Very happy to announce, that our last work "DIV-FF: Dynamic Image Video feature fields for egocentric vision" with
@rmcantin
and J.Guerrero, has been accepted at CVPR 2025!! https://t.co/p6UglbApSy
Take a look 👇🧵
@massiviola01 Any inshights of what is the performance drop so big in the ViT-Tiny? Is there any intermediate option between the tiny and the small ViTs?
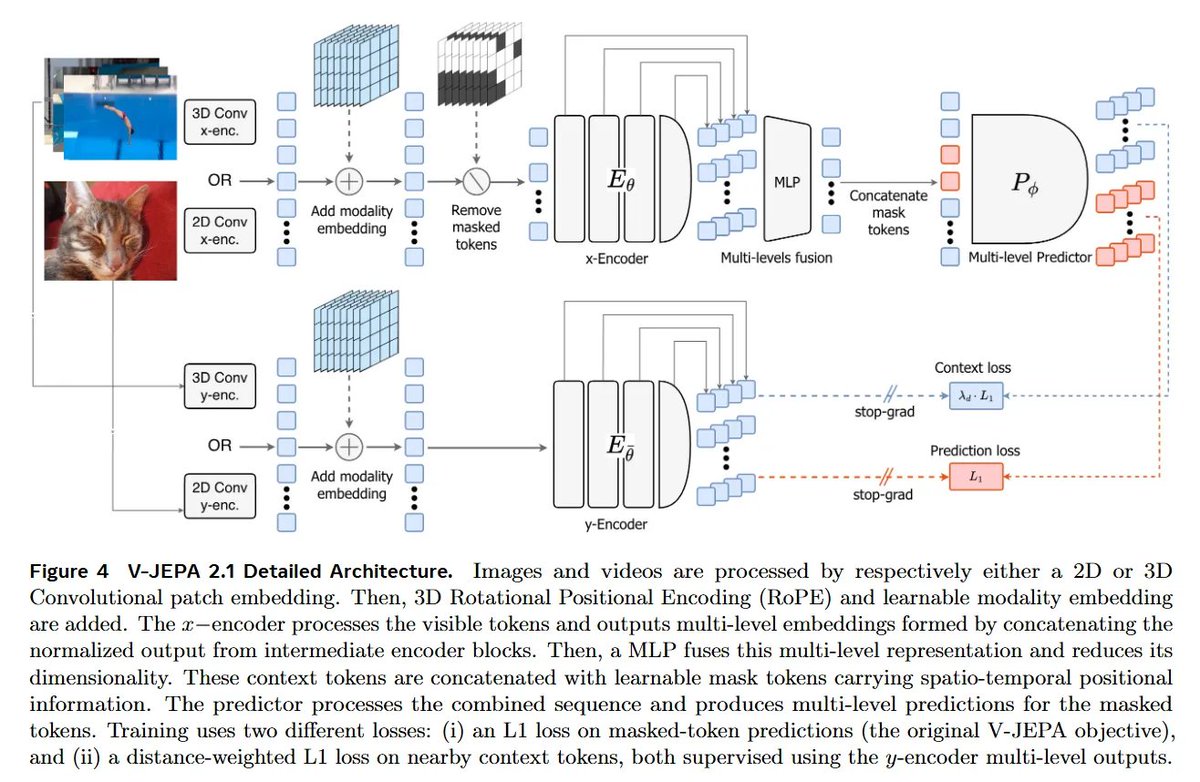
I am very happy to share the result of my internship at FAIR (Meta): V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning with @ylecun@AdrienBardes
Our approach learns dense, spatially coherent features from video while preserving strong global understanding
7/ The numbers are brutal. NYUv2 depth RMSE drops from an unusable 0.682 to SOTA 0.307. ADE20K segmentation mIoU jumps +23.4 points. Ego4D anticipation hits 7.71 mAP. PCA features go from noisy static to sharp object boundaries.
2/ V-JEPA 2.1 by Mur-Labadia, Muckley, and the FAIR team fixes the global-local representation bottleneck. It unifies image and video representation learning into a single encoder. This is a massive step for embodied AI world models.
Thread on VJEPA 2.1🤟
This DEFINITELY flew under the radar: just a few days ago, @AIatMeta released V-JEPA 2.1, taking a massive step toward closing the gap between image and video domains.
For a long time, image backbones were the only option for solving dense vision tasks. This model disagrees, showing that universal spatial understanding also emerges from large-scale video models!🎥
@ylecun@AdrienBardes Global video understanding is possible with excellent dense features!!
- 77.7 % Top-1 Acc on SSv2 (new SOTA, motion-metric dataset)
- Competitive 87.7 % on K400 and 85.5 % on Imagenet-1K
- Semantically coherent, spatially aligned and temporally consistent features
Yann LeCun and his team dropped yet another paper!
"V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning"
In this V-JEPA upgrade, they showed that if you make a video model predict every patch, not just the masked ones AND at multiple layers, they are able to turn vague scene understanding into dense + temporal stable features that actually understands "what is where".
This key insight drove improvements in segmentation, depth, anticipation, and even robot planning.
Introducing VL-JEPA: Vision-Language Joint Embedding Predictive Architecture for streaming, live action recognition, retrieval, VQA, and classification tasks with better performance and higher efficiency than large VLMs.
• VL-JEPA is the first non-generative model that can perform general-domain vision-language tasks in real-time, built on a joint embedding predictive architecture.
• We demonstrate in controlled experiments that VL-JEPA, trained with latent space embedding prediction, outperforms VLMs that rely on data space token prediction.
• We show that VL-JEPA delivers significant efficiency gains over VLMs for online video streaming applications, thanks to its non-autoregressive design and native support for selective decoding.
• We highlight that our VL-JEPA model, with an unified model architecture, can effectively handle a wide range of classification, retrieval, and VQA tasks at the same time.
by @Delong0_0@MustafaShukor1@TheoMoutakanni@willyhcchung Jade Lei Yu Tejaswi Kasarla @AllenBolourchi@ylecun@pascalefung
https://t.co/oUnjCaMKVv
Yann LeCun explains that large language models are trained on about 30 trillion words, representing nearly all public internet text.
He says it would take a human over 500,000 years to read that much.
But a 4-year-old child sees just as much visual data in their first few years of life.
This shows how much richer and more complex real-world experience is compared to reading text.
Training on the web is huge but it still doesn’t match what a child learns just by living.