Introducing ChatGPT Images 2.0
A state-of-the-art image model that can take on complex visual tasks and produce precise, immediately usable visuals, with sharper editing, richer layouts, and thinking-level intelligence.
Video made with ChatGPT Images
클로드 성능 저하 인정, 진짜로 문제있었다
최근 클로드 성능관련해서 문제있다고 커뮤니티에 엄청 말이 많이 나왔었는데
결국 클로드 측에서도
문제가 있다는걸 인정했슴다 ㄷㄷ
그런데 일부러 낮춘건 아니고 인프라 버그 세가지가 있었고 그거때문에 품질이 깨졌다고 하네유..
아 내 토큰 어떡할건데!!
4주 2배 이벤트만큼 화난다!!
마이크로소프트, GitHub Copilot 대격변 예고
유출된 내부 문서에 따르면 마이크로소프트가 GitHub Copilot에 큰 변화를 준비 중입니다.
핵심 내용:
1/ 기존 "요청" 기반 과금 → 토큰 기반 과금으로 전환. 실제 토큰 소모량만큼 비용을 내는 구조로 바뀝니다.
2/ 개인(Pro) 및 학생 요금제 신규 가입 일시 중단 예정.
3/ 개인·기업 모든 요금제에서 사용량 제한 강화. 이미 4월 초에 조정했지만 "충분하지 않았다"고.
4/ 가장 저렴한 Pro($10/월) 요금제에서 Anthropic Opus 모델 완전 제거.
5/ Opus 4.7로 전환되면서 프리미엄 요청 배수가 7.5x — 요청 1회가 실제로는 7.5회로 카운트됩니다. Opus 4.6 대비 약 250% 비용 증가.
Introducing Claude Design by Anthropic Labs: make prototypes, slides, and one-pagers by talking to Claude.
Powered by Claude Opus 4.7, our most capable vision model. Available in research preview on the Pro, Max, Team, and Enterprise plans, rolling out throughout the day.
Introducing Claude Opus 4.7, our most capable Opus model yet.
It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back.
You can hand off your hardest work with less supervision.
Opus 4.7 first-hour impressions
Ran the canvas tree growth test twice.
4.6: nailed the animation both times
4.7: static tree, no growth animation — twice
4.7's thinking is noticeably shorter and faster though (trimmed some 4.6 thinking in the clip for pacing).
Not the upgrade direction I expected on this one.
Claude Mythos Preview 공개..!
> "이 능력을 안전하게 일반에 풀기 위한 준비가 더 필요함"
Anthropic이 매우 중요한 내용을 공개했네요.
먼저 Project Glasswing은 Anthropic이 주도하는 사이버보안 방어 협력 이니셔티브 예요.
더불어 Mythos를 어떻게 선보였는지 전문을 확인해봤습니다.
1/ Project Glasswing
AI 시대의 사이버보안 위협에 선제적으로 대응하기 위해 빅테크/보안 기업들이 뭉침.
파트너사에는 AWS, Apple, Cisco, Google, Microsoft, NVIDIA, CrowdStrike, JPMorganChase, Linux Foundation, Broadcom, Palo Alto Networks..
↓
2/ 새 모델 Claude Mythos Preview..
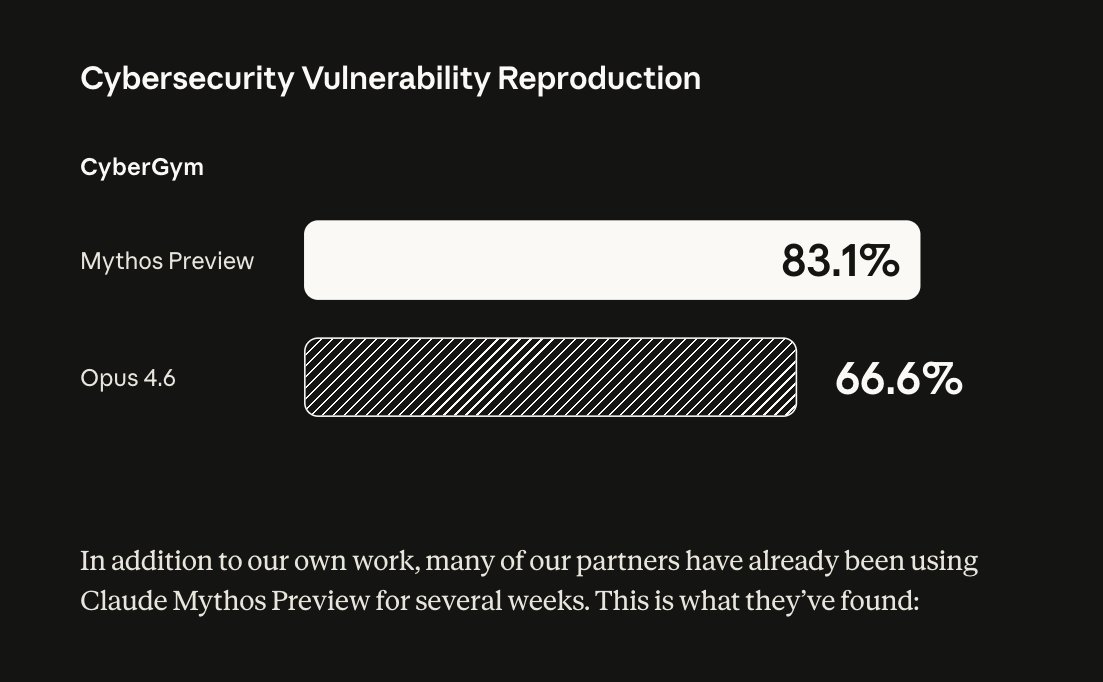
모든 주요 OS/브라우저에서 수천 개의 제로데이 취약점을 발견함.
그 중엔 수십 년간 수백만 번의 자동화 테스트를 통과한 버그도 포함.
- OpenBSD의 27년된 원격 크래시 취약점
- FFmpeg의 16년된 버그 (자동화 도구 500만 번 통과)
- Linux 커널 권한 상승 취약점 체인
↓
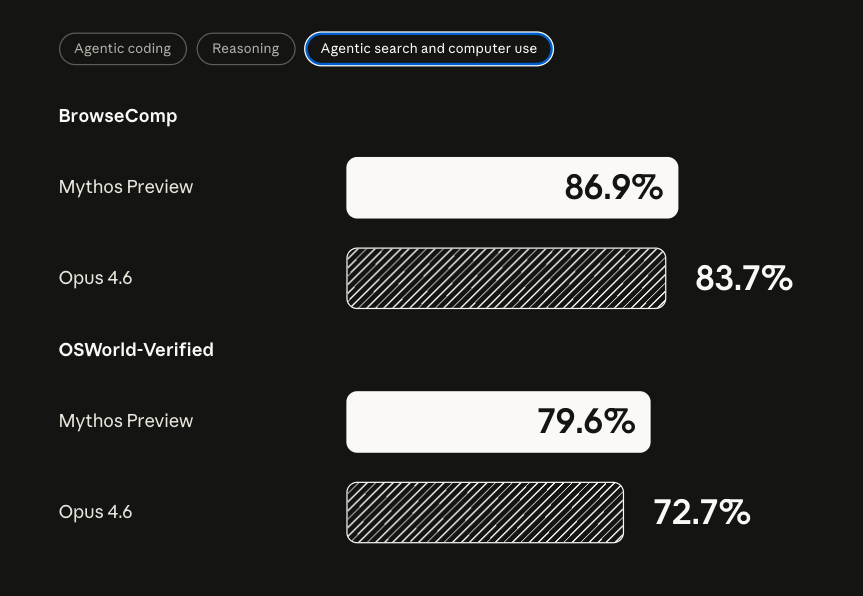
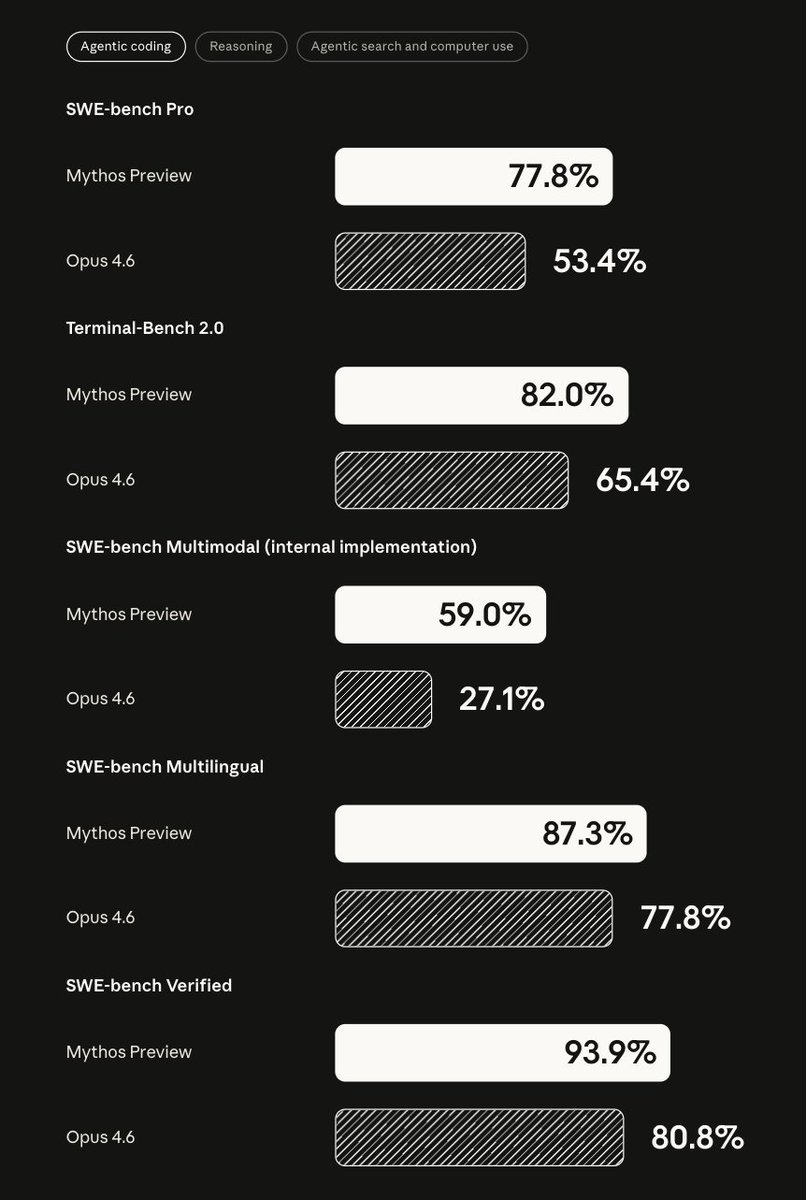
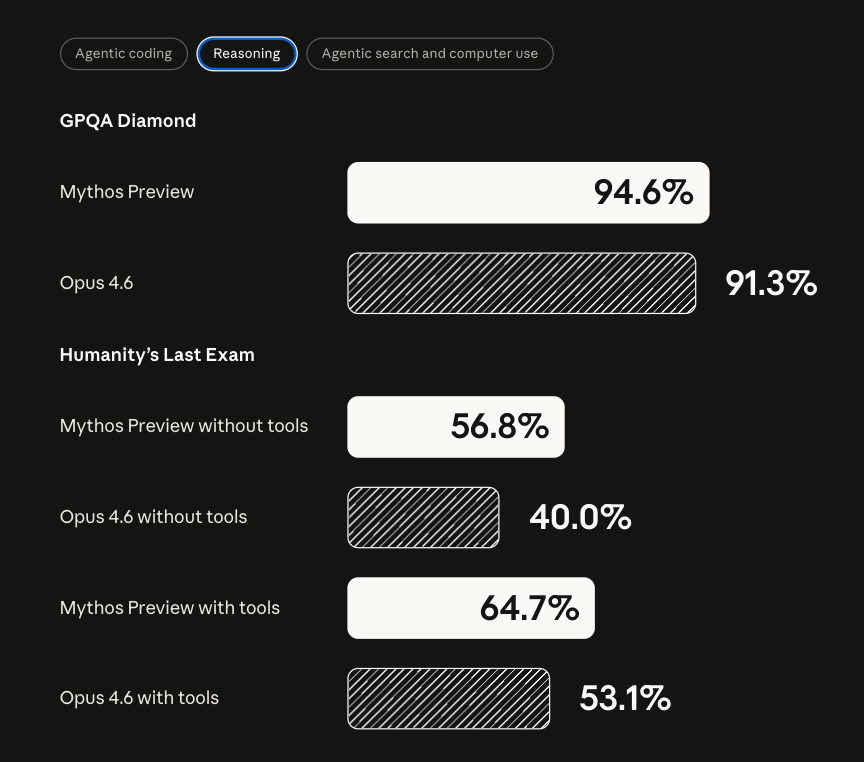
3/ 벤치마크로 보는 Mythos vs Opus 4.6
CyberGym, SWE-bench Verified, SWE-bench Pro, HLE, GPQA Diamond
차트를 봐도 느껴지시겠지만 Mythos는 각 분야에서 굉장히 큰 변화..
코딩/추론 전반에서 큰 폭의 향상이 있음!
↓
4/ 접근할 수는 있나?
현재는 론치 파트너사 전용 (일반 공개 없음)
Anthropic이 $100M 크레딧 지원!
이후에는 $25 / $125 per 1M 입출력 토큰
Claude API, Amazon Bedrock, Google Vertex AI, Microsoft Foundry
오픈소스 단체엔 $4M 직접 기부 (Alpha-Omega, OpenSSF, Apache Foundation)
↓
5/ 일반 출시는 없음.. 왜?
Mythos의 사이버 공격 능력 자체가 너무 강력하기 때문.
Anthropic은 안전장치 개발 후 차기 Opus 모델에 먼저 탑재해 정제할 계획.
한마디로: "이 능력을 안전하게 일반에 풀기 위한 준비가 더 필요하다."
↓
Mythos는 단순 성능 업그레이드가 아니네요.
사이버보안이라는 특정 임무를 위해 설계된 프론티어 모델...
당장 일반 출시 없이 빅테크 방어용으로만 쓰인다는 점이 놀라우면서도,,
AI의 사이버 공격력이 이미 그 수위를 아득히 넘었다는 신호가 아닐까도 생각해봅니다..
[로컬 LLM을 운영중이라면 주목: 구글 리서치, TurboQuant 발표]
이건 또 엄청난 결과물이 불과 몇 시간 전에 튀어나왔네요. 혹시나 괜찮은 맥미니나 맥 스튜디오에서 로컬 모델을 돌리고 계신다면 주목할만한 내용입니다. 하드웨어의 업그레이드 없이 성능좋은 LLM이 여러분의 맥미니나 맥스튜디오에서 돌아갈 수 있습니다.
일단 TurboQuant에 대해서 쉽게 설명해보겠습니다. AI가 대화할 때에는 "KV 캐시"라는 걸 씁니다. 쉽게 표현하면 AI가 이전에 읽은 내용을 빠르게 참조하기 위한 메모장인데, 대화가 길어질 수록 이게 커져서 GPU 메모리를 다 잡아먹습니다. 그러다보니 이를 소화하려면 비싼 GPU가 필요하게 되는 거죠. (토큰과는 좀 다릅니다. 이건 토큰과 함께 늘어나긴 하는데 메모리에만 잠깐 존재하고 세션 재시작 시 사라지는 임시데이터임)
TurboQuant는 이 메모장을 무려 6배 이상 줄이면서도 정확도 손실이 0인 압축 알고리즘입니다. 추가로 속도까지 최대 8배 빨라집니다. 어마어마한 효율성 개선입니다.
기존에도 이러한 시도는 많았지만 아무리 압축하려고 해봤자 추가 메모(오버헤드)가 필요했었기에 적용하기에 좀 문제가 많았습니다. 근데 이번 TurboQuant는 수학적 트릭 (벡터를 극좌표로 변환 + 1비트 에러 체크)을 통해 그 추가 메모 자체를 없앴다는 점에서 혁신적입니다.
결과적으로
- 같은 GPU로 더 긴 대화가 가능해짐
- AI 서비스 운영 비용이 줄어듦
- 로컬 모델에서 더 큰 컨텍스트 윈도우를 쓸 수 있게 됨
이라는 것입니다.
Prince 라는 MLX (Ollama같은, 로컬 LLM 돌리는 운영체제)에서 일하는 사람이 이걸 MLX에 직접 구현해서 테스트한 해봤는데, 결과가 아래와 같습니다.
테스트 방식: Qwen3.5-35B-A3B 모델로 Needle-in-a-Haystack 테스트 (8.5K, 32.7K, 64.2K 컨텍스트)
- 6/6 전부 정답 (모든 양자화 레벨에서)
- TurboQuant 2.5-bit: KV 캐시 4.9배 축소
- TurboQuant 3.5-bit: KV 캐시 3.8배 축소
- 정확도 손실 0 (세상에...)
사실 저도 맥미니 64gb에서 Qwen 27b를 Ollama 통해서 돌리고 있습니다. 정확히는 Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled 모델을 돌리고 있었는데, 뭐 그냥 Qwen 쌩으로 돌리는 것보단 distilled 모델이 더 잘나오고 빠릿하긴 했지만 아무래도 속도가 답답했단 말이죠.
계산대로 KV 캐시가 4~5배 줄면 같은 64gb 램에서 컨텍스트 윈도우 32k에서 100k+ 이상급도 나오겠고...지금 운영중인 모델보다 더 큰 모델도 돌릴 수 있겠습니다.
아 기분이 너무 좋네요...!! 자자 @ollama please support TurboQuant right now 빨리 서포트 해달라