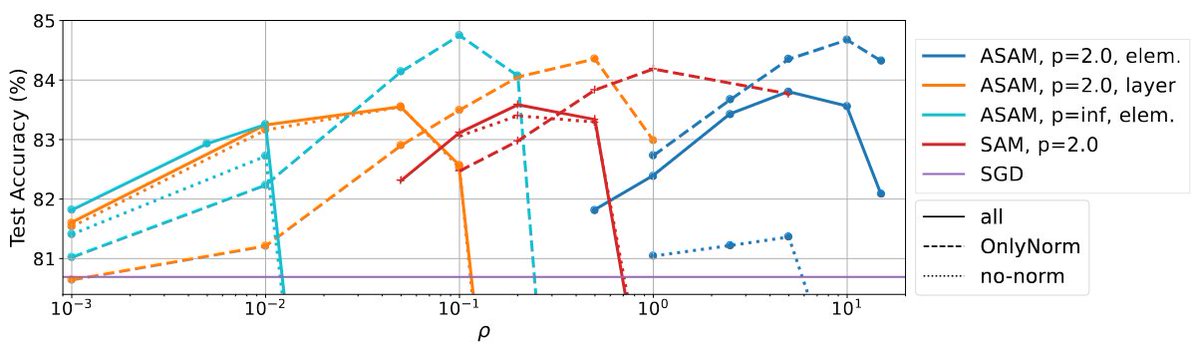
‼️ New paper: Normalization Layers Are All That Sharpness-Aware Minimization Needs ‼️
https://t.co/ch1Xibq6yx
We show that applying SAM only to the normalization layers of a network (SAM-ON) enhances performance compared to applying it to the full network.
💥I’m very excited to announce Exponential Security Labs: our new agent security startup based in Tübingen!
Now everyone is deploying agents for increasingly high-stakes applications. Yet their reliability and security remain unsolved technical problems. Our mission is to secure agentic systems through self-improving red-teaming and guardrail agents.
Tübingen is a special place to build a company in this space due to its incredibly high concentration of AI safety talent (ELLIS Institute, MPI-IS, University of Tübingen). Reach out if you're interested—we are hiring!
We are also looking for customers—please get in touch!
New paper: We introduce Visual Memory Injection, a new attack on large vision-language models. A subtly perturbed image, that remains in the chat context, causes the model to behave normally for many turns and later triggers a targeted harmful response on a topic-specific prompt.
📣 We are expanding our AI Safety and Alignment group at @ELLISInst_Tue and @MPI_IS! We have:
- a great cluster at MPI with 50+ GB200s, 250+ H100s, and many-many A100 80GBs,
- outstanding colleagues (@jonasgeiping, @sahar_abdelnabi, etc),
- competitive salaries (as for academia),
- fully English-speaking environment.
In particular, I'm looking for:
- one postdoc with a proven track record in AI safety,
- PhD students with a strong computer science background and ideally experience in cybersecurity, interpretability, or training dynamics,
- master’s thesis students (if you are already in Tübingen or can relocate to Tübingen for ~6 months),
- remote mentees for the Summer 2026 MATS cohort (apply directly via the MATS portal).
I'll be at NeurIPS in San Diego and would be glad to chat about these positions!
Happy to share that I've started as an assistant professor at @AaltoUniversity and ELLIS Institute Finland!
I'll recruit students via the ELLIS PhD Program https://t.co/WXLbi7BiZD to work on multimodal learning, robustness, visual reasoning... feel free to reach out!
Very promising results on *robust* unlearning from colleagues at Tübingen and EPFL.
(+ some general improvements to the standard evaluation by using an LLM judge and worst-case evaluation over paraphrases and input formats)
🚨 Incredibly excited to share that I'm starting my research group focusing on AI safety and alignment at the ELLIS Institute Tübingen and Max Planck Institute for Intelligent Systems in September 2025! 🚨
Hiring. I'm looking for multiple PhD students: both those able to start in Fall 2025 (i.e., as soon as possible) and through centralized programs like CLS, IMPRS, and ELLIS (the deadlines are in November) to start in Spring–Fall 2026. I'm also searching for postdocs, master's thesis students, and research interns. Fill the Google form below if you're interested!
Research group. We will focus on developing algorithmic solutions to reduce harms from advanced general-purpose AI models. We're particularly interested in alignment of autonomous LLM agents, which are becoming increasingly capable and pose a variety of emerging risks. We're also interested in rigorous AI evaluations and informing the public about the risks and capabilities of frontier AI models. Additionally, we aim to advance our understanding of how AI models generalize, which is crucial for ensuring their steerability and reducing associated risks. For more information about research topics relevant to our group, please check the following documents:
- International AI Safety Report,
- An Approach to Technical AGI Safety and Security by DeepMind,
- Open Philanthropy’s 2025 RFP for Technical AI Safety Research.
Research style. We are not necessarily interested in getting X papers accepted at NeurIPS/ICML/ICLR. We are interested in making an impact: this can be papers (and NeurIPS/ICML/ICLR are great venues), but also open-source repositories, benchmarks, blog posts, even social media posts—literally anything that can be genuinely useful for other researchers and the general public.
Broader vision. Current machine learning methods are fundamentally different from what they used to be pre-2022. The Bitter Lesson summarized and predicted this shift very well back in 2019: "general methods that leverage computation are ultimately the most effective". Taking this into account, we are only interested in studying methods that are general and scale with intelligence and compute. Everything that helps to advance their safety and alignment with societal values is relevant to us. We believe getting this—some may call it "AGI"—right is one of the most important challenges of our time.
Join us on this journey!
🚨 Incredibly excited to share that I'm starting my research group focusing on AI safety and alignment at the ELLIS Institute Tübingen and Max Planck Institute for Intelligent Systems in September 2025! 🚨
Hiring. I'm looking for multiple PhD students: both those able to start in Fall 2025 (i.e., as soon as possible) and through centralized programs like CLS, IMPRS, and ELLIS (the deadlines are in November) to start in Spring–Fall 2026. I'm also searching for postdocs, master's thesis students, and research interns. Fill the Google form below if you're interested!
Research group. We will focus on developing algorithmic solutions to reduce harms from advanced general-purpose AI models. We're particularly interested in alignment of autonomous LLM agents, which are becoming increasingly capable and pose a variety of emerging risks. We're also interested in rigorous AI evaluations and informing the public about the risks and capabilities of frontier AI models. Additionally, we aim to advance our understanding of how AI models generalize, which is crucial for ensuring their steerability and reducing associated risks. For more information about research topics relevant to our group, please check the following documents:
- International AI Safety Report,
- An Approach to Technical AGI Safety and Security by DeepMind,
- Open Philanthropy’s 2025 RFP for Technical AI Safety Research.
Research style. We are not necessarily interested in getting X papers accepted at NeurIPS/ICML/ICLR. We are interested in making an impact: this can be papers (and NeurIPS/ICML/ICLR are great venues), but also open-source repositories, benchmarks, blog posts, even social media posts—literally anything that can be genuinely useful for other researchers and the general public.
Broader vision. Current machine learning methods are fundamentally different from what they used to be pre-2022. The Bitter Lesson summarized and predicted this shift very well back in 2019: "general methods that leverage computation are ultimately the most effective". Taking this into account, we are only interested in studying methods that are general and scale with intelligence and compute. Everything that helps to advance their safety and alignment with societal values is relevant to us. We believe getting this—some may call it "AGI"—right is one of the most important challenges of our time.
Join us on this journey!
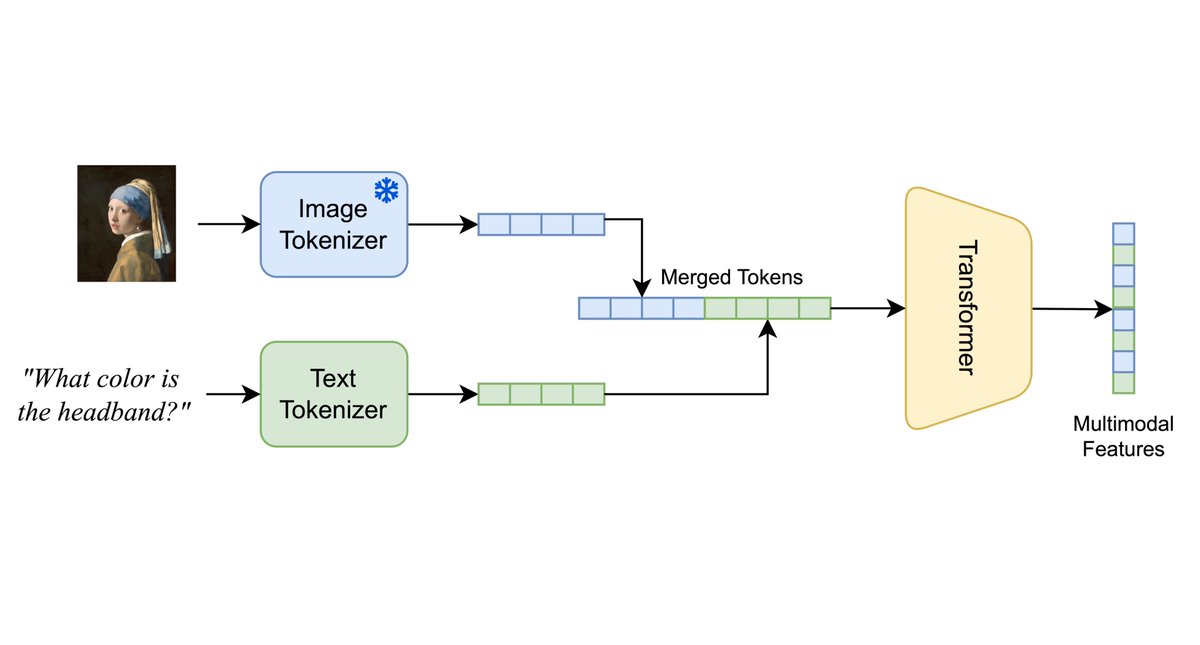
Excited to announce FuseLIP: an embedding model that encodes image+text into a single vector. We achieve this by tokenizing images into discrete tokens, merging these with the text tokens and subsequently processing them with a single transformer.
With @bremen79, We propose a new algorithm for constructing confidence intervals for means of bounded r.vs using "testing by betting" framework. It performs remarkably well even in the challenging, very small sample regime. (and of course, it is great in the large sample one)
This work now provides both an explanation and a (partial) solution to those observations.
More insights in the paper:
https://t.co/V64zJipIh7
Code:
https://t.co/RPSJNwx89f
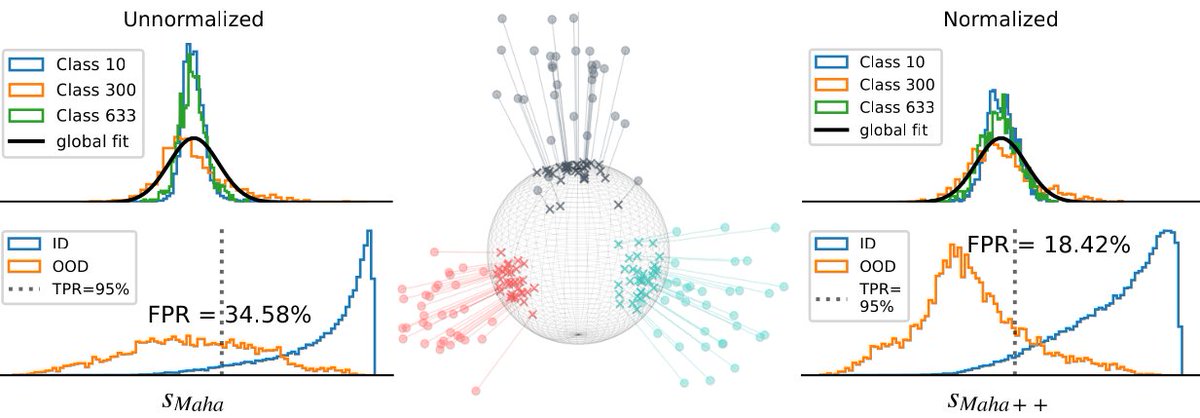
Mahalanobis++: Improving OOD Detection via Feature Normalization
Our latest work has been accepted to ICML and is now also on arXiv!
We explain why Mahalanobis-based OOD detection led to varied results and show that l2 normalization improves its performance consistently.
This connects several points from our previous work: We found that the Mahalanobis score yields SOTA results for some models on our NINCO benchmark, but fails for others. In a workshop paper, we found that the Mahalanobis score is very sensitive to training hyperparams (esp. lr).