ONNX Runtime & DirectML now support Phi-3 mini models cross-platforms & devices! Plus, the new ONNX Runtime Generate() API simplifies LLM integration into your apps. Try Phi-3 on your favorite hardware! Read more: https://t.co/wCh8Ka92s2 #ONNX#DirectML#Phi3
Run PyTorch models in the browser, on mobile and desktop, with #onnxruntime, in your language and development environment of choice 🚀https://t.co/8DR8tRCGFm
Developers, don't overlook the power of Swift Package Manager! It simplifies dependency management and promotes modularity. Plus, exciting news: ONNXRuntime just added support for SPM! #iOSdev#SwiftPM#ONNXRuntime
#ONNX Runtime saved the day with our interoperability and ability to run locally on-client and/or cloud! Our lightweight solution gave them the performance they needed with quantization & configuration tooling. Learn how they achieved this in this blog!
https://t.co/gZbvAvDofJ
Maximize the power of LLMs! 💬 Our step-by-step guide covers fine-tuning for specific NLP tasks w/ GPT-3, OPT, & T5.
We shared everything from building custom datasets to optimizing inf time with @huggingface 🤗Optimum and @onnxai.🚀
https://t.co/7uYwGAVWR1
#LargeLanguageModels
Join us live TODAY! We will be talking to Akhila Vidiyala and Devang Aggarwal on AI Show with Cassie! We will show how developers can use #huggingface#optimum#Intel to quantize models and then use #OpenVINO for #ONNXRuntime to accelerate performance.
👇
https://t.co/lBAOoGWnA6
In this blog, we will discuss how to make huge models like #BERT smaller and faster with #Intel#OpenVINO, Neural Networks Compression Framework (NNCF) and #ONNX Runtime through #Azure!
👇
https://t.co/zRxMIFue42
🚀 Want easier and faster training for your models on GPUs?
Thanks to the @onnxruntime backend, 🤗 Optimum can help you achieve 39% - 130% acceleration with just a few lines of code change. Check out our benchmark results NOW!
👀 https://t.co/RJUCb826ji
We are seeking your input to shape the ONNX roadmap! Proposals are being collected until January 24, 2023 and will be discussed in February.
Submit your ideas at https://t.co/K6umbPGa2I
Imagine the frustration of, after applying optimization tricks, finding that the data copying to GPU slows down your "MUST-BE-FAST" inference...🥵
🤗 Optimum v1.5.0 added @onnxruntime IOBinding support to reduce your memory footprint.
👀 https://t.co/r8Vdhlmqlh
More ⬇️
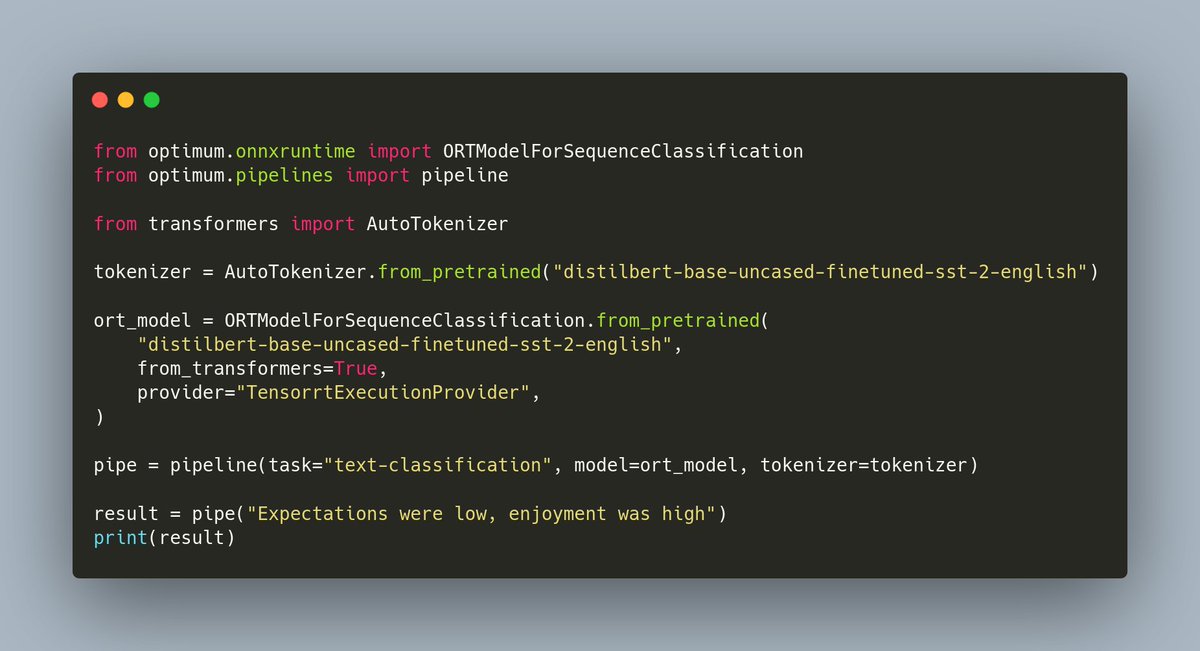
Want to use TensorRT as your inference engine for its speedups on GPU but don't want to go into the compilation hassle? We've got you covered with 🤗 Optimum! With one line, leverage TensorRT through @onnxruntime! Check out more at https://t.co/gPUrzy5Seq
📣The new version of #ONNXRuntime v1.13.0 was just released!!!
Check out the release note and video from the engineering team to learn more about what was in this release!
📝https://t.co/d4OS1r5Hw0
📽️https://t.co/usbiNyyk32
Finally tokenization with Sentence Piece BPE now works as expected in #NodeJS#JavaScript with tokenizers library 🚀! Now getting "invalid expand shape" errors when passing text tokens' encoded ids to the MiniLM @onnxruntime converted @MSFTResearch model https://t.co/oKtgpp3EDE
🏭 The hardware optimization floodgates are open!🔥
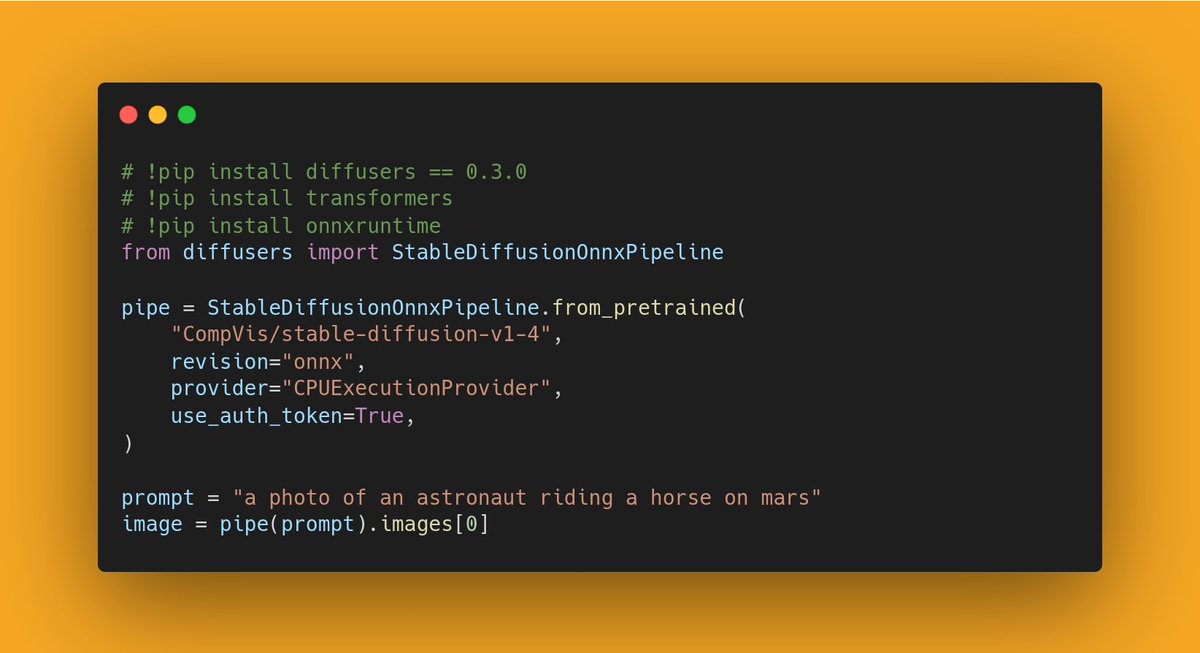
Diffusers 0.3.0 supports an experimental ONNX exporter and pipeline for Stable Diffusion 🎨
To find out how to export your own checkpoint and run it with @onnxruntime, check the release notes:
https://t.co/1sGixNDnip
The natural language processing library Apache OpenNLP is now integrated with ONNX Runtime! Get the details and a tutorial explaining its use on the blog: https://t.co/aGJUUYJflP #OpenSource
In this article, a community member used #ONNXRuntime to try out GPT-2 model which generates English sentences from Ruby language:
https://t.co/2Vap6qbYRv
Come join us for the hands on lab(September 28, 1-3pm)to learn about accelerating your ML models via ONNXRunTime frameworks on Intel CPUs and GPUs..some surprise goodies as well #IntelON#iamintel#intelarc@IntelGraphics @IntelSoftware @gfxlisa
https://t.co/L99FCj74jT