@chaibytesai@cursor_ai True, and lot of engg effort and system building is going into putting checks to make sure the KB or other docs are upto date with the code evolution, and lucid throughout.
@ThisIsBhandari 30LPA is such a weird number, you mean he didn't deserve more? If they felt that was right, they should have asked for it.
Funny how this hypothetical number gets genetically annotated to culture of startups in a country.
Like kernel fusion ops done for ML model inferencing on GPUs, might need tool fusions on agentic systems to optimize tools usage, token counts, speed and maybe also quality.
That needs observability stack for query > tool calls mapping, find bottlenecks, create eval sets.
At beginning of my coding journey, my senior/mentor (initially requested, then scolded) on the functions naming and descriptions/comments quality. Now for agents, there is no other alternate.
Interesting how the outcome now automatically enforces/incentivises this need.
Developers who learned to be efficient and adapt over time, will learn to be efficient with AI tools as well. That will be the difference, how fast can you get things right for the desired output. The edge continues to be time and more compute or agents doesn't solve it.
Keep wondering, what is the right or most effective work setup/architecture for coding agents to work, in predictable, robust and enterprise-grade quality/processes.
Concepts I'd master to build production ML systems with PyTorch.
Bookmark this 👇
1. TorchScript for model serialization
2. torch.compile for 2x speedups
3. Distributed training with DDP/FSDP
4. Mixed precision with torch.amp
5. Custom CUDA kernels with Triton
6. Model quantization (PTQ & QAT)
7. TorchServe for model deployment
8. Lightning for cleaner training loops
9. Dataset optimization with DataLoader workers
10. Profiling with torch.profiler
11. ONNX export for cross-platform inference
12. Gradient accumulation for large batches
13. Learning rate scheduling strategies
14. Model checkpointing & recovery
15. TorchVision/Audio/Text domain libraries
16. Integration with HuggingFace ecosystem
@agupta I don't think its a matter of field. If anyone is able to master any specific field, I think they can get pretty good in any other they explore.
Great post on improving inferencing/training with torch compile, and how to manage the compiled graphs @TDataScience https://t.co/JjOeXRRk3B.
Was working on similar lines to see if can do better than vllm. Lot more to explore with Dynamo and its logging.
Introducing the Environments Hub
RL environments are the key bottleneck to the next wave of AI progress, but big labs are locking them down
We built a community platform for crowdsourcing open environments, so anyone can contribute to open-source AGI
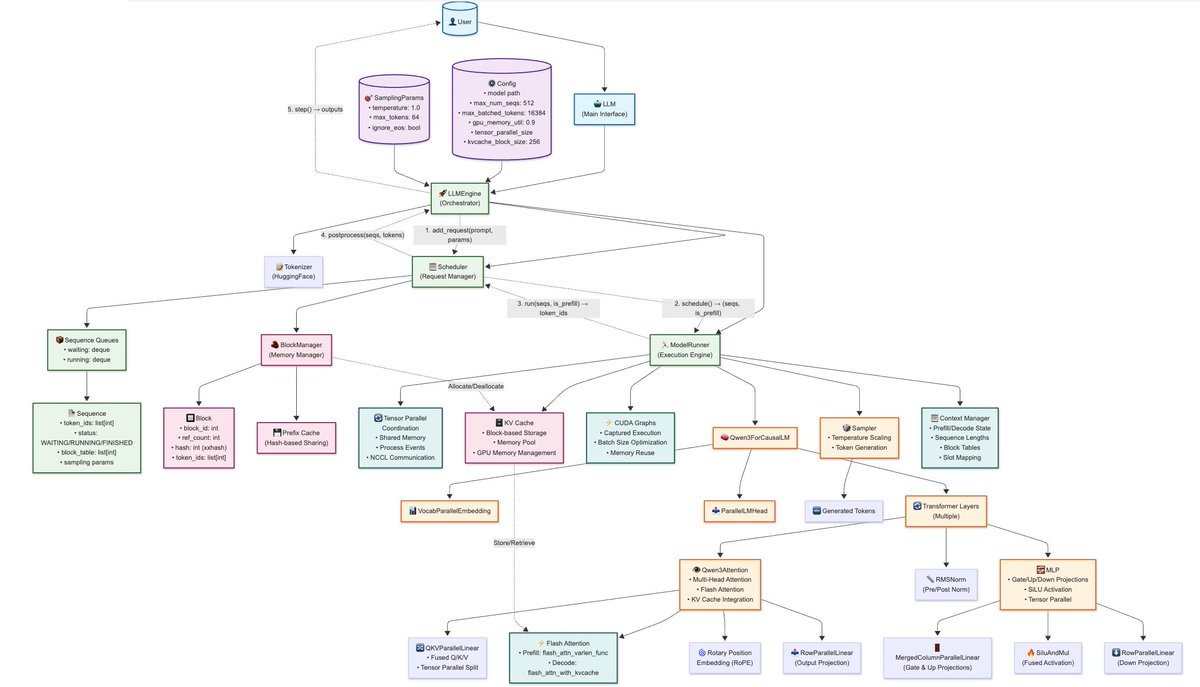
Thanks to Cursor, was able to quickly get some overview on the nano-vllm implementation. For Block-based KV cache, wondering if there has been any ablation on performance and use-cases.
Been struggling with Google 'AI mode' a bit. Asked a question related to a vllm use-case setup, and it kept hallucinating with suggestion that doesn't work, with error message followup, suggested same answer, thrice.