DeepSeek just made its 75% price cut on V4-Pro permanent. Xiaomi's MiMo slashed V2.5 pricing by up to 99%, effective today. Most coverage frames this as a price war. The more interesting part is the engineering that makes these numbers sustainable.
DeepSeek's V4 paper describes a *hybrid attention architecture* that attacks the core bottleneck of long-context inference: the KV cache. Traditional transformers store key-value pairs for every token in the context. At 1 million tokens, this cache alone can fill an entire GPU's memory. V4 introduces two interleaved attention types.
Compressed Sparse Attention (CSA) compresses every 4 tokens into a single KV entry, then selects only the top-k most relevant compressed blocks per query. Heavily Compressed Attention (HCA) goes further, compressing 128 tokens into one entry and running dense attention over the result. The compressed sequence is short enough that dense attention stays cheap.
V4-Pro's KV cache at 1M tokens is 10% (!!) of V3.2's. Single-token inference FLOPs drop to 27% (!!). The model has 1.6 trillion total parameters but only activates 49 billion per token through Mixture-of-Experts routing, the knowledge capacity of a massive model at the compute cost of one thirty times smaller.
MiMo's approach is different but lands in the same place. Xiaomi's team implemented Sliding Window Attention via SGLang HiCache, reducing KV cache data transfer across GPU memory, CPU memory, and SSD to roughly 1/7 (!!) of previous volume. Cacheable tokens expanded by 5x (!!). Combined with expert parallelism optimization and input length bucketing, per-token serving cost dropped enough to make permanent pricing at these levels viable.
V4-Pro now sits at $0.87 per million output tokens. MiMo V2.5-Pro at roughly $3/M output, with Flash variants far below that. A year ago, sub-dollar output pricing meant you were using a small distilled model with real capability tradeoffs. These are frontier-class reasoners with million-token context windows.
Both companies can commit to permanent cuts because the reductions come from the architecture itself. When your attention mechanism physically processes fewer FLOPs per token and your cache occupies a fraction of the memory, the cost to serve is structurally lower. The price follows the cost curve.
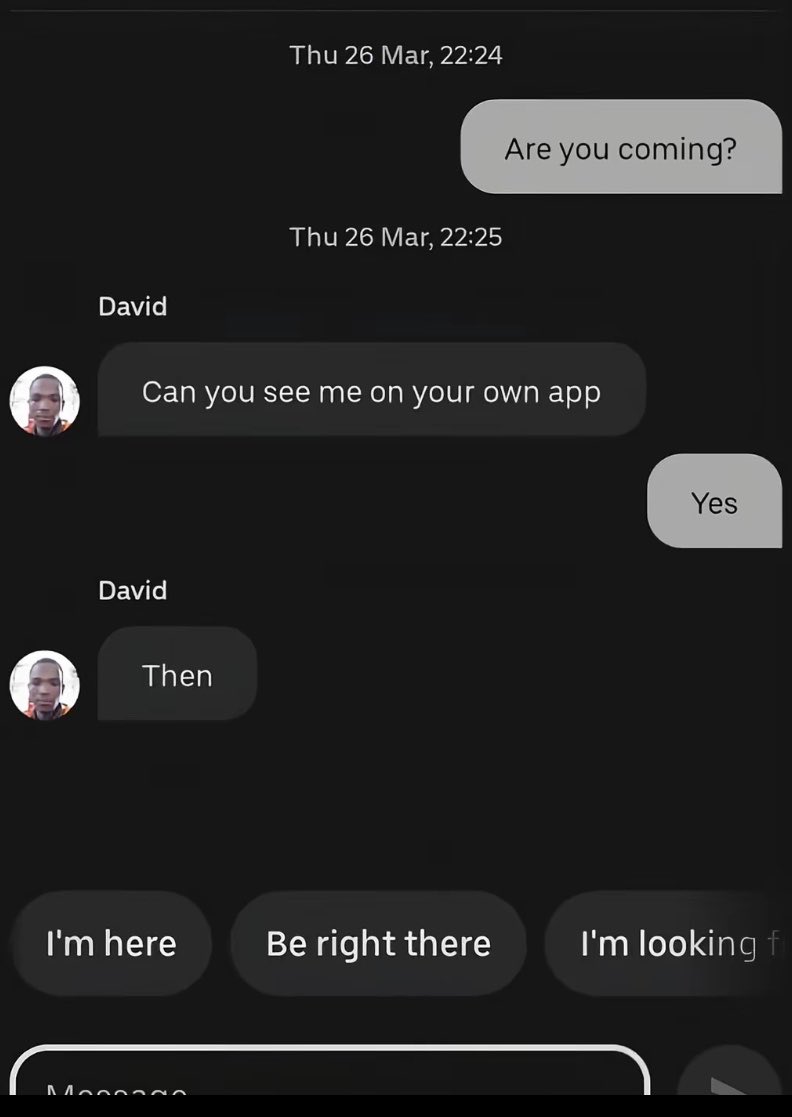
Had this at first but I opened a cron alert topic, ask your bot for the topic ID specifically, set all cron alerts there. Even when asking the agent about what's in the cron alert topic I tell it to leave the cron alerts there.
I’m currently using Telegram to chat with Hermes Agent.
It works well for normal conversations, but once you set up cron jobs for different topics, everything starts landing in the same place.
Feels like Discord channels per topic might be a cleaner setup.
Anyone using it that way? Suggest me the best way to manage things
#hermes
4 black kids were abducted by 16 Ecuadorian militaries and they burned their bodies. Ecuadors president did everything in his power to imply they weren’t innocent so they deserved it until Courts proven him wrong. The youngest was 11 & oldest 15.
im SO into the idea of skill exchanging (like exchanging baking lesson for piano lesson, bike maintenance lesson for programming lesson, etc) but i cannot find any platforms dedicated to this! do i need to make one! im very busy but dont tempt me i will!
We have a Nigerian woman as a politician serving one of the most racist parties in Europe whose main agenda is deportation of immigrants. As the only black woman there mind you.
Brother, with all due respect, you work for CNN. Your opinion is the least useful thing in the world - because it's not yours. Whatever Warner Media wants you to think is exactly what you will think because your paycheck depends on it.
Dance for your coins but please do so with sense.
Germans are very socially immature. The idea of honesty and "being direct" just stems from that. 90% of the time people will confront each other to complain or bitch about things than even say Hi. Most of the times it's nothing even worth bitching about.