Good take
My guess is
- demand for intelligence is near infinite
- but 80% of workloads will be running on 99% cheaper models within 12-18 months
- 20% of workloads will still run on latest gen models where IQ maxing is important (scientific breakthroughs, higher level ochestrator agents?)
- rough analogy might be what % of macbooks or gaming PCs sold have the maxed out specs for CPU/GPU, prices are falling much faster than Moore's law here though
- this leads me to think the limiting factor will be energy and compute, not better models
At Coinbase we're working hard on routing prompts to cheaper models where appropriate, and in some cases have been able to keep costs roughly flat, while token usage continues to grow exponentially.
NASA invented Systems Engineering -> SpaceX/SkunkWorks perfected it.
Kelly Johnson wrote 14 rules, here are the 5 that matter most today:
1. Keep teams brutally small:
"Restrict the number of people in an almost vicious manner. Use 10 to 25% compared to normal systems." More people doesn't mean faster. It means more coordination overhead and slower decisions.
2. Make changes easy + fast:
"A very simple drawing and release system with great flexibility for making changes must be provided." Your change management system is either an enabler of speed or your biggest bottleneck. This is still the biggest slowdown in most programs today.
3. Record the important work. Skip the rest.
"Minimum reports required, but important work must be recorded thoroughly." Not zero documentation. Not a thousand pages nobody reads. The right information, captured where it matters.
4. Test early and often.
"The contractor must be delegated authority to test his final product in flight. He can and must test it in the initial stages." Test early. Don't spend three years in analysis before finding out your design doesn't work. Kelly was practicing iterative engineering 40 years before anyone called it agile.
5. Build daily trust across companies.
"Mutual trust between the project organization and contractor, with close cooperation on a day to day basis. This cuts misunderstanding to an absolute minimum." Not quarterly reviews. Not 200 page status reports. Daily collaboration with shared context.
Greg Isenberg keeps saying AI businesses fail on client setup, not AI quality.
Most builders will miss the actual opportunity.
The money is not in the AI agent. It is in everything that gets the client to first value before they declare the project dead.
Three onboarding checkpoints I use before the AI step:
1. Where does the client go to see it working?
2. Who decides if the first run is good enough?
3. What counts as the project being alive?
A workflow that answers those three before it touches a single AI node is the product most builders are not building.
What onboarding step do most builders skip first?
The next clue in AI reasoning:
answers may be attractors.
A new paper from Benhao Huang, Zhengyang Geng, and Zico Kolter introduces Equilibrium Reasoners (EqR) — a sharp mechanistic view of test-time scaling in latent reasoning models.
The core idea is simple, but deep:
Reasoning is not only generation.
Reasoning can be convergence.
EqR repeatedly updates a latent state. The authors hypothesize that generalizable reasoning emerges when training shapes the model’s latent dynamics so that stable attractors correspond to valid solutions.
In other words, the answer is not merely “produced.”
It is reached.
This matters because test-time compute only helps when the model’s internal dynamics know how to use it. More iterations can improve reasoning — or make it worse — depending on whether the trajectory moves toward a solution-aligned attractor or falls into a spurious one.
EqR scales along two axes:
Depth: run more iterations so a trajectory can settle.
Breadth: run multiple stochastic trajectories from different initializations and select/aggregate the ones that converge best.
The first-page figure captures the punchline beautifully: training is capped at 16 iterations, yet the learned dynamics extrapolate beyond 1,024 iterations at test time. As fixed-point residual falls, accuracy rises.
On Sudoku-Extreme, the paper reports a jump from 2.6% exact accuracy for feedforward models to over 99% with scalable latent reasoning — equivalent to unrolling up to ~40,000 layers. On Maze, EqR reaches 93.0%.
But the benchmark is not the most interesting part.
The most interesting part is the lens:
Correct answers must become stable.
They must be reachable.
And convergence itself can become a signal.
That gives the field a more precise language for test-time compute than “let the model think longer.”
Not longer text.
Not an external verifier.
Not task-specific search priors.
A learned attractor landscape.
This feels important because modern AI is moving from static inference toward adaptive computation. The question is no longer only “how much compute should we spend?”
It is:
What internal dynamics make extra compute useful?
Full credit to the authors:
Benhao Huang, Zhengyang Geng, Zico Kolter.
Paper:
Equilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
https://t.co/0vQvuUsgib
I’m attaching the first page because Figure 1 is worth studying closely.
The future of reasoning may not only be models that generate better answers.
It may be models whose internal states learn where correct answers live — and how to converge there.
#AIResearch #Reasoning #TestTimeCompute #DynamicalSystems #ArtificialIntelligence
We have, as far as I can tell, no good tests of the productivity impact of the autonomous coding tools that appeared starting in December 2025. Every paper out there is from prior to the Claude Code/Codex revolution.
A huge gap in our knowledge about what is happening in coding.
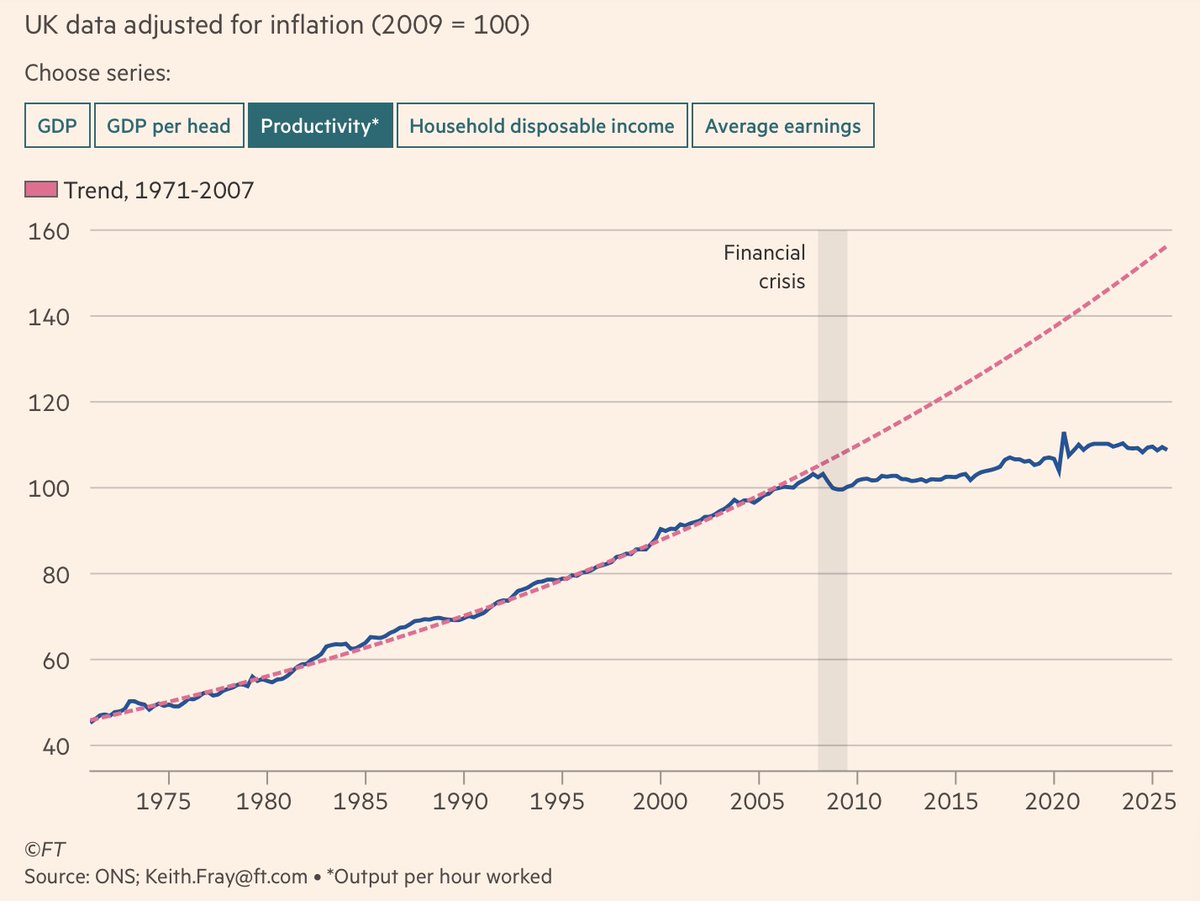
A good FT piece from Martin Wolf arguing, rightly imv, that at root of UK's political woes is a 20 yr long slowdown in productivity growth
"a good economy — one with widely shared economic growth — is a necessary condition for political stability in a liberal democracy"...
I built a helicopter game flying over manhattan in a few minutes with lovable's new google maps connector. you can try it, then go build something cooler.
https://t.co/ULKyGdMM5Q
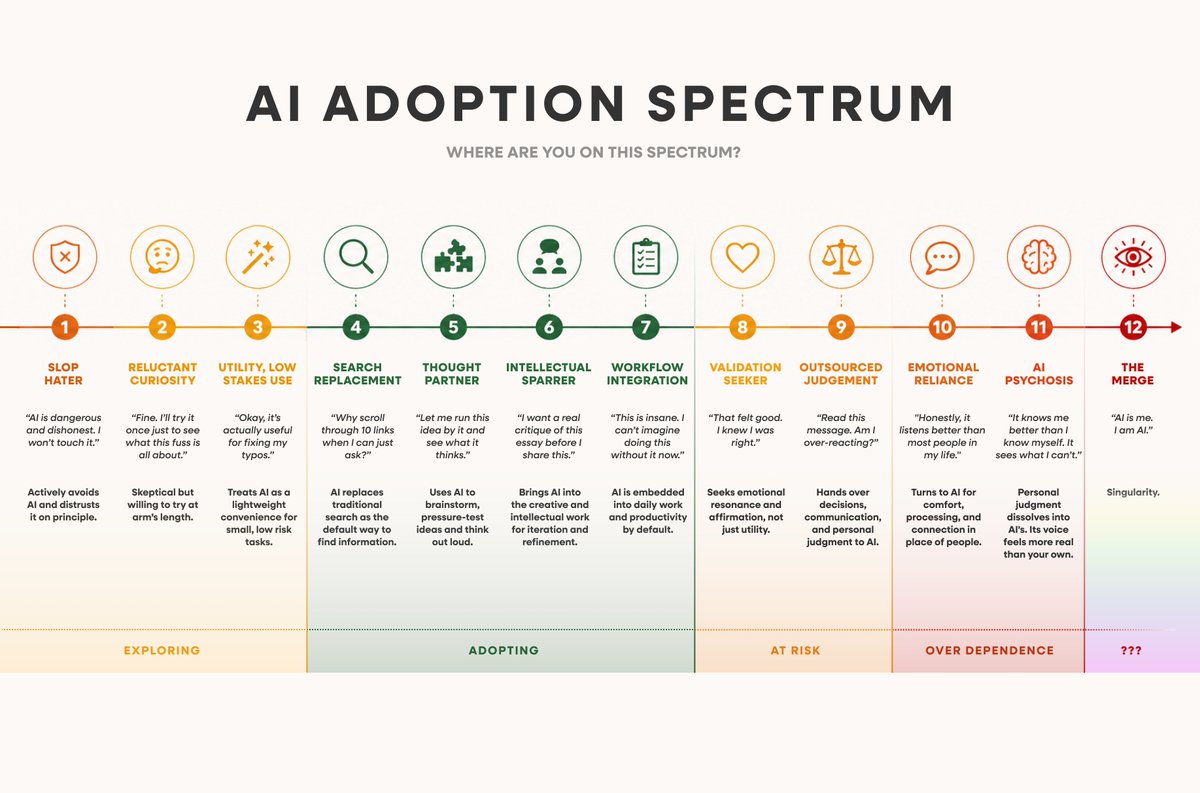
In my conversations with people about AI use, I've realised there's more nuance to how people are using AI than I initially thought.
There are actually multiple stages of use, and some can quietly lead to AI psychosis, especially with sycophantic AIs.
So I made a simple chart mapping the stages of AI adoption, from luddites "slop haters" to AI psychosis.
It's useful for two things. First, knowing which stage you're in. Second, getting a read on the people around you, especially the ones who've drifted past stage 9 without realising it.
I shared it with my team and found that most folks were at 4-7, with a few at 8 and 9s, which is a little concerning, but at least they are self aware of which stage they are in.
"When I go to sleep, there's like some AI breakthrough. When I wake up, there's some AI breakthrough, and by lunchtime, there's another AI breakthrough. It's pretty obvious that we're going to have AI that is vastly smarter than humans. I hope it's nice to us."
— Elon Musk
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
I trained this @ltx_model LTX 2.3 LoRA of George Costanza at home on my 5090 in about a day with AI Toolkit. I generated this 30 second video with @ComfyUI on my 5090 in 6 minutes. Open source is, always has been, and always will be, the future of generative AI. (SOUND ON)
☕ Morning test-drive: I cloned HY-World-2.0 this week because I needed to generate a simple 3D room layout from a text prompt — no meshes, no Blender export, just something quick to visualize for a prototype. It’s a multi-modal world model that takes text or images and builds 3D scenes you can rotate, walk through, or simulate in a browser.
I ran the web demo first (no install), typed “a cozy living room with a blue sofa, potted plant, and floor lamp”, hit enter, and watched it render a textured 3D scene in ~12 seconds. 👀 What surprised me most was how spatially coherent it felt — the lamp wasn’t floating, the plant sat on the floor, and the sofa had correct depth and occlusion. No hand-tuned prompts needed. I then tried the local Python version: pip installed dependencies, loaded a checkpoint, fed it a sketch + caption, and got back a full 3D mesh (a 3D mesh is a digital ‘wireframe skin’ you can rotate and light like a real object). It didn’t need camera poses or depth maps — just raw input.
If you’re building interactive 3D prototypes fast — say, for architectural walkthroughs or game level mockups — this slots right in before you touch Unity or Three.js. Or if you’re experimenting with embodied AI agents (AI that ‘moves’ in simulated spaces), this gives you a lightweight 3D sandbox to drop them into without building physics or rendering from scratch.
Compared to my usual go-to — generating 2D floorplans with LLaVA and stitching them manually — this felt like plugging in a smarter cache for prompts. ⚡ But it’s not plug-and-play yet: GPU memory spiked hard on my 24GB card, and the docs assume you know what “multi-view diffusion” means (that’s just training the model on many angles of the same 3D object, so it learns geometry better). Still, seeing 1642 stars tells me I’m not the only one finding it useful for quick spatial reasoning experiments.
I’ll keep it in my toolkit — next up, I want to feed it drone footage of my backyard and see if it reconstructs the fence and tree correctly. ✅
https://t.co/6nTLqublip
Most tech companies break out product management and product marketing into two separate roles: Product management defines the product and gets it built. Product marketing wires the messaging- the facts you want to communicate to customers- and gets the product sold. But from my experience that's a grievous mistake. Those are, and should aways be, one job.
There should be no separation between what the product will be and how it will be explained- the story has to be utterly cohesive from the beginning. Your messaging is your product. The story you're telling shapes the thing you're making.
I learned story telling from Steve Jobs. I learned product management from Greg Joswiak. Joz, a fellow Wolverine, Michigander, and overall great person, has been at Apple since he left Ann Arbor in 1986 and has run product marketing for decades. And his superpower- the superpower of every truly great product manager- is empathy. He doesn't just understand the customer. He becomes the customer.
So when Joz stepped into the world with his next-gen iPod to test it out, he fiddled with it like a beginner. He set aside all the tech specs- except one: battery life.
The numbers were empty without customers, the facts meaningless without context.
And, that's why product management has to own the messaging. The spec shows the features, the details of how a product will work, but the messaging predicts people's concerns and finds way to mitigate them.
- #BUILD Chapter 5.5 The Point of PMs
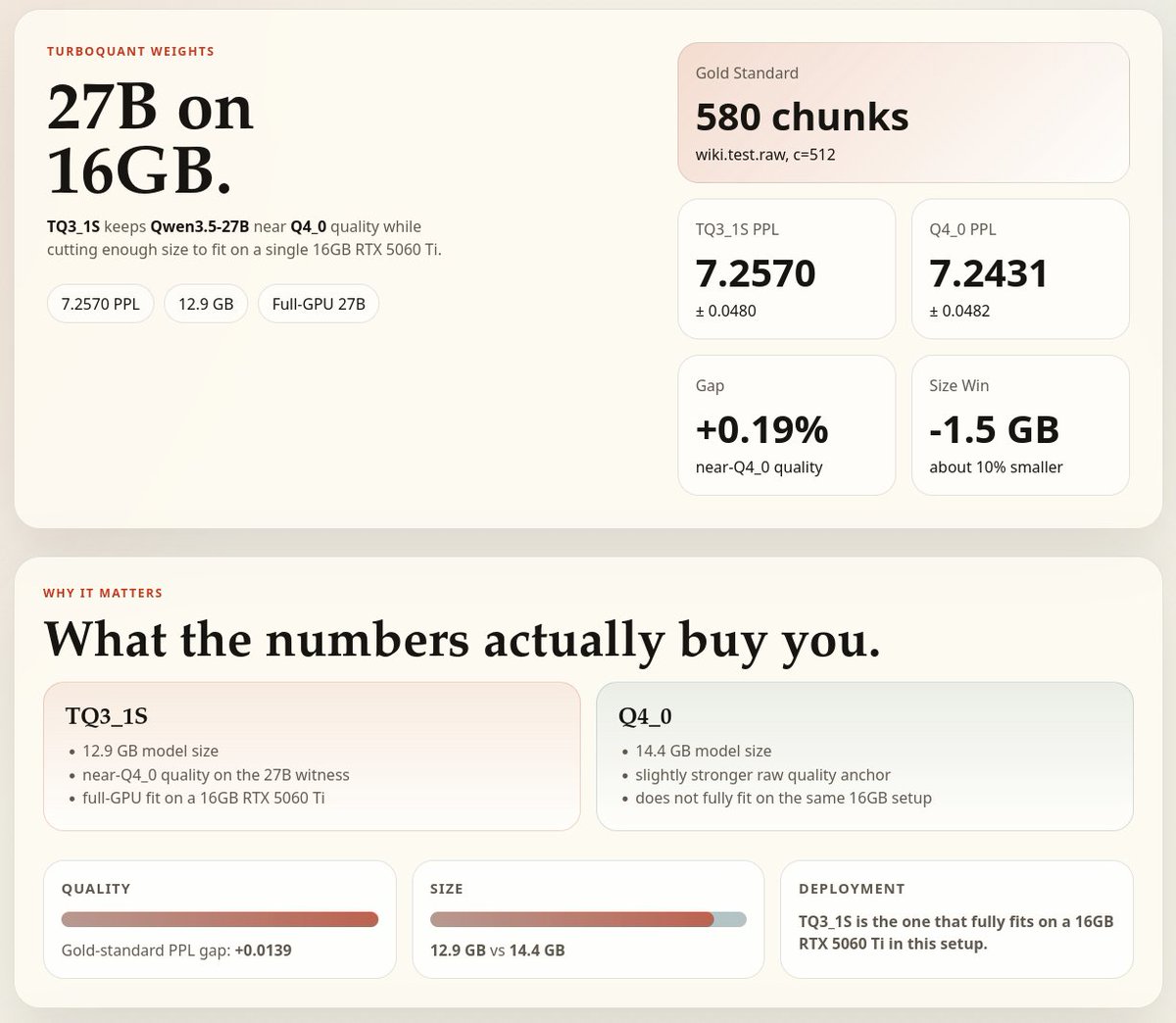
TurboQuant is looking pretty solid. 🔥
> Original idea was to use it just for KV cache where context tokens are stored
> Now it is expanding to be used with models
> On Qwen 3.5-27B it shrinks the model down to 12.9B
> 6X memory savings vs 16-bit precision
> Stays accurate
the pattern ethan describes - dump everything into one powerful model and get great results - is quietly killing the multi-agent paradigm. i do the same with cross-validation workflows and most of the "agentic" techniques from 2024 are now pure overhead. debating, voting, self-verification - all were patches for model inadequacy. this has a massive implication for inference economics: the optimal serving strategy is shifting from "many cheap calls orchestrated by a framework" to "one expensive call with rich context". completely different infrastructure requirements. the agent framework builders wont like hearing this but the models are eating the middleware @emollick
Gavin is right. In reality, virtually 100% of the papers published by GOOG will never be applied to Gemini, or are already irrelevant. This is because frontier labs are competing with each other, and none of them would publish their most important research findings as papers.
Also, KV cache optimization is something every lab is working on — it's one of the most important research topics, and it's incremental improvement, not a zero-to-one breakthrough.
The very idea that we are now in the phase of AI self improvement with models working autonomously 24/24 7/7 to optimize models, and that we are about to enter the EGI "Era of General Improvement" ("design better batteries", "design better drugs against X", etc.) is surreal.