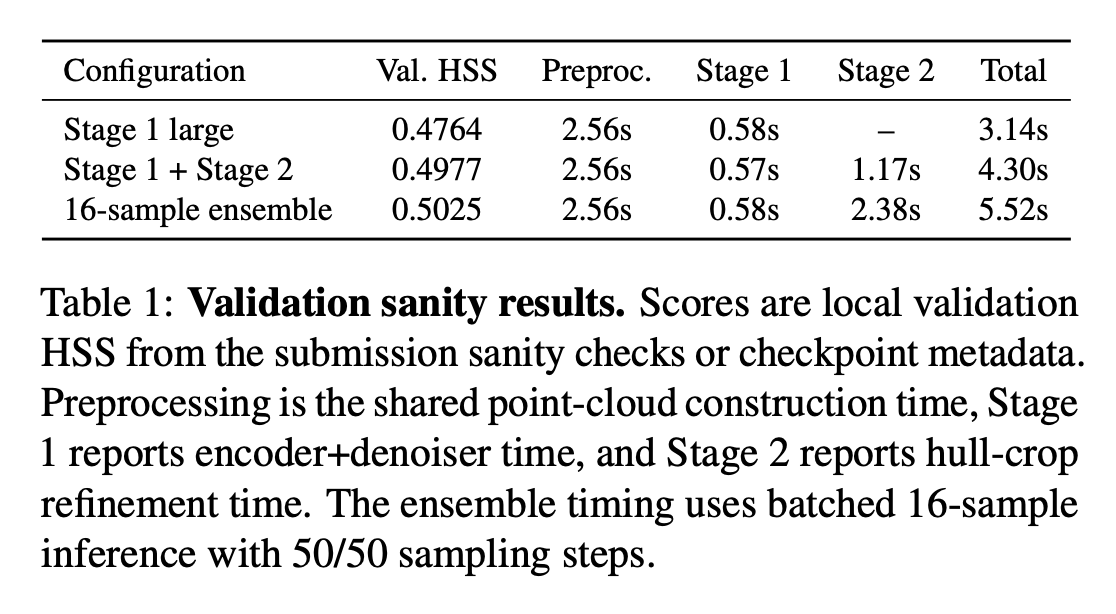
DiffusionGemma uses the core mechanism of Loopholing, our ICLR 2026 paper!
Discrete diffusion hits a sampling wall: rich token beliefs collapse into one hot token at every step.
Loopholing bypasses this with a deterministic latent pathway, improving generation quality.
Announcing the First Geometric Intelligence Workshop at @eccvconf : https://t.co/sCUCzCmfUl. Our aim is to position geometry as a means to transform vision models from spatial structures to the realm of science, in order to advance reasoning and discovery. Submissions by Jul 13.
Wonderful to be back from #CVPR2026, and excited to share the release of our follow-up work:
VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
VoLo introduces the idea of a physical orchestrator for open-vocabulary, long-horizon manipulation. Our goal is to move toward robots that can reason, plan, act, monitor, and recover by adaptively using VLA/WAMs, vision models, and action primitives as tools.
We introduce three main contributions:
🤖 VoLoAgent — a physical orchestrator that plans, monitors, and recovers by adaptively using, halting, and redirecting robot actions with tools.
📊 RoboVoLo — a high-fidelity benchmark with 126 open-vocabulary long-horizon manipulation tasks spanning common sense, memory/state tracking, complex references, and world knowledge.
📈 A large-scale empirical study comparing action models, code-as-policy systems, TAMP-style systems, and ablations of the VoLoAgent orchestrator, complemented by real-robot experiments.
This work was done during my internship at @NVIDIA and would not have been possible without my brilliant collaborators: Hugo Hadfield, Alexander Zook, @mikacuy, @luke_ch_song, @erwincoumans, @xuningy, Faisal Ladhak, @qu_1006, @BirchfieldStan, Jonathan Tremblay, and @robovalts. Huge thanks to everyone!
🔗 Project: https://t.co/Q2pEymou7U
🔗 Previous work, SpaceTools: https://t.co/xNLUjiNG4j
#Robotics #EmbodiedAI #VisionLanguageModels #VLAModels #RobotLearning #NVIDIA #CVPR2026 #LongHorizonManipulation #AI #ComputerVision
How can we distill large text-to-image models without losing the diversity and controllability of the original teacher model?
Excited to share our new ICML 2026 paper: Restoring Initial Noise Sensitivity in Text-to-Image Distillation via Geometric Alignment.
#icml#generation
Fast T2I distillation often maintains high image quality but makes the student much less sensitive to initial noise. This hurts an important property of generative models: changing the input noise should meaningfully change the output, which matters for diversity, layout variation, and noise-driven control. In this work, we trace this issue to standard distillation objectives that enforce pointwise output matching and unintentionally flatten the teacher’s local input-output geometry. We propose GAD (Geometry-Aware Distillation), a plug-and-play objective that preserves the teacher’s local functional behavior by aligning responses to noise perturbations through Jacobian-vector products.
✅ Better diversity
✅ Stronger layout/control transfer
✅ Preserved visual fidelity
✅ No extra inference cost
Paper: https://t.co/sBt1xSm1FE
Code: https://t.co/bmE8qX5cNE
🚀 Excited to share Mirage: latent spatial memory for video world models.
No RGB point-cloud render-and-encode loop. No pixel-space detour.
Just store 3D memory directly in latent space.
⚡ Up to 10.57x faster generation and 55x smaller 3D cache. 🧵
🌐 https://t.co/qfy2ifrKuO
Excited to release the code and model weights for our recent paper "Foveated Diffusion: Efficient Spatially Adaptive Image and Video Generation"! We hope this inspires continued research on mixed-resolution diffusion and efficient token allocation for image and video generation.
📰 Paper: https://t.co/NJ5AtfBsUb
💻 Code: https://t.co/Ich3iR7Rio
🌐 Website: https://t.co/b42nv06I0P
🤗 Weights: https://t.co/zWyy0Qqay1
🚀 Demo: https://t.co/DyMQD64J4U
We put together a fun demo on Hugging Face Spaces — try it out here: https://t.co/DyMQD64J4U. Sketch your own tokenization layouts and pick model variants to run mixed-resolution diffusion live!
1/ New preprint! Reasoning models often require hundreds of task examples and thousands of rollouts to improve on a task. How can they learn more from much less?
Introducing CORE: contrastive self-reflection for rapid, sample-efficient, and interpretable self-improvement 🧵
We introduce a method for training RNNs that is time-parallel and does not suffer from vanishing/exploding gradients.
Key idea is to decouple learning 1) what should be remembered (can be done without recurrence) and 2) how to update memory (can be one-step supervised by #1).
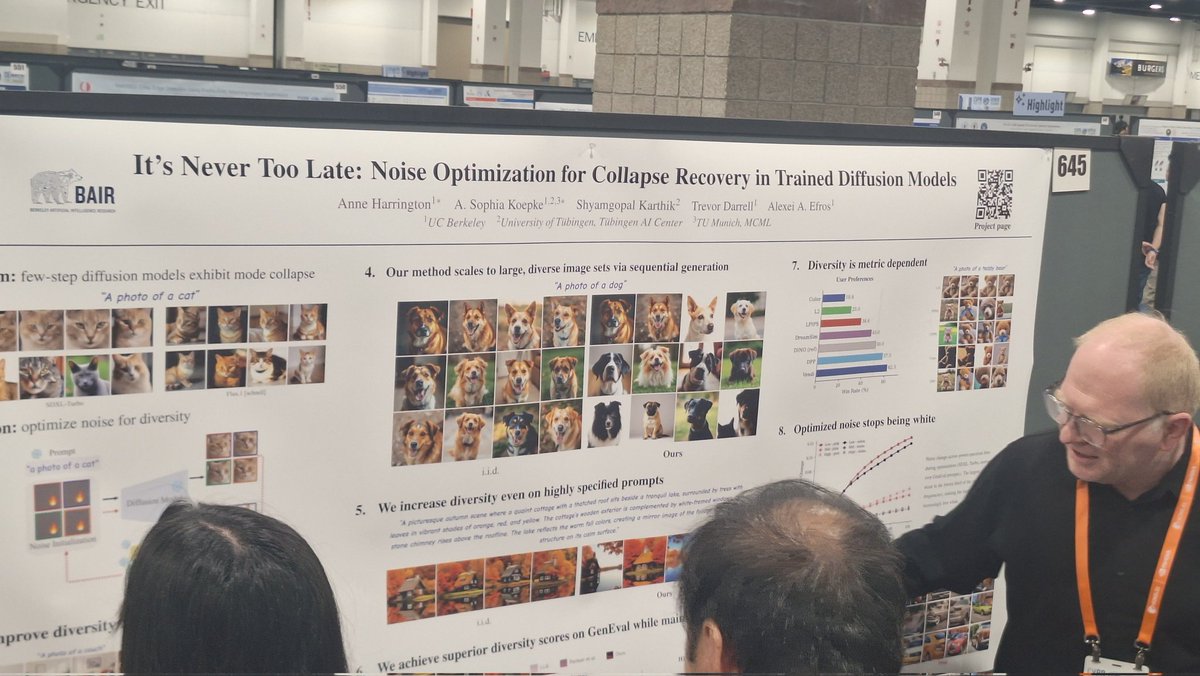
Absolutely packed at
It’s Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models
tldr: recover diversity in trained
T2I diffusion models w/o retraining by optimizing noise latents directly
#CVPR2026@annekharrington@ASophiaKoepke@ShyamgopalKart1
𝗘𝘃𝗲𝗿𝘆𝗼𝗻𝗲 𝘄𝗮𝗻𝘁𝘀 𝟰𝗞 𝗔𝗜. But true native-4K data is still surprisingly scarce.
🚀 Excited to share our new work: 𝟰𝗞𝗟𝗦𝗗𝗕: 𝗔 𝗟𝗮𝗿𝗴𝗲-𝗦𝗰𝗮𝗹𝗲 𝗗𝗮𝘁𝗮𝘀𝗲𝘁 𝗳𝗼𝗿 𝟰𝗞 𝗜𝗺𝗮𝗴𝗲 𝗥𝗲𝘀𝘁𝗼𝗿𝗮𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻, accepted to CVPR 2026 DataCV.
Most public datasets are built around sub-1K, HD, or 2K images. But at 4K resolution, small artifacts become big problems: blurry textures, distorted boundaries, repeated patterns, and missing fine details.
To address this gap, we introduce 𝟰𝗞𝗟𝗦𝗗𝗕, a large-scale native-4K dataset and benchmark for high-resolution restoration and generation.
📌 𝟰𝗞𝗟𝗦𝗗𝗕 𝗶𝗻𝗰𝗹𝘂𝗱𝗲𝘀:
✅ 129K native-4K training images
✅ 2K validation images and 1,984 test images
✅ Diverse categories: nature, urban scenes, people, food, artwork, CGI, and more
✅ Aligned 4K image–text pairs for generative modeling
✅ Paired LR/HR evaluation sets for super-resolution
We also build a multi-stage curation pipeline combining resolution filtering, LMM-based quality scoring, texture-richness filtering, and human verification.
Across classical SR, real-world blind SR, and 4K text-to-image generation, fine-tuning on 4KLSDB consistently improves fidelity, local detail, perceptual quality, and human preference.
💡 Main takeaway: 𝗻𝗮𝘁𝗶𝘃𝗲-𝟰𝗞 𝘀𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗶𝗼𝗻 𝗺𝗮𝘁𝘁𝗲𝗿𝘀.
As visual AI moves toward ultra-high-resolution restoration and generation, we need datasets and benchmarks that expose the fine-scale failures hidden by low-resolution evaluation.
📄 𝗣𝗿𝗼𝗷𝗲𝗰𝘁 𝗽𝗮𝗴𝗲: https://t.co/FGNSgGrZsL
💻 𝗚𝗶𝘁𝗛𝘂𝗯: https://t.co/82i4DAifwj
💽 𝗗𝗮𝘁𝗮𝘀𝗲𝘁: https://t.co/owegqJFype
#ComputerVision #GenerativeAI #ImageRestoration #SuperResolution #TextToImage #DiffusionModels #Dataset #Benchmarking #TAMU
#CVPR2026 / @CVPR Report (on-going work on 8 June)
We’re planning to publicly share a "CVPR 2026 Report"! Sorry for the delay, but we expect to publish it within about a week. In the meantime, please take a look at our previous reports from CVPR 2025 & ICCV 2025.
- CVPR 2025: https://t.co/jtBqn5gZ0r
- ICCV 2025: https://t.co/5NSlqQSRDL
Great to attend #CVPR2026 to present the #highlight work
No calibration, No Depth, No Problem: Cross-Sensor View Synthesis with 3D Consistency- we fundamentally leave out sensor calibration in multi sensor data acquisition
Project page and code: https://t.co/inpq5AvBBn
We’re looking forward to presenting UPLiFT at #CVPR2026! Efficiently extract pixel-dense features from pretrained backbones like DINOv3.
We’ll be at the final poster session on Sunday (6/7) from 3:30-5:30pm at Poster 474, so please come by!
Website: https://t.co/Wng5ZfzjGA