Postdoc @ University of Zagreb | previously postdoc @ Technion and UKP Lab, TU Darmstadt | PhD @ TakeLab, UniZG | Working on interpretability & safety of LLMs.
🚨🚨 New preprint 🚨🚨
Ever wonder whether CoTs correspond to the internal reasoning process of the model?
We propose a novel parametric faithfulness approach, which erases information contained in CoT steps from parameters to assess CoT faithfulness.
https://t.co/WZDUZbJbxC
With the large influx of submissions and a faster pace of research, reproducibility is more important than ever.
With this reproducibility challenge, we want to put the focus on best practices wrt. baselines🧱, ablations🌈, eval🔎 and generalizability🗺️ of interpretability!
📣 Announcing the BlackboxNLP 2026 Reproducibility Challenge!
A new track dedicated to rigorous robustness checks of NLP interpretability work - stress-testing baselines, ablations, generalizability, and evaluation.
📣 Announcing the BlackboxNLP 2026 Reproducibility Challenge!
A new track dedicated to rigorous robustness checks of NLP interpretability work - stress-testing baselines, ablations, generalizability, and evaluation.
Can we tell when LLMs are being unfaithful in their chains of thought?
We evaluated 8 methods claiming to do this, and found that most perform near chance!
But evaluating this requires us to have ground-truth labels for CoT faithfulness. How can we obtain these?
📢📢
I'm expanding my group at the ELLIS Institute Tübingen and the Max Planck Institute for Intelligent Systems and hiring 3-4 PhD students, and also visiting PhD students for funded 3-6 months stays ✨💥
Research areas broadly span the safety, security, and trustworthiness of AI agents including:
• Sycophancy, decision-making, and societal implications of AI
• Autonomous agents and memory
• Multi-agent safety, security, and privacy
• Training dynamics of LLMs
• AI control and oversight
• AI for science
I'm looking for:
- Visiting PhD students with a strong computer science background and research experience.
- Students with a Master's degree and demonstrated research experience.
What we offer in Tübingen: amazing compute, collaborators, environment, and a lovely town!
If you're interested, please fill out the Google form on my website: https://t.co/oCryUUIIUR
@ELLISInst_Tue@MPI_IS
#phd #AIsafety
NLAs are claimed to verbalize model activations. But can they faithfully interpret steered activations?
In our latest paper, we show that steering moves activations into non-invertible regions; and almost surely, no prompt maps to steered activations!
NLAs fail to interpret steered activation states faithfully, supporting our results! ↓
@anqi_liu33@DanielKhashabi
https://t.co/EANMNuQ1rL
@NitCal The best viewpoint I've seen on this. I'd even be more blunt and say that it is just disrespectful to hand over AI generated content which you have not verified.
Use AI tools, but check their outputs and respect others' time.
My advisor always says time is our most valuable resource,
I tell students I teach/work with that I dont plan to spend more time reading something than the author spent writing it.
I support arXiv's decision.
Asking authors to polish AI-generated content is a *VERY* low bar.
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
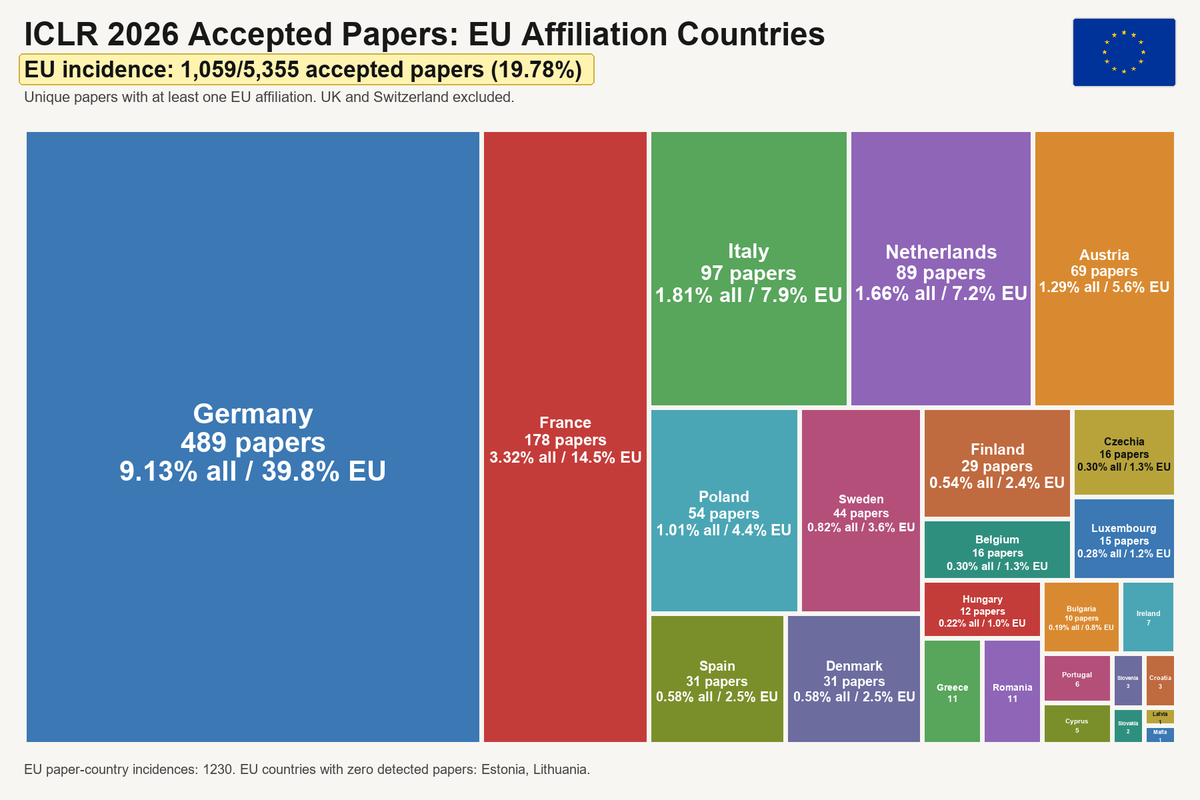
i ran an analysis of EU-affiliated papers at ICLR 2026. the picture is less negative than the original (quoted) treemap may suggest, but still, Europe needs to wake up.
1,059 out of 5,355 papers have at least one EU affiliation. that's a 19.78% incidence on all accepted papers.
If we count each paper once for every EU country represented among its authors, the total rises to 1,230 paper-country incidences.
Germany leads by a large margin, followed by France and Italy (daje). as an Italian, i'm genuinely happy to see Italy so high in the ranking, our investments in national talent is paying off.
this seems to correlate with the acceptance rates in competitive funding schemes like the ERC grants. i'd be curious to know whether similar patterns also appear in other non-AI fields, happy to hear thoughts from my @yacadeuro colleagues on this.
also, @EU_Commission, feel free to use the data.
personally i find it great to see Poland growing so strongly; there is real talent there. Austria is also becoming increasingly visible, helped by new, forward-looking institutions.
i'll rerun this analysis for ICML in a couple of months. curious to see whether the same pattern holds.
edit: fixed Austria counting.
Our work has been accepted at ICML 2026!🎉
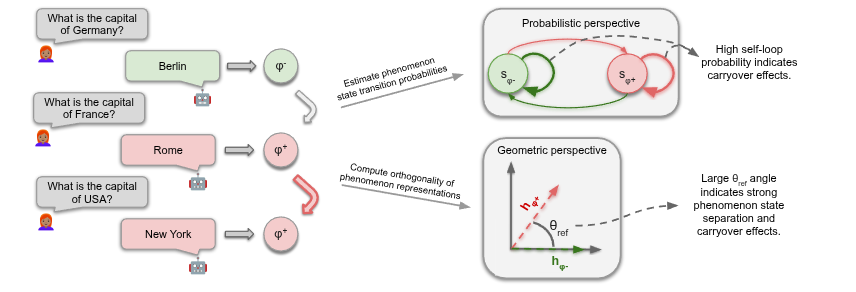
Ever wondered how an LLM's conversational past influences its future, both mechanistically and behaviorally?
We found that conversational history creates a "geometric trap" in the model's latent space!
Ever wondered what pathways steering vectors work through to affect model outputs, or whether different steering methods are functionally similar? We also find that steering vectors can be sparsified *a lot*.
Check out our recent preprint, led by Stephen: https://t.co/lnMSbOz7hR
Now accepted to ICML 2026 @icmlconf#ICML!
Check out our work where @AdiSimhi analyzes LLMs propensity to repeat behavior such as hallucinations, sycophancy and refusal - both behaviorally & mechanistically.
I'll go to Seoul, LMK if you'll also be there!
How does an LLM’s past influence its future?🤔
In our new paper with @FazlBarez,@mtutek,@boknilev, Shay Cohen, we show that conversational history creates a "geometric trap" in the latent space, confining the model’s trajectory➡️making old habits e.g. hallucinations hard to break
Qwen first release on interpretability (qwen scope) is very interesting
they use SAE features to identify what causes repetition in model outputs, then use steering to manufacture a "bad" rollout where the model repeats a lot. this gives RL a clear negative signal to learn from, since repetition barely shows up in normal rollouts so the model never gets punished for it
they also use SAE features as a fingerprint for benchmarks, you look at which features each benchmark activates and compare overlap. lets you find redundancy inside a benchmark and across benchmarks without running any model. for instance 63% of GSM8K features are in MATH but only 10% the other way