The apps model for extended reality (XR) content is not going to work. No download, everything contextual. Driven by GenUI, enhanced by AI agents and most importantly developed from an open source library you can expand limitlessly.
- Omnia plan for 2025 onwards.
Most smart glasses demos show someone reading instructions off a screen.
That's not what we built.
At Comer Industries (Rockford IL), we analyzed 1,025 measurement records across 13 assembly stations.
The Settle Bearing step alone was failing 85.7% of the time. One unit needed 12 consecutive reruns on a single step with zero guidance on what to change between attempts.
76% of all failures had a measured value of exactly zero. The machine ran, captured nothing, logged a defect. Not a bad part. Not a broken tool. The worker initiated the cycle before a physical prerequisite was met — because nothing stopped them.
Here's what we built:
OmniaAgent connects Rokid smart glasses to the legacy OEM software running on the station. The machine completes a press cycle → glasses HUD advances automatically. Worker confirms a step by voice → station software advances in sync.
On top of that: a CV model trained on footage from Comer's own equipment, their own parts, their own assembly line. Not a generic model. One that knows what a correctly seated bearing cup looks like on this fixture before this press descends. It checks before the cycle runs. It blocks the invalid cycle before the machine fires.
The result: 71.9% of failures are directly addressable. $2.3M in projected annual savings — grounded in their actual production data, not estimates.
One station. Path to 100.
This is what enterprise AI on the factory floor actually looks like — agents integrated into legacy OEM software, CV models trained on the client's own equipment, error rates as the scoreboard.
#SmartGlasses #ManufacturingAI #ComputerVision #EnterpriseAI #AIAgents #Industry40
OmniaClaw on actual glasses. Three demos.
1/ Machine instructions — custom JSON, mock coffee machine. Swap the JSON, swap the machine. Carrier unit, Trane chiller, PTO shaft — same runtime.
2/ Service log — worker speaks, row writes to sheet. No form. No tablet.
3/ Full operator flow on glass — voice, full-screen messages, supervisor path closing in real time.
Next layer: custom CV models on your equipment. The JSON tells the worker what to do. The vision model watches if they did it.
Custom demos available — manufacturing, HVAC, field service.
What would an openclaw built agent for enterprise look like on smart glasses? Openclaw + nemoclaw.
Built on a real catalogue-backed knowledge base + Google Sheet source of truth, with OmniaClaw as a customized OpenClaw UI layer—what you can do today still bumps into documented OpenClaw limits (tool host, local bridge wiring, channel UX). Demo shows supervisor → operator dispatch → voice → sheet anyway.
@sir4K_zen Got it. We can share a repo if you’d like and want to experiment running this on smart glasses. We’ll be posting the full voice input flow on the glasses themselves.
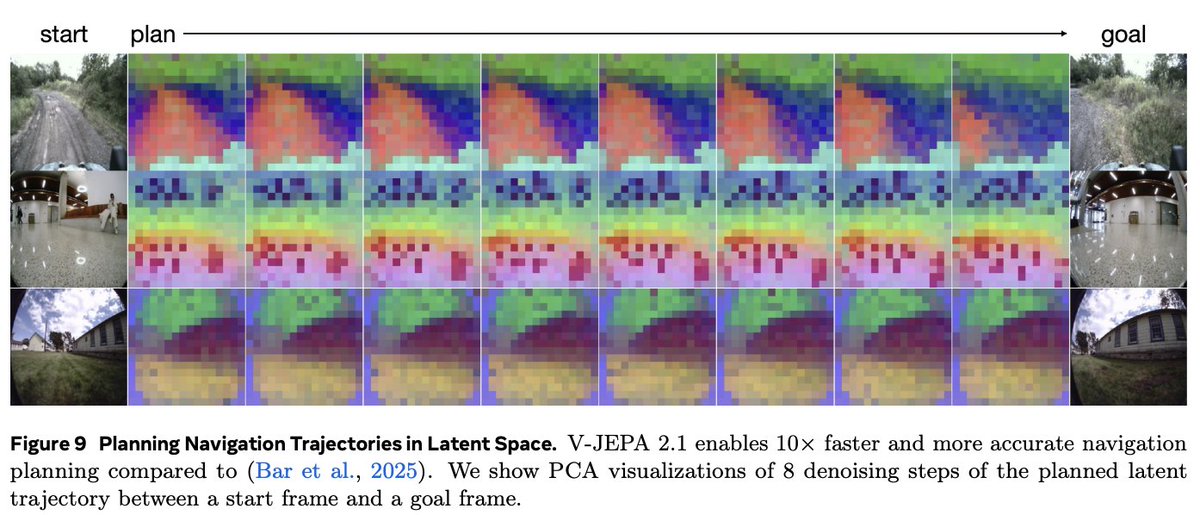
If you’re pitching “AI glasses,” ask whether your stack learns a compact predictive model of the scene. V-JEPA 2.1 is a strong citation for why JEPA-style video world models belong in the architecture, notas an optional add-on.
https://t.co/m6rytYO0Bh · Meta overview: https://t.co/irqI463Xa0 · Code: https://t.co/dJFeRcDBk6
V-JEPA 2.1 (Meta FAIR) is a video JEPA that learns dense representations from pixels: a predictive objective in latent space (not “generate every frame”), with deep self-supervision and a unified image+video encoder—so the model sees fine spatial structure and how it evolves over time.
For us (smart glasses): that’s the right kind of world model for egocentric wear—anticipation, depth-aware AR, stable perception under head motion, and a path to distilled on-device variants. Thread on what that means in practice ↓
9
Caveat builders should own: glass-grade latency still implies tethering or hybrid designs for the biggest variants today—but the representation you want on the device is exactly this flavor of predictive, dense, video-native model—not text-token physics.
8
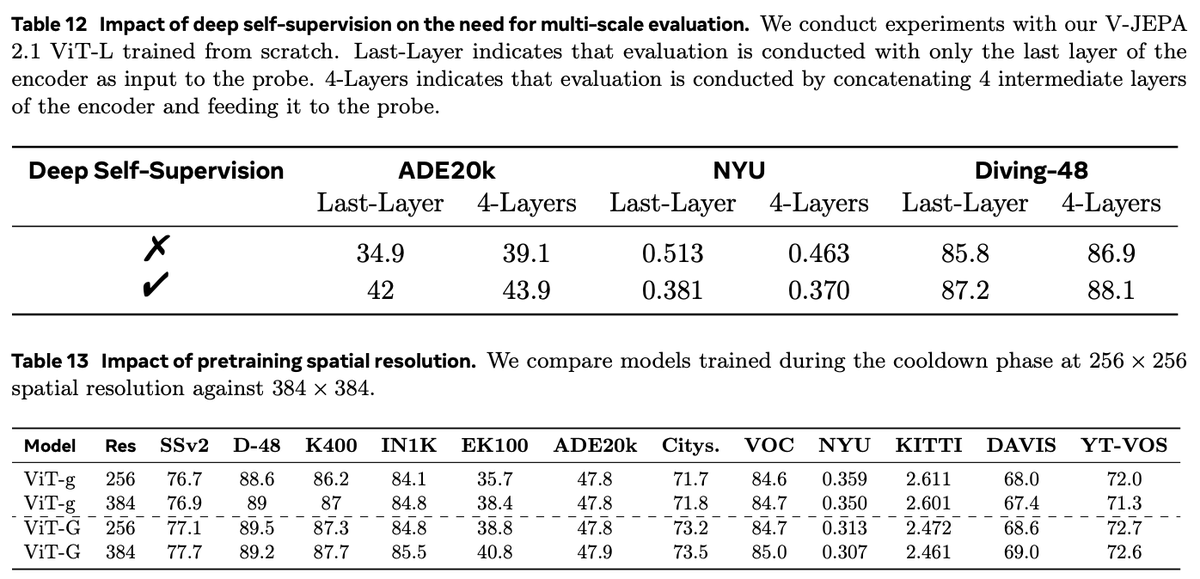
The ViT-G scale shows the ceiling, but distilled ViT-B / ViT-L are the manifesto point: thermal and compute on the face are real. The research program is explicitly edge-tractable if you architect for distillation, not only cloud giants.
7
Action / dynamics understanding (e.g. on standard video benchmarks) supports hands-busy tasks: cooking, assembly, repair—where the camera shakes and the task is procedural. World model + step-aware UI beats a raw LLM staring at JPEGs.
6
Strong depth from video (paper reports large gains on benchmarks like NYUv2) matters for AR occlusion, pinning, and plausibility—reducing the need to ship heavy depth hardware for every SKU (trade-offs remain; metric vs semantic).
5
On Ego4D, it pushes interaction anticipation—what object the user will engage with next. That’s the unlocked UX layer for GenUI: highlight the right thing before the hand moves, not after.
4
Unified visual memory (shared encoder for images + video) is huge for glasses: the same representation for a still glance and continuous wear. That’s how you get coherent “where was that / what changed?” behavior without juggling two vision backends.
3
Deep self-supervision stacks the objective across encoder layers. Translation for product: you get usable signal throughout the stack, which matters when you distill or prune for on-device.
2
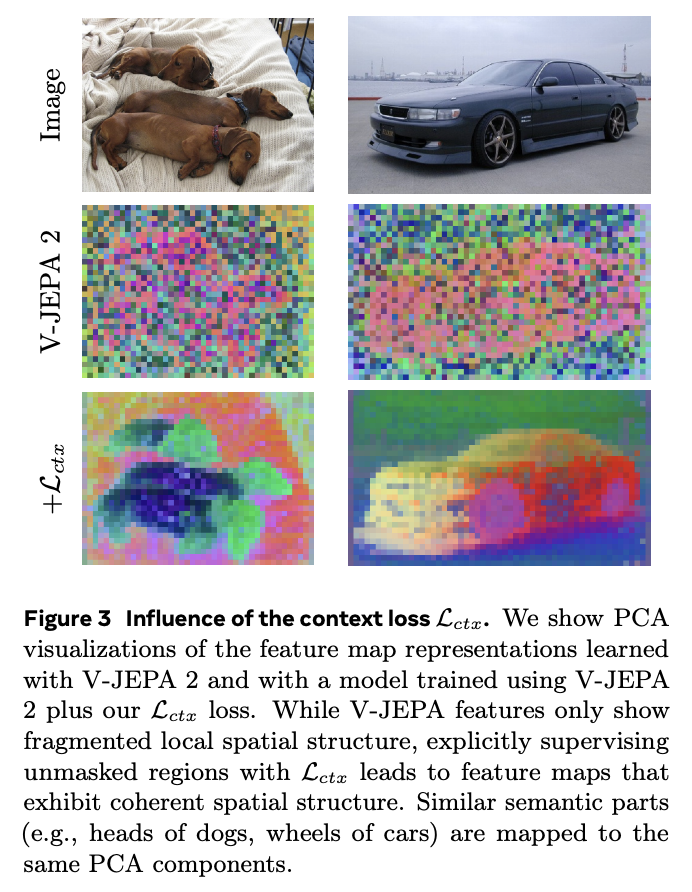
The dense predictive loss pushes the model to predict features for all tokens (masked and visible), not a patchwork where unmasked regions go blurry. For glasses, that means stable, localized perception under head motion—not smeared “video vibes.”
1
V-JEPA 2.1 learns dense spatio-temporal video representations: not just “what’s happening” globally, but local structure—boundaries, depth cues, fine detail— grounded in where things are in space and time. That’s the right object for egocentric wearables.