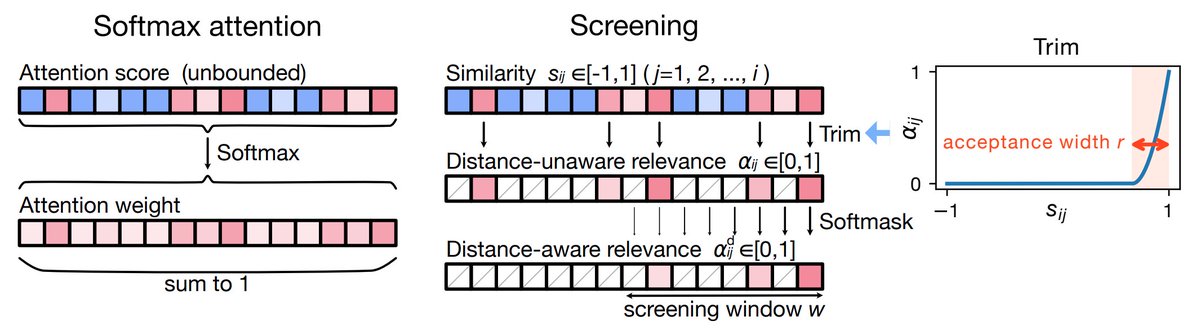
I just released a revised version of my paper on Multiscreen, an alternative to Transformer for long-context language modeling.
✅ Maintains performance and retrieves information accurately on contexts far longer than those seen during training
✅ Much more stable at large learning rates — it can even train with learning rate 1
✅ Smaller model size & faster inference
✅ More interpretable context selection
I added more figures to the main text and rewrote the paper to make it easier to follow. I’d be very happy if you read it!
Paper → https://t.co/fi9Ucl6oOy