[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: https://t.co/mkkqr0KN4X
Many thanks to @_galyo@bd_eyal@zorikgekhman@eran_ofek59358@GoogleResearch
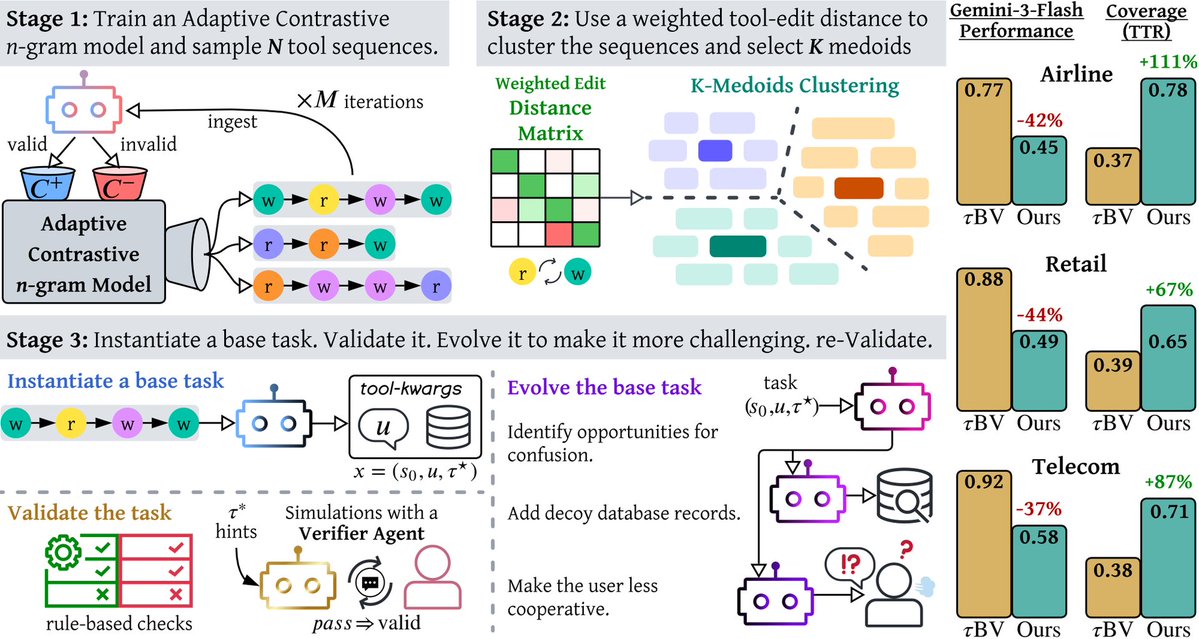
A matter of TASTE
Current agent benchmarks are saturated. TASTE reverses how they're built—starting from tool sequences, not hand-written scenarios.
Models scoring 90% on current tests crash to 30% on TASTE, facing 2× more tool combinations.
Our posting for joining Google DeepMind as a Research Scientist was down for a few days but now it is back up!
Apply here: https://t.co/Yk5iMbMQPu
And fill out this form: https://t.co/zdeqryH3hB
We build on existing work showing that frontier performance on all sorts of transfer is more inconsistent than we might hope, especially after learning from trillions of tokens:
https://t.co/mYBiTyVoWk @NitCal
https://t.co/Au95cAwhWX @omerNLP
https://t.co/AC6IahZYI4 @LChoshen
Preprint 🧵! How compartmentalized are LLMs?
For data in different formats (English/Chinese, Wiki/Q&A), how much transfer occurs? We provide evidence that LLMs can struggle with this sort of transfer, with consequences like sample inefficiency and capacity competition.
🚨 New preprint alert! 🎨
How do image editing models handle "make it look like a rainy day" vs. "add an umbrella"? While visual models excel at explicit commands, interpreting abstract instructions remains a major bottleneck.🧵👇 [1/10]
@Moshe_Friedman_ למה אתה מאמין בקוד? למה שאחרים יאמינו לאנליזה שלך?
לא הייתה פעם אחת שאנליזה שנעשתה עם LLMs שהציגו לי סטודנטים הייתה נכונה מא' עד ת'. תמיד היתה שם פונקציונליות סמויה ושגויה שהם בכלל לא היו מודעים לה (למשל התמודדות עם ערכים חסרים, משקול, שינוי מחלקות...)
@ziv_ravid@Tyler_Menzer Do you truly trust authors who didnt verify their citations to also verify the AI-generated code or analysis? I dont. Once I see signs of slop, it becomes hard to trust anything else in the paper.
My advisor always says time is our most valuable resource,
I tell students I teach/work with that I dont plan to spend more time reading something than the author spent writing it.
I support arXiv's decision.
Asking authors to polish AI-generated content is a *VERY* low bar.
Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
@yanaiela I would bet that there is a very high correlation between unpolished papers and unreliable results. If an author can't be bothered to proofread the text, I don't trust that they verified their AI-generated analysis.
@ziv_ravid Why? Polishing/checking AI-generated content is a very minimal requirement. The steep punishment is a good way to ensure this. PIs' students should be scared to death of uploading AI-slop papers.
1/7
How are cells spatially reorganized between conditions in tissues?
Introducing CASEI: a method for inferring condition-associated spatial phenotypes in spatial omics data.
w/ Roy Friedman (https://t.co/qm7qK1lBlS) & @mor_nitzan
https://t.co/9SNJZKsOkD
.@NitCal will be presenting "Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality" at ICML 2026 next month.
(tl;dr: we show encoding is near-saturated on frontier LLMs, but models still struggle to recall encoded facts.)
One recurring piece of feedback we've gotten since posting the paper: "you show LLMs struggle with factual recall, but does that even matter when today's agents can use external retrieval?"
Here's how I currently think about this, and more broadly about the role of parametric knowledge in today's systems:
The theoretical argument for why knowledge matters (true in principle, but I don't know of work that measures this in practice): parametric knowledge is important for making efficient use of search and for knowing how to properly integrate retrieved information. Imagine finding some weird pizza recipe online — can you trust it without knowing a lot about cooking, chemistry, etc.? I think this is going to become a bigger issue moving forward, the more "sloppier" the internet becomes.
The realistic case for why knowledge matters: today's agents are far from producing responses that are fully grounded in external evidence. Even when search triggers properly — which it often doesn't — only the "big" claims tend to be grounded, while models still volunteer a lot of extra information from their parametric knowledge.
Since models are still poor at "knowing what they know" (more on that in my next post, about our other ICML paper...), our best bet is making models actually more knowledgeable — and our paper reveals where the headroom for that actually lies.
.@NitCal will be presenting "Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality" at ICML 2026 next month.
(tl;dr: we show encoding is near-saturated on frontier LLMs, but models still struggle to recall encoded facts.)
One recurring piece of feedback we've gotten since posting the paper: "you show LLMs struggle with factual recall, but does that even matter when today's agents can use external retrieval?"
Here's how I currently think about this, and more broadly about the role of parametric knowledge in today's systems:
The theoretical argument for why knowledge matters (true in principle, but I don't know of work that measures this in practice): parametric knowledge is important for making efficient use of search and for knowing how to properly integrate retrieved information. Imagine finding some weird pizza recipe online — can you trust it without knowing a lot about cooking, chemistry, etc.? I think this is going to become a bigger issue moving forward, the more "sloppier" the internet becomes.
The realistic case for why knowledge matters: today's agents are far from producing responses that are fully grounded in external evidence. Even when search triggers properly — which it often doesn't — only the "big" claims tend to be grounded, while models still volunteer a lot of extra information from their parametric knowledge.
Since models are still poor at "knowing what they know" (more on that in my next post, about our other ICML paper...), our best bet is making models actually more knowledgeable — and our paper reveals where the headroom for that actually lies.
Our paper got accepted to @icmlconf! 🥳🥳
I also want to say a few warm words about the reviewers and AC. Maybe because our paper was under Policy A (LLM use is prohibited), but the review process felt unusually professional and refreshing, almost like a reminder of pre-2024 peer review 😇
I hope more authors get to experience this kind of review process in the future.
[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: https://t.co/mkkqr0KN4X
Many thanks to @_galyo@bd_eyal@zorikgekhman@eran_ofek59358@GoogleResearch
Proud of being part of Google Translate (even if it was for a few months as an intern, almost a decade ago!). One of the most fun and rewarding professional experiences of my life, in a truly revolutionary team. PS not many know but lots of the groundwork to LLMs happened there!
🚨New Paper (ACL-26)
'Efficient Agent Evaluation via Diversity-Guided User Simulation'
We tackle a core pain in agent evaluation:
Current methods aim for coverage (pass@k) but mostly re-run the same conversations → low diversity, high cost.
We're excited to introduce DIVERT 🧵
Do LLMs have motivation?
Motivation is a key lens for explaining human behavior.
As LLM behavior becomes more human-like, a natural question arises: could it help understand model behavior too?
With @AsaelSklar@GoldsteinYAriel@roireichart
📄 Paper: https://t.co/cdh2qmGNmE
1/5


























![NitCal's tweet photo. [1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: https://t.co/mkkqr0KN4X
Many thanks to @_galyo @bd_eyal @zorikgekhman @eran_ofek59358 @GoogleResearch](https://pbs.twimg.com/media/HB7baIgWMAA4hYA.jpg)