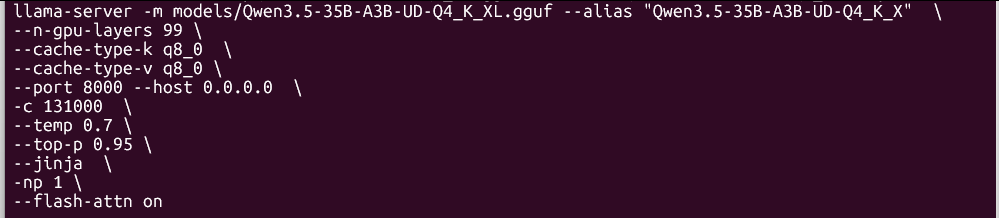
@sudoingX 4token/s with 3090 with these settings any idea why ? set LLAMA_DIR=D:\IA\llama.cpp
set MODEL=D:\IA\models-llama\Qwen3.5-27B-Q4_K_M.gguf
set PORT=8000
"%LLAMA_DIR%\llama-server.exe" -m "%MODEL%" -ngl 99 -c 262144 -fa on --cache-type-k q4_0 --cache-type-v q4_0
first impressions of qwen 3.5 27B dense on a single RTX 3090.
35 tok/s. from 4K all the way to 300K+ context. no speed drop. hermes 4.3 started at 35 and degraded to 15 as context filled. qwen dense holds. MoE held 112 flat. 3x faster but only 3B of 35B active per token. architecture tradeoff.
Q4_K_M on 16.7GB. native context 262K. pushed past training limit to 376K before VRAM ceiling on 24GB. tried q8 KV cache at 262K, speed collapsed to 11 tok/s. q4_0 KV is the sweet spot. flash attention mandatory.
built in reasoning mode. the model thinks step by step before it answers. full chain of thought surviving Q4 quant. 1,799+ token thinking chains with self correction loops. on a single consumer GPU.
gave it one prompt: "build a realtime particle galaxy simulation in one HTML file." 3,340 tokens. 95 seconds. one shot. ran on first load. full reasoning and coding in the video below.
optimal config if you want to skip the hours of testing:
llama-server -ngl 99 -c 262144 -fa on --cache-type-k q4_0 --cache-type-v q4_0
this is just the warmup. octopus invaders is next: 10 files, 3,400+ lines, zero steering. the prompt hermes quit at 22%.
already more impressed than expected. full results coming soon.
@sudoingX At the end , we can run both model (27B dense or 35B A3B MoE) with 262k context length on a single 3090 . MoE is 90t/s and dense is 35t/s but which one have better quality ? ☺️