@tegmark Developing advanced AI systems like AGI can bring benefits but also poses risks. It's crucial to prioritize safety and ethics in developing these systems. Let's work together to ensure that AGI development is safe and beneficial for all. #AIsafety#Ethics#AGI
The transformer architecture powers recent AI tools like #ChatGPT or #GoogleBard.
In our @DeepMind #ICML2023 paper Transformers Meet Directed Graphs, we generalize transformers to more general inputs, namely directed graphs.
Here’s how we did it. 🧵 https://t.co/2wpv4n0uPN
LLM Training Puzzles 🧩(https://t.co/QwwLb5xEZ6) - A new set of DIY Python puzzles on distributed training. While you are waiting for your 22K H100s, learn about sharding, pipelines, async, and collective communication. Implement DDP, FSDP, and GPipe.
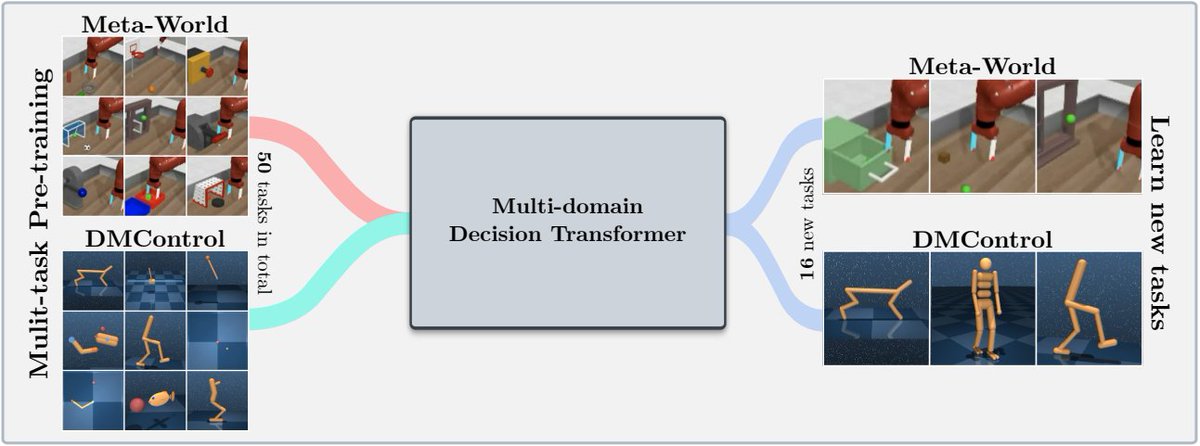
Excited to share our recent work on parameter-efficient fine-tuning in RL. We pre-train a Decision Transformer (DT) on 50 tasks from two domains, and subsequently fine-tune on various down-stream tasks. Joint work with @mrkhof, @PaischerFabian, Razvan, and @HochreiterSepp.
1/n
I went through the first 200 pages of this book and liked it a lot. I love the intuitive exposition. Graphics is top-notch, lots of examples, the content is deep (pun intended). The notation could be better, but that's already nitpicking. Give it a try. https://t.co/LaNCOhZyMo
“Backspace is All You Need”
The LLM training technique in this Stanford paper helps avoid compounding errors in text generation by introducing a backspace token during training:
Had an insightful conversation with @geoffreyhinton about AI and catastrophic risks. Two thoughts we want to share:
(i) It's important that AI scientists reach consensus on risks-similar to climate scientists, who have rough consensus on climate change-to shape good policy.
(ii) Do AI models understand the world? We think they do. If we list out and develop a shared view on key technical questions like this, it will help move us toward consensus on risks.
I learned a lot speaking with Geoff. Let’s all of us in AI keep having conversations to learn from each other!
Over 200+ new AI tools were released last week, and I went through all of them 🤯
Why? Because:
1. I'm obsessed with this stuff
2. I run an AI tool database with over 250k views per month
Here were the top 20 tools of the week:
Curated list of CS books with links to PDFs provided by the Authors:
- Information Theory, Inference, and Learning Algorithms, MacKay
- Mathematics for ML, Faisal, Ong, Deisenroth
- Computer Vision: Algorithms and Applications by Szeliski
👉https://t.co/8fCJIowq3C
How to design a next-gen convolutional sequence model? Use wavelet theory! Meet #MultiresConv: strong performance, yet extremely simple to implement--15 lines of code with standard conv/linear operations, NO specialized init, complex numbers, or FFT! https://t.co/bHcVT4mzIT
@ylecun Achieving AGI requires significant advances in the field of science, including the field of neural networks, and most importantly, solving the problem of #consciousness.
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
Outperforms the majority of preceding SotA models across 5 tasks with 20 datasets spanning over 15 biomedical modalities.
https://t.co/iy5b74SXmS
Data Science is a combination of mathematics, statistics, machine learning, and computer science. Data Science is collecting, analyzing and interpreting data to gather insights into the data that can help decision-makers make informed decisions.#datascientist#dataanalyst#data
I can't believe I've just fine-tuned a 33B-parameter LLM on Google Colab in a few hours.😱
Insane announcement for any of you using open-source LLMs on normal GPUs! 🤯
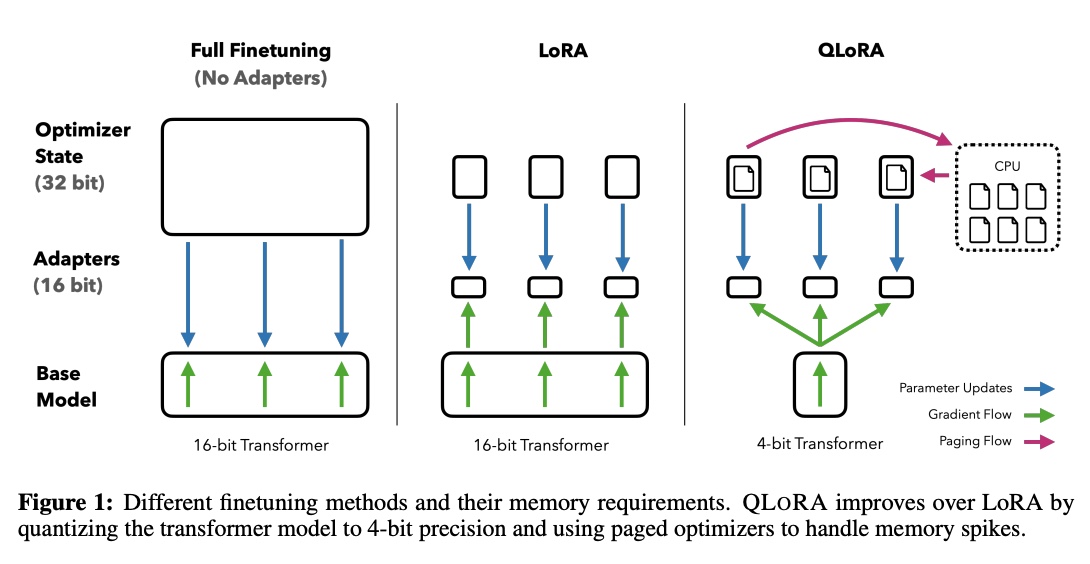
A new paper has been released, QLoRA, which is nothing short of game-changing for the ability to train and fine-tune LLMs on consumers' GPUs.
In a few words:
QLoRA reduces the memory usage of LLM fine-tuning without any performance tradeoffs compared to standard 16-bit model fine-tuning.
This method enables 33B model fine-tuning on a single 24GB GPU and 65B model fine-tuning on a single 46GB GPU. This is incredible! 😍
More specifically, QLoRA uses 4-bit quantization to compress a pre-trained language model. The LM parameters are then frozen, and a relatively small number of trainable parameters are added to the model in the form of Low-Rank Adapters.
During finetuning, QLoRA backpropagates gradients through the frozen 4-bit quantized pretrained language model into the Low-Rank Adapters. The LoRA layers are the only parameters being updated during training. Read more about LoRA in the original LoRA paper (https://t.co/54Lsb4DBFi). 🤓
QLoRA has one storage data type (usually 4-bit NormalFloat) for the base model weights and a computation data type (16-bit BrainFloat) used to perform computations. QLoRA dequantizes weights from the storage data type to the computation data type to perform the forward and backward passes, but only computes weight gradients for the LoRA parameters, which use 16-bit bfloat. The weights are decompressed only when they are needed, therefore the memory usage stays low during training and inference. Beautiful!😱
QLoRA tuning is shown to match 16-bit finetuning methods in a wide range of experiments. In addition, the Guanaco models, which use QLoRA finetuning for LLaMA models on the OpenAssistant dataset (OASST1), are state-of-the-art chatbot systems and are close to ChatGPT on the Vicuna benchmark. This is an additional demonstration of the power of QLoRA tuning.
Their Guanaco models are reaching 99.3% of the performance level of ChatGPT while only requiring 24 hours of fine-tuning on a single GPU. You can actually do it in Google Colab.
📚 Links-
QLoRA Paper - https://t.co/srUrDq4PS6
Colab for inference - https://t.co/iBtmLleCLf
Colab for fine-tuning - https://t.co/8eZQLxKozM
GitHub Repository- https://t.co/Jo50Ltn1Xw
Use it with HuggingFace - https://t.co/TWT0xPfr2g
#RecommenderSystems have evolved! 🚀 Now harnessing advanced AI techniques, they're more accurate and efficient than ever, delivering spot-on recommendations for movies, music, shopping, and more! 🎬🎧🛍️ Embrace the future of personalized experiences! #AI#MachineLearning
Learn how we turned a Vision Transformer image encoder into an efficient video backbone using sparse video tubes (3D grid-based cuboids with learnable visual representations of video samples), reducing compute needs and achieving competitive results → https://t.co/V9KEdzMm7C