What’s at Knowledge 2026 that you can’t find anywhere else? Hands-on learning, interactive demos, and real examples of how your peers are putting AI to work—and getting ahead. Register early for $400 off. (Hurry! Offer ends 12/31) https://t.co/SCs1DE48gY
@ServiceNow is one of @LinkedIn's Top Companies in the U.S.!
Proud to be part of a team that makes the world work better for everyone as we grow our careers, build new skills, and thrive in a culture that puts people first. Join us: https://t.co/wC4Y7qFQWp
#LinkedInTopCompanies
The new 100k token model from @AnthropicAI is awesome: dump in giant docs/books into the prompt, do LLM tasks! 📚🛠️
It got me thinking about the relationship to fine-tuning and in-context learning - is it better than both, worse than both, or used in niche cases? 🧵
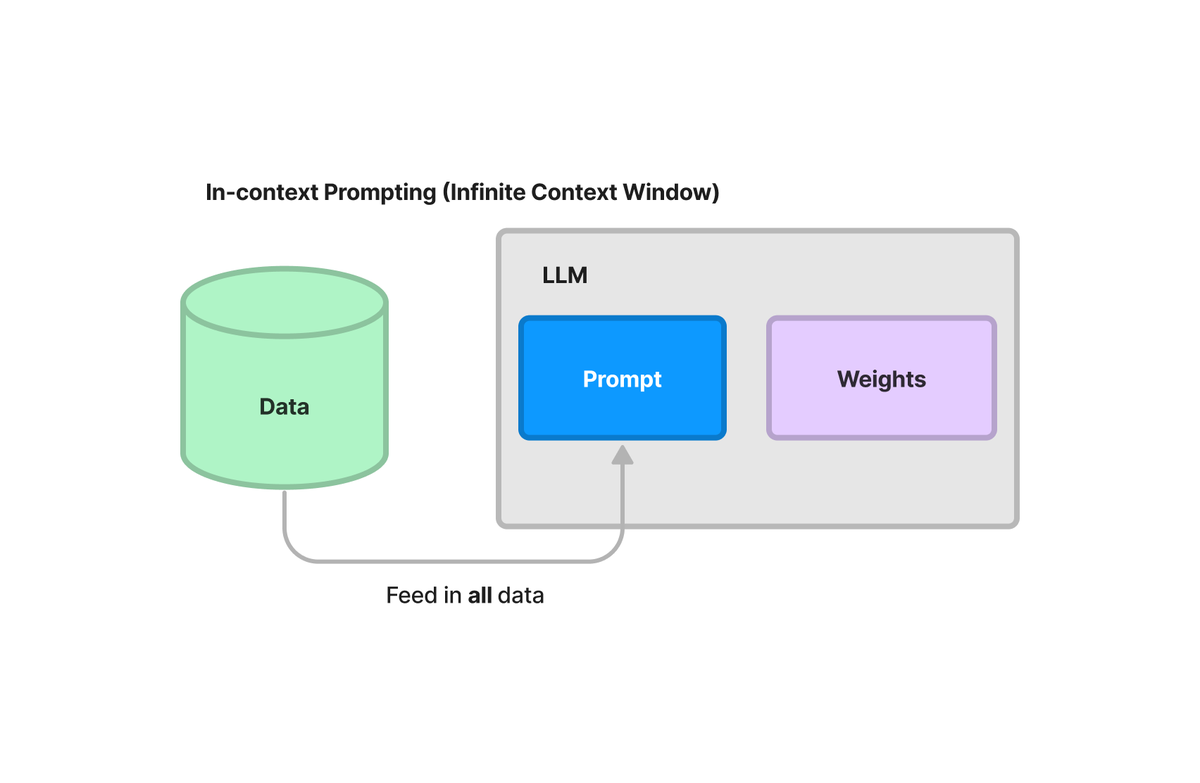
In the extreme, if context windows are infinite, then putting all the data into the prompt seems similar to “throw-away” fine-tuning 🤔
Pros ✅:
- Similar to fine-tuning, you get benefits of explicitly giving this black-box model access to all your knowledge (just in the inputs instead of in the weights)
- Less hand-engineered than retrieval-augmented generation (RAG)
- You can more easily feed in new data than actually fine-tuning (which seems hard to use)
Cons ❌:
- You have to feed in this data for every inference call
- As a result, marginal cost/latency go way up. 💵
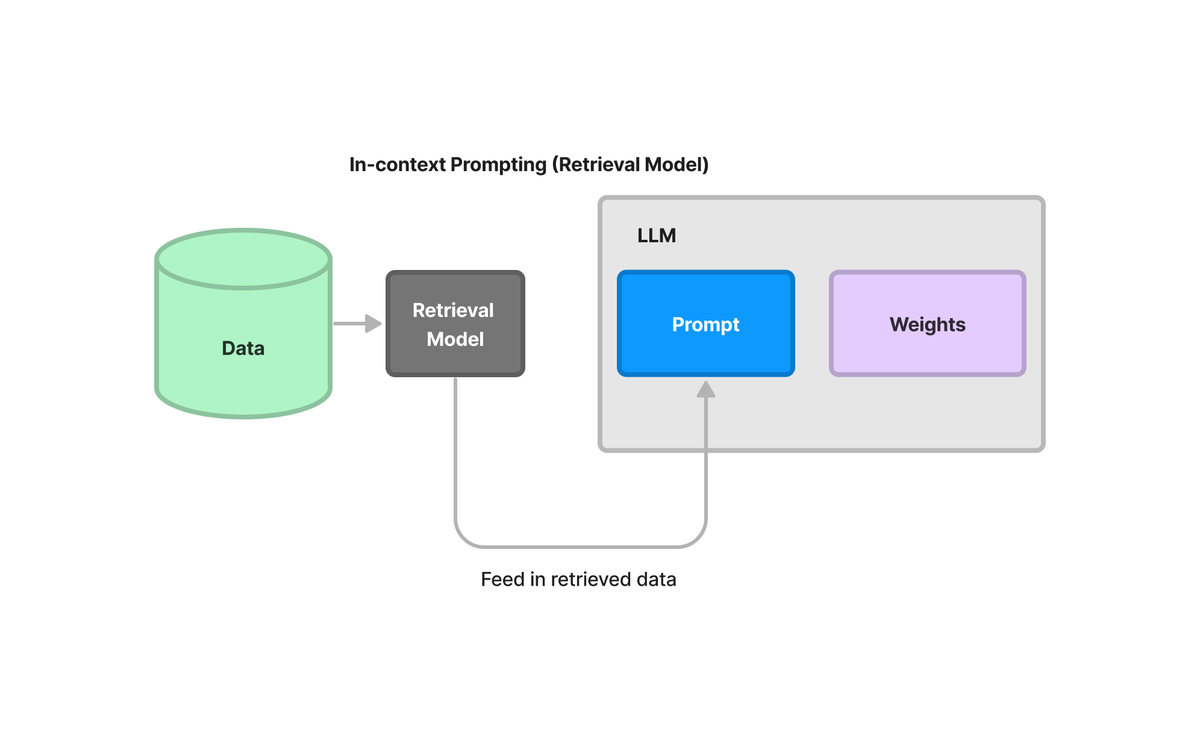
Retrieval augmented generation is more limited in functionality (because inherently requires some hand-engineering and data pipelining), but on the other hand can reduce cost/latency. So is this approach of feeding everything into the input prompt a happy middle or worst of both worlds?
Of course, going back to the context window of 100k: 100k tokens is a lot, but if you have gigabytes or terabytes of data, 100k tokens can’t fit everything (it can’t actually fit UBER SEC filings). So either way you will need to do some retrieval from your data, in the absence of fine-tuning. And then the question becomes whether you'll always want to maximize the context window, or you're ok with retrieving smaller chunks.
Thoughts? Added some diagrams below to help clarify my thinking 🖼️
Exciting news! Join me this Saturday for the "Inspiring and Mentoring Women in STEM" event hosted by the Joy Thomas Foundation.
Featuring keynote speaker Vidita Vaidya, a renowned neuroscientist and professor, and Tanishka Kabra, the recipient of the 2nd…https://t.co/d8thCKhAY3
Knowledge 2021 will feature more than 500 digital sessions across 12 channels. Familiarize yourself with our platform before you go. #Know21 https://t.co/SroLGERKJ5
Excited to officially announce that Parlo has been acquired by ServiceNow!
Parlo's #enterprise#NLU engine will enhance ServiceNow’s native #AI capabilities across its Now Platform and products, making getting work done as easy as…https://t.co/R9OsNuo2zE https://t.co/bO9Uu93seA