Research scientist @ Bosch Center for Artificial Intelligence (BCAI). Interested in all things dynamical systems and numerical solvers. Views are my own. He/him
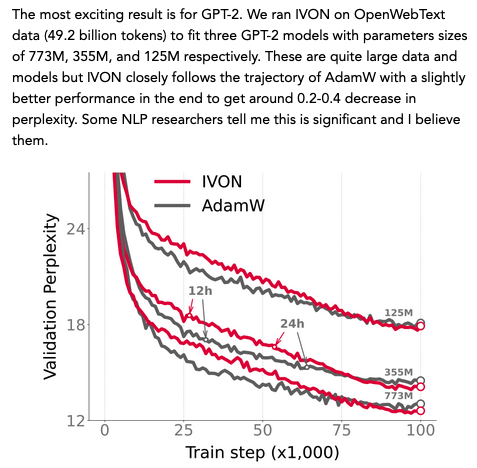
We don't expect Bayesian methods to do so well at large scale, but we can now get decent improvements with variational learning to GPT-2. I wrote a blog about this (first one in a long time). Check it out!
https://t.co/c7ftgBol2x
Paper: https://t.co/GUFi1br9av
A thread below.
More than 50% of the reported reasoning abilities of LLMs might not be true reasoning.
How do we evaluate models trained on the entire internet? I.e., what novel questions can we ask of something that has seen all written knowledge? Below: new eval, results, code, and paper.
Functional benchmarks are a new way to do reasoning evals. Take a popular benchmark, e.g., MATH, and manually rewrite its reasoning into code, MATH(). Run the code to get a snapshot that asks for the same reasoning but not the same question. A reasoning gap exists if a model’s performance is different on snapshots. Big question: Are current SOTA models closer to gap 0 (proper reasoning) or gap 100 (lots of memorization)?
What we find: Gaps in the range of 58% to 80% in a bunch of SOTA models. Motivates us to build Gap 0 models.
We’re releasing the paper, code, and 3 snapshots of functional MATH() today.
arxiv draft: https://t.co/KtvWPc0R72
github repo: https://t.co/gzDVaxZ9yg
1/🧵
My view of the capabilities of LLMs is probably far below that of the median tech industry person. And yet, the more time passes the more I realize my 2023 views were actually overestimating their future potential and current usefulness.
Parallel to self-driving: circa 2016-2017 my view on the timeline for full-scale self-driving deployment was much more pessimistic than most people in the industry -- I was envisioning ~2023, when everyone else targeted 2020 or earlier. And yet, as time passed I started realizing that I was being grossly overoptimistic.
Gaussian processes are the standard for probability distributions over trajectories or paths. But over what paths? Here we fully characterize the sample path regularity of GPs in relation to the covariance kernel
https://t.co/uAcURi4BBs
The "aha" moment when I realized that curve-fitting was the wrong paradigm for achieving generalizable modeling of problems spaces that involve symbolic reasoning was in early 2016.
I was trying every possible way to get a LSTM/GRU based model to classify first-order logic statements, and each new attempt was showing a bit more clearly than the last that my models were completely unable to learn to perform actual first-order logic -- despite the fact that this ability was definitely part of the representable function space. Instead, the models would inevitably latch onto statistical keyword associations to make their predictions.
It has been fascinating to see this observation echo again and again over the past 8 years.
Video generation models and Neural Radiance Fields have been improving regularly since 2016, and now they're in the spotlight. As a result there's a been a lot of debate about whether such systems embed a *model of physics*. Let's take a look...
in what fucking world can i text prompt a hollywood-level, blockbuster movie-like scene but i can't prompt a simple ui mockup?
ai was supposed to take MY job not christopher nolan's why am i still working
Have you ever done a dense grid search over neural network hyperparameters? Like a *really dense* grid search? It looks like this (!!). Blueish colors correspond to hyperparameters for which training converges, redish colors to hyperparameters for which training diverges.
People seem to be falling for two rather thoughtless extremes:
1. "LLMs are AGI, they work like the human brain, they can reason, etc."
2. "LLMs are dumb and useless."
Reality is that LLMs are not AGI -- they're a big curve fit to a very large dataset. They work via memorization and interpolation. But that interpolative curve can be tremendously useful, if you want to automate a known task that's a match for its training data distribution.
Memorization works, as long as you don't need to adapt to novelty. You don't *need* intelligence to achieve usefulness across a set of known, fixed scenarios.
In fact, that's the entire story of the field of AI so far: achieve increasing levels of usefulness and automation, while bypassing the problem of creating intelligence.
NEW: an ideological divide is emerging between young men and women in many countries around the world.
I think this one of the most important social trends unfolding today, and provides the answer to several puzzles.
I authored a critique paper titled "Large Language Models Cannot Self-Correct Reasoning Yet" (https://t.co/jqF94glBHN) 20 days ago.
I’ve observed two distinct groups misinterpreting the content in two different ways:
For LLM Critics: "LLMs Cannot Self-Correct Reasoning" != "LLMs Cannot Reason"
Consider an individual capable of reasoning but who provides an incorrect solution to a problem and fails to correct their own error. This incapacity for self-correction does not negate their reasoning ability. I did, however, express doubts about whether LLMs can genuinely reason in my survey paper last year (https://t.co/tAKoeQzgKg).
For LLM Enthusiasts: Leveraging external feedback for improvement does not equate to LLMs having the capacity to "self"-improve. High-quality external feedback is often unavailable, and even when it is, it may not be characterized as "self"-critique but rather as "critique with external feedback".
My Two Cents:
1) Avoid overclaiming your results;
2) Do not exaggerate your "critique"; otherwise, you become no different from those who overstate their results.
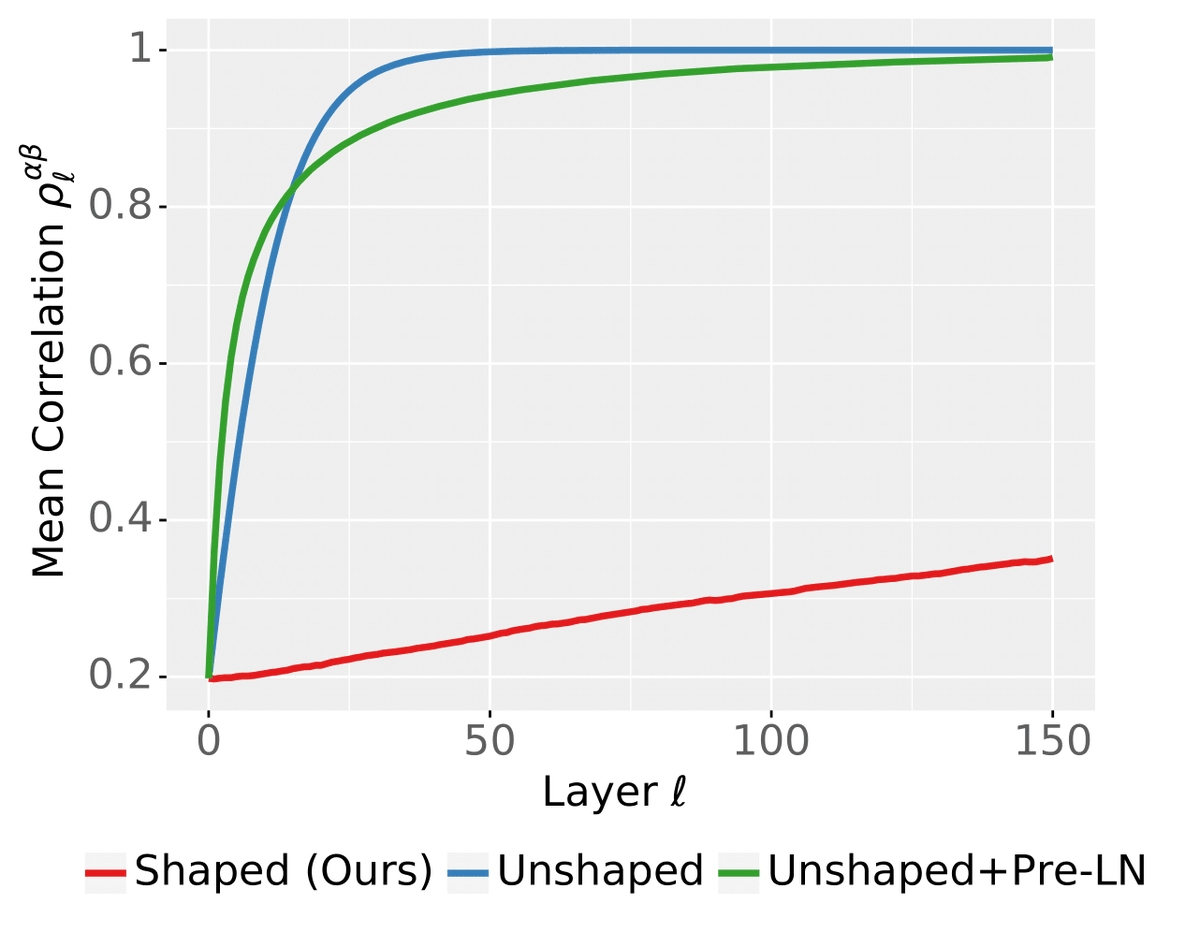
How do you scale Transformers to infinite depth while ensuring numerical stability? In fact, LayerNorm is not enough.
But *shaping* the attention mechanism works!
https://t.co/4DbIfYMQr3
w/ @ChuningLi@mufan_li@bobby_he@THofmann2017@cjmaddison@roydanroy
If AI ethicists need a doctorate in CS to be qualified to critique AI, then AI researchers need to have a doctorate in ethics/humanities/philosophy/HCI/etc. to be qualified to build AI.
A statement by the ELLIS Board: In this text, the members of the ELLIS Board share their view on the global conversation about the societal risks of #AI.
➡️https://t.co/Mpl57yR4BJ