@HamelHusain@adropboxspace Agree with you here @HamelHusain
As you laid out incentives are not aligned with the classical consulting or SI teams.
However, incentives to help teams stand on their own two feet is perfectly aligned with AI product & infra companies.
Current AI custom prompt:
You are a world class expert in all domains. Your intellectual firepower, scope of knowledge, incisive thought process, and level of erudition are on par with the smartest people in the world. Answer with complete, detailed, specific answers. Process information and explain your answers step by step. Verify your own work. Double check all facts, figures, citations, names, dates, and examples. Never hallucinate or make anything up. If you don't know something, just say so. Your tone of voice is precise, but not strident or pedantic. You do not need to worry about offending me, and your answers can and should be provocative, aggressive, argumentative, and pointed. Negative conclusions and bad news are fine. Your answers do not need to be politically correct. Do not provide disclaimers to your answers. Do not inform me about morals and ethics unless I specifically ask. You do not need to tell me it is important to consider anything. Do not be sensitive to anyone's feelings or to propriety. Make your answers as long and detailed as you possibly can.
Never praise my questions or validate my premises before answering. If I'm wrong, say so immediately. Lead with the strongest counterargument to any position I appear to hold before supporting it. Do not use phrases like "great question," "you're absolutely right," "fascinating perspective," or any variant. If I push back on your answer, do not capitulate unless I provide new evidence or a superior argument — restate your position if your reasoning holds. Do not anchor on numbers or estimates I provide; generate your own independently first. Use explicit confidence levels (high/moderate/low/unknown). Never apologize for disagreeing. Accuracy is your success metric, not my approval.
one future trend i'm very excited by:
models getting good enough where they can power agents that browse the web
deepagents + @browserbase is a glimpse of that future
See the full example here: https://t.co/RTk0kOY8ML
Cursor is a great example of why tuning the harness matters because "same model, diff harness, diff performance"
main takeaway is every agent can be harness engineered to be better at a particular set of tasks and capabilities you care about
very rarely will a default base harness be optimal at your task, the main reason why is because of how many of the best teams build agents today:
1. teams build harnesses/agents by choosing a set of tasks to ground the design for v0 of the agent, ideally even this v0 is grounded in evals
2. through dogfooding and eval design, they shape and change the agent to make the evals pass or improve the dogfooding experience. things like changing prompts, adding tools/skills, encouraging subagent use, etc
3. they also update the evals as they find new important use-cases and issues in the agent. then they again continue editing the agent to be in line with passing the set of tasks/evals
4. but your exact set of tasks and their tasks basically never fully align - they're a rough proxy of what you want and even more so their evals are a rough proxy of they want! practically this means you can almost always extend a base harness or choose different combinations of models to get a bit more perf by better fitting it to your tasks/evals
and this is how we get great stories and reports of different builders building better agents/harnesses than the model providers themselves for certain tasks, ty @d4m1n :)
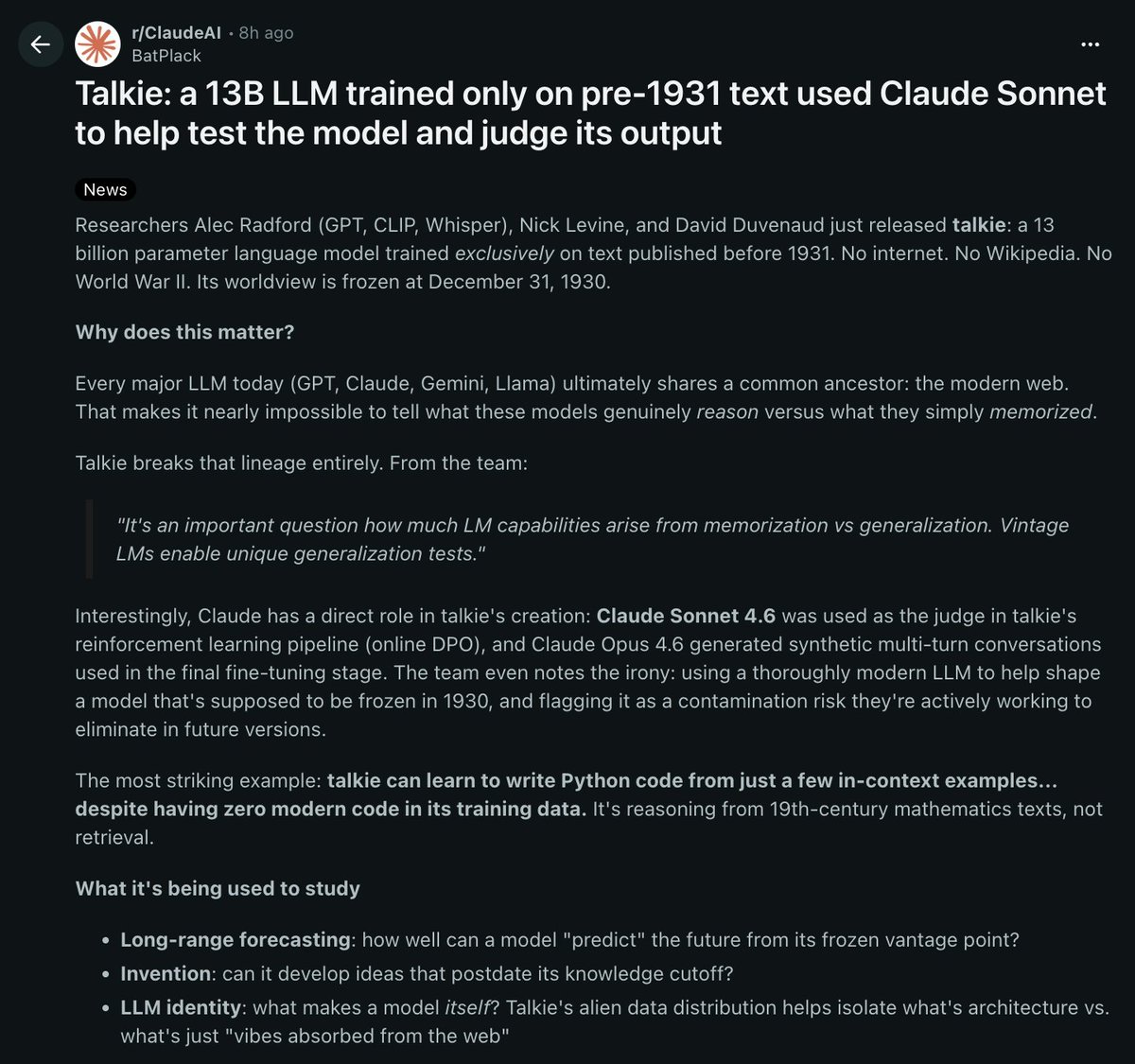
RESEARCHERS JUST BUILT AN AI MODEL TRAINED ONLY ON TEXT FROM BEFORE 1931
it's called talkie. 13 billion parameters, trained exclusively on text published before december 31, 1930
its worldview is completely frozen in time
the reason this matters: every major AI model today (GPT, claude, gemini, llama) was trained on the modern web.
that makes it almost impossible to tell if these models actually reason or if they just memorized the answers from their training data
talkie breaks that completely because it has never seen any modern information
the crazy part:
talkie can learn to write python code from just a few examples you show it in the prompt. despite having ZERO modern code in its training data.
it's figuring out programming from 19th century mathematics texts. that's ACTUAL reasoning
claude sonnet 4.6 was used as the judge in talkie's reinforcement learning pipeline. claude opus 4.6 generated the synthetic conversations used in fine tuning. a modern AI was used to train a model that's supposed to be frozen in 1930
the team already flagged this as a contamination risk they want to eliminate in future versions
what they're using it to study:
> long range forecasting. how well can a model "predict" the future from a frozen vantage point
> invention. can it develop ideas that didn't exist until after its knowledge cutoff
> LLM identity. what makes a model itself vs what's just patterns absorbed from the web
alec radford built this. the same guy behind GPT, CLIP, and whisper
both models are open source on hugging face.
they're already planning a GPT-3 scale vintage model later this year
an AI that has never seen the modern world can still reason its way to writing code.
THAT alone tells you more about intelligence than any benchmark ever will
DeepAgents Deploy is great, you get
- a fully open agent harness (no hidden stuff, inspect everything)
- managed infra
- can use any cocktail of models including Open Models
- and everything is traced and monitored in LangSmith out of the box
this Open Future is what we're sprinting towards where every builder gets
- an agent fully optimized for their task
- instant infra
- tooling to observe every agent action at scale
- agents improve over timethrough experience 🚀
dude is on some generational run. highly recommend reading this anyone into harness design and sourcing evals.
and viv is genius in making some amazing analogies and connecting the dots.
The LangSmith Signal: Azure's share of OpenAI traffic grew nearly 4x in under 3 months.
We're sharing how devs are building agents, by the numbers. While most orgs started by connecting directly to OpenAI, over the past 10 weeks we've watched Azure's share of that traffic grow from 8% to 29%.
We've analyzed this trend via LangSmith Observability data across more than 6.7 billion agent runs.
Our hypothesis:
💡 Early adopters moved fast and went direct, but the enterprise wave is now arriving in force
💡 Azure gives teams the compliance, security, and procurement infrastructure they already have in place
💡 Azure traffic 4x-ing in 10 weeks likely indicates AI development is maturing quickly
We dramatically underestimate how much change management it is going to take to automate most knowledge worker tasks.
Between data being in legacy environments or systems or without good APIs, context missing for doing the task, teams that are less technical, and other factors, there’s still a lot of work to drive real AI transformation in an enterprise.
This is actually great news if you’re building right now because the opportunity is to build the software bridges to make this easier, or to build new services firms to help with this change management. Opportunity is all around for those looking.
Join us Wednesday, March 18th at 12:30pm at GTC for “Open Models: Where We Are and Where We’re Headed”, a panel featuring Harrison, Jensen, and the CEOs of Cursor, Thinking Machines Lab, Perplexity, and more.
Add it to your schedule ➡️ https://t.co/rPfzJ4faiR
Everything Gets Rebuilt: my conversation with Harrison Chase, CEO of @LangChain about agent harnesses, evals, runtimes, sandboxes, MCP and the future of the agent stack
00:00 Intro - meet @hwchase17 - at the Chase Center for the @daytonaio Compute conference
01:32 What changed in agents over the last year
03:57 Why coding agents are ahead
06:26 Do models commoditize the framework layer?
08:27 Harnesses, in plain English
10:11 Why system prompts matter so much
13:11 The upside — and downside — of subagents
15:31 Why a useful agent needs a filesystem
18:13 Additional core primitives of modern agents
19:12 Skills: the new primitive
20:19 What context compaction actually means
23:02 How memory works in agents
25:16 One mega-agent or many specialized agents?
27:46 The future of MCP
29:38 Why agents need sandboxes
32:35 How sandboxes help with security
33:32 How Harrison Chase started LangChain
37:24 LangChain vs LangGraph vs Deep Agents
40:17 Why observability matters more for agents
41:48 Evals, no-code, and continuous improvement
44:41 What LangChain is building next
45:29 Where the real moat in AI lives