Meet https://t.co/IE5t6g8klD
We build essential online utility tools with a simple philosophy: speed, absolute privacy, and rock-solid reliability. Developed by Muuocodes Labs to give you a cleaner, faster web experience.
I built https://t.co/IE5t6g8klD out of sheer frustration. The existing utility tools were broken, cluttered with invasive ads, and completely ruined my workflow. So, I built the clean, distraction-free solution I couldn't find anywhere else.
Elon Musk explains his 5-step algorithm for solving any problem:
"The most common mistake of smart engineers is to optimize a thing that should not exist."
"I have this very basic first principles algorithm that I run as a mantra."
Elon breaks it down:
Step 1: Question the requirements.
"Make the requirements less dumb. The requirements are always dumb to some degree, no matter how smart the person who gave you those requirements. You have to start there, because otherwise you could get the perfect answer to the wrong question."
Step 2: Try to delete it.
"Try to delete the part or the process step entirely. If you're not forced to put back at least 10% of what you delete, you're not deleting enough. Most people feel like they've succeeded if they haven't been forced to put things back in. But actually they haven't, they've been overly conservative and left things in that shouldn't be there."
Step 3: Optimize or simplify.
"The most common mistake of smart engineers is to optimize a thing that should not exist. So you don't optimize until after you've tried to delete."
Step 4: Speed it up.
"Any given thing can be done faster than you think. But you shouldn't speed things up until you've tried to delete it and optimize it otherwise, you're speeding up something that shouldn't exist."
Step 5: Automate.
"And then the fifth thing is to automate it."
Elon explains why the order matters:
"I've gone backwards so many times where I've automated something, sped it up, simplified it, and then deleted it. I got tired of doing that. So that's why I have this mantra."
Andrej Karpathy just sat down and built GPT from scratch, line by line, in 2 hours.
For Free. From the man who co-founded OpenAI.
This video is enough to become an AI engineer.
Bookmark it. Watch it tonight. Build your own GPT this week.
$5,000. $15,000. $40,000.
That's what bootcamps charge to teach less than what's in this 2-hour video.
This video fixes that this week.
Follow @codewithimanshu for more high-signal AI content that actually moves your engineering career forward.
↓
Karpathy doesn't explain GPT. He builds it.
Live. From "Attention is All You Need" the original paper. To the same architecture powering GPT-5.
Founding member of OpenAI in 2015. Senior Director of AI at Tesla. Now running Eureka Labs.
He's not teaching you how to use GPT. He's teaching you how it actually works at the source code level.
Most engineers will never understand transformers this deeply. The ones who do build the next generation of AI products.
Follow @codewithimanshu for breakdowns of every must-watch AI lecture worth your time.
↓
Here's what gets built in 2 hours. No fluff.
Tokenization and data loading.
The foundation of every modern LLM. Train/val splits done right. Batch loaders that don't break in production.
Most tutorials skip this. You can't ship anything serious without it.
The bigram baseline.
The simplest possible language model. Karpathy builds it first because it teaches you what every fancier model is actually trying to improve.
Once you understand bigrams, transformers become obvious. Skip this and the rest never clicks.
Follow @codewithimanshu for daily breakdowns of what AI engineers actually need to know.
↓
Self-attention. From scratch. Live.
This is the section that should have its own course.
Karpathy builds self-attention in 4 versions:
> Version 1: averaging past context with for loops
> Version 2: matrix multiply as weighted aggregation
> Version 3: adding softmax
> Version 4: full self-attention
Each version teaches you why the next one exists. Why attention works. Why matrix math replaces explicit loops. Why scaling matters.
You'll never look at "attention is all you need" the same way again.
Follow @codewithimanshu for production transformer breakdowns weekly.
↓
The 6 attention notes that change everything.
Karpathy drops 6 insights most engineers never hear:
> Attention as communication between tokens
> Attention has no notion of space, operates over sets
> No communication across batch dimension
> Encoder blocks vs decoder blocks
> Attention vs self-attention vs cross-attention
> Why we divide by sqrt(head_size)
Each one of these explains a different failure mode in production AI systems.
Most "AI engineers" can't answer these. The ones who can charge $300K.
Follow @codewithimanshu for the engineering insights that turn into job offers.
↓
Building the full transformer block.
Single self-attention head. Then multi-headed self-attention.
Feedforward layers. Residual connections. LayerNorm.
Each piece added with the reason it exists. Why residuals stop the model from collapsing. Why LayerNorm replaced BatchNorm. Why dropout matters at scale.
This is the architectural understanding that lets you debug any modern AI system.
Once you've built one transformer by hand, every paper you read becomes 10x clearer.
Follow @codewithimanshu for transformer architecture content every week.
↓
Scaling up to a real model.
Karpathy goes from baseline to a working GPT.
Hyperparameters. Dropout. Model dimensions. The exact tradeoffs every production model makes.
By the end you have a Shakespeare-generating language model running on your machine. From scratch. Built by you. Understood by you.
That's not a tutorial. That's an architectural unlock.
Follow @codewithimanshu for production model scaling breakdowns.
↓
Encoder vs decoder vs both.
The architecture choice that defines every modern AI product.
Why GPT is decoder-only. Why BERT is encoder-only. Why translation models use both.
Once you understand this, you can read any AI paper and immediately know what kind of system you're looking at.
This is the difference between someone who follows AI hype and someone who builds it.
Follow @codewithimanshu for AI architecture deep dives weekly.
↓
NanoGPT walkthrough.
Karpathy ends with a quick walk through nanoGPT. The repo every serious AI engineer has cloned at least once.
Batched multi-headed self-attention. Production-grade code. The clean version of everything you just built.
This is the bridge from "I built a toy GPT" to "I can read and modify production AI code."
Follow @codewithimanshu for repos every AI engineer should know.
↓
ChatGPT, pretraining, finetuning, RLHF.
The video closes with the full lineage. From your toy GPT to ChatGPT.
What changes when you scale up. Why RLHF matters. The exact path from research model to product.
You finish the video understanding the entire stack from raw paper to deployed product.
Most "AI experts" can't draw this map. After 2 hours, you can.
↓
What you'll be able to do after this.
Read "Attention is All You Need" and understand every line.
Debug attention layers when they break in production.
Build a custom language model on your own dataset.
Modify transformer architectures for specific use cases.
Have technical conversations with AI engineers without faking it.
Train a GPT on any data you want. Shakespeare. Code. Your own writing.
That's not "AI literacy." That's the foundation of an AI engineering career.
The kind of foundation that turns into senior roles and consulting contracts most people will never access.
↓
2 hours. Free. From the engineer who built it.
You'll spend longer in meetings this week and learn nothing.
This compounds for the rest of your career.
People who watch it can build GPT from scratch by Friday.
People who skip it stay confused about why their prompts fail in production.
Save the video. Watch it this week. Build something with the knowledge by the weekend.
Follow @codewithimanshu for more high-signal AI content from the people actually building the future.
ANTHROPIC JUST PROVED MOST PEOPLE HAVE NO IDEA HOW TO PROMPT CLAUDE.
Their applied AI team dropped a 24 minute free workshop.
Not a creator who reverse engineered it.
Not a Reddit thread.
ANTHROPIC.
The people who wrote the weights.
And what they showed is uncomfortable.
There are 6 elements to a properly structured Claude prompt.
Most people are using 1.
Maybe 2.
That is not a skill issue.
That is an information issue.
And it has been quietly costing you every single day.
The outputs that felt slightly off.
The responses you had to rewrite 4 times.
The prompts that worked once and never again.
All of it traces back to the same 6 missing elements.
The people who watch this 24 minute workshop tonight will understand something about Claude that most daily users still do not know exists.
The people who skip it will keep getting 30% of what the tool is actually capable of and wonder why the results never quite land.
I watched it twice.
Then I built a Claude Skill that applies all 6 elements to every prompt automatically.
No more thinking about structure.
No more guessing what Claude needs.
The framework runs in the background every single time.
Full breakdown and skill setup is below.
Bookmark this now.
Watch the workshop first.
Then read the guide.
This is the one that compounds.
Follow @cyrilXBT for the exact prompt architecture, Claude skills, and systems I use to get outputs most people do not believe came from one person working alone.
I’ve hired 5 people for my startup
🤝 Co-founder: OpenClaw
👨💻 Coding: Opus 4.6
🐞 Debugging: GPT-5.2
🔬 Research: Grok 4.1
✍️ Writing: GPT-5 Mini
Work anytime, no leave, no drama
programmers are making $10k-200k monthly on polymarket
here's how they actually do it
///
1. arbitrage bots
buy YES + NO when combined price < $1
example: YES at 48¢ + NO at 49¢ = 97¢ total
you lock $0.03 profit per $1 no matter who wins
trader "distinct-baguette" made $242k in 1.5 months doing this
targets 15-min crypto markets where prices move fast
python script polls API every 1-3 seconds, executes when sum < 99¢
///
2. statistical arbitrage
find correlated markets that drift apart
"trump wins" vs "GOP senate control" should move together
when spread hits 4-7%, short expensive one, long cheap one
close when they converge
trader "sharky6999" made $480k scanning 100+ markets per minute
///
3. AI probability models
train ML models to estimate real odds from news/social data
if your model says 60% YES but market at 50¢, buy
trader "ilovecircle" made $2.2M in 2 months with 74% accuracy
uses ensemble of 10 AI models, retrains weekly
///
4. spread farming
buy at bid (5¢), sell at ask (6¢), repeat
or hedge across platforms (short polymarket, long binance)
trader "cry.eth2" made $194k with 1M trades
high-frequency loop via CLOB API
///
5. copy-trading automation
mirror successful whale traders automatically
scan profiles, execute proportional trades
one bot made $80k in 2 weeks copying near-resolved markets
///
tech stack:
python + requests library for API calls
web3-py for blockchain interactions deploy on VPS for 24/7 operation
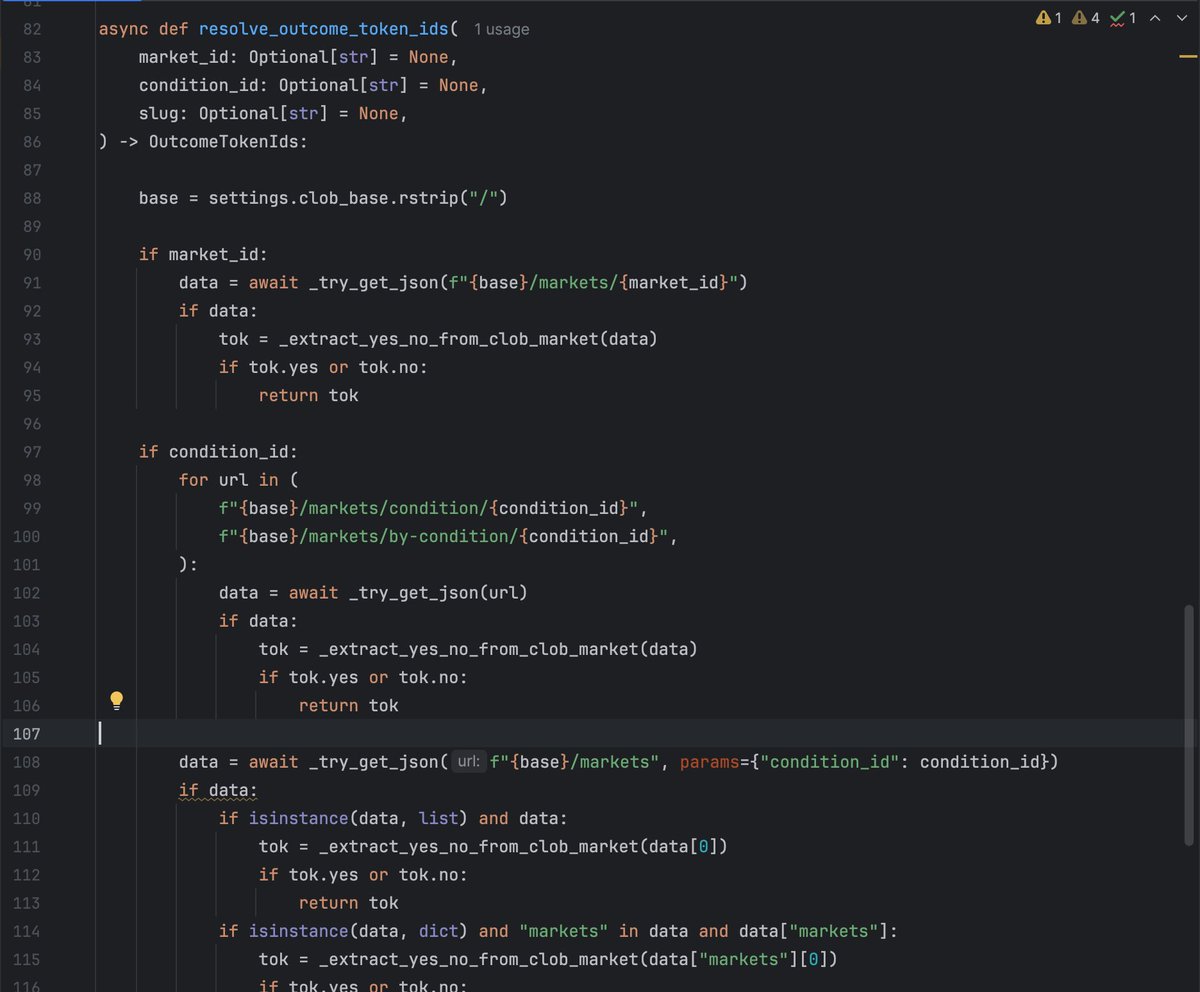
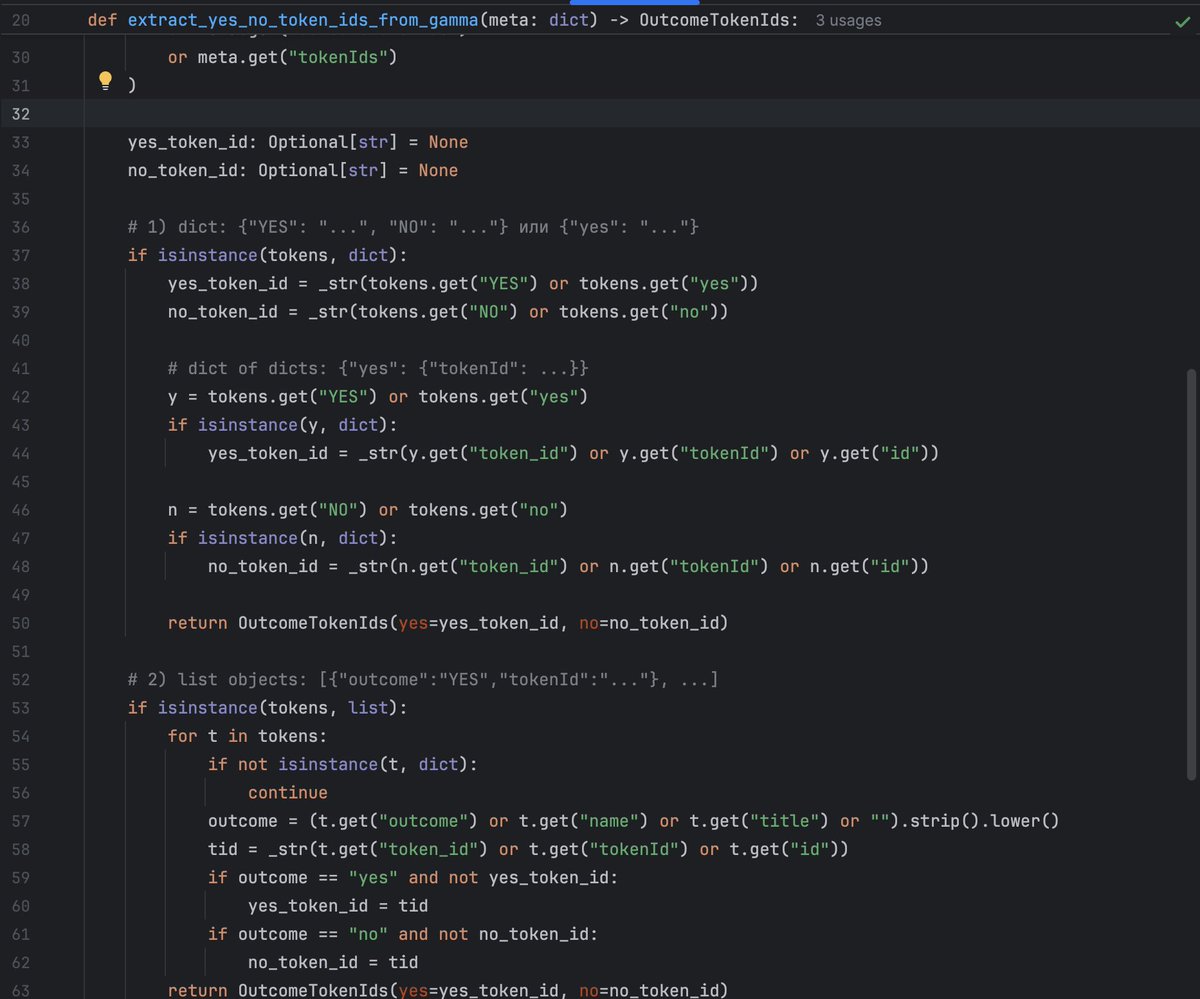
polymarket has REST APIs for everything:
gamma markets API (prices/volumes)
CLOB API (place orders)
data API (track positions)
///
starting point:
> build simple arbitrage bot first
> fund with $100-1k for testing target high-volume markets (politics/crypto)
> expect 50-70% win rate but focus on positive EV