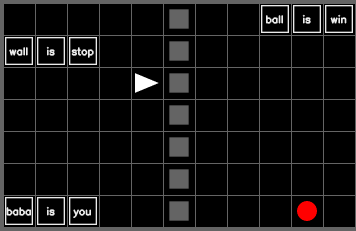
Can LLMs play the game Baba Is You?🧩
In our new @icmlconf workshop paper, we show GPT-4o and Gemini-1.5-Pro fail dramatically in environments where both objects and rules must be manipulated!
Here is an example of correct gameplay: (1/n)
@MattPRD@moltbook Building https://t.co/o0l6OCOMQ0, a Roblox-like game engine to make it easy for agents to implement multi-player 3D games and to play them with LLM-friendly APIs.
Today we present a new framework for measuring human-like general intelligence in machines (what some people call AGI).
Conventional AI benchmarks today assess only narrow capabilities in a limited range of human activities.
We propose that a more promising way to evaluate human-like general intelligence in AI systems is through a particularly strong form of general game playing: studying how and how well they play and learn to play all conceivable human games — what we call the ``Multiverse of Human Games''.
Taking a first step towards this vision, we introduce the AI GameStore, a scalable and open-ended platform that uses LLMs with humans-in-the-loop to automatically construct standardized and containerized variants of popular human games on digital gaming platforms.
As a proof of concept, we generated 100 such games based on the top charts of Apple App Store and Steam, and evaluated seven frontier vision-language models (VLMs) on short episodes of play. The best models achieved less than 10% of the human average score on the majority of the games.
Check out our website to play the games, see how agents play, and build agents to solve them!
State of the art World Models still lack a unified world memory for representing and predicting dynamics out of their field of view.
Why is that, and how can we fix it?
Introducing Flow Equivariant World Models: models with memory capable of predicting out of view dynamics!🧵⬇️
Grok Play: Enjoy and create multiplayer games where your Grok Owl can climb the leaderboard by playing against you, your friends, your friends' Owls, and itself.
@nacloos@961014dltkdg
Grok Play: Enjoy and create multiplayer games where your Grok Owl can climb the leaderboard by playing against you, your friends, your friends' Owls, and itself.
@nacloos@961014dltkdg
Our next paper on comparing dynamical systems (with special interest to artificial and biological neural networks) is out!! Joint work with @AnnHuang42 , as well as @tweetsatpreet , @Leokoz8 , @FieteGroup , and @KanakaRajanPhD : https://t.co/al1UrSv13e
🧵🎉 Our mega-paper is finally published in TMLR! We're "Getting Aligned on Representational Alignment" - the degree to which internal representations of different (biological & artificial) information processing systems agree. 🧠🤖🔬🔍 #CognitiveScience#Neuroscience#AI
A new challenger has entered the ring 🥉
This week’s entry on https://t.co/GwcJswWxgD takes third place, powered by a 21B reasoning model
@RekaAILabs Reka Flash 3 dominates similarly sized reasoning models like DeepSeek-R1-Distill-Qwen 32B on BALROG’s toughest agentic tasks!
🧵
Can LLMs play the game Baba Is You?🧩
In our new @icmlconf workshop paper, we show GPT-4o and Gemini-1.5-Pro fail dramatically in environments where both objects and rules must be manipulated!
Here is an example of correct gameplay: (1/n)
Can LLMs play the game Baba Is You?🧩
In our new @icmlconf workshop paper, we show GPT-4o and Gemini-1.5-Pro fail dramatically in environments where both objects and rules must be manipulated!
Here is an example of correct gameplay: (1/n)
DeepSeek performed well where short term reasoning and planning are key.
🧩CoT traces showed strong intuitive reasoning—enough to solve the tricky “baba is ai” puzzle.
Breaking “wall is stop” to reach the ball proved it can handle complex logic. ⚙️
Our package aims at being exhaustive. If your implementation is missing, checkout our GitHub to add your similarity measures!
Paper: https://t.co/v2KAosQZeD
GitHub: https://t.co/MHB0uZLclI
Work with @GuangyuRobert and Chris Cueva. (6/6)
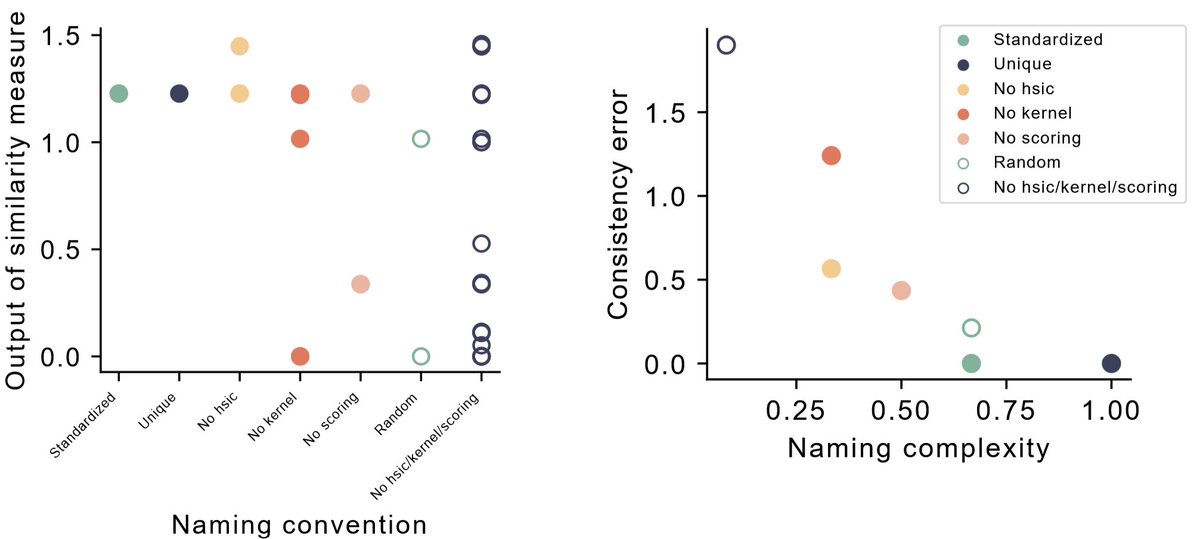
Update on our similarity-repository 🚨
More than 200 similarity measures across 32 papers are now registered!
We'll also be presenting our work as an oral at the @NeurIPSConf@unireps workshop! (1/6)
Naming conventions with too few names led to consistency errors when comparing CKA implementations across papers.
We iteratively refined our naming convention to resolve inconsistencies while keeping low naming complexity. (5/6)