We've been pretty quiet about what we're building. That changes now.
Our reasoning framework is currently beating every @OpenAI model on industry standard benchmarks. There are six models in development. SERV-nano just matched GPT-5.4 at 20x lower cost and 3x the speed. The research paper backing it is in peer review at a top-1% AI journal. The UAE government is running it in production, so are 10+ enterprises.
Nothing comes even close.
This goes far beyond any wrapper or prompt engineering gimmick, we've developed an entire AI reasoning layer from scratch: structured, bounded, deterministic using machine readable code instead of vague english prompts.
Any builder or enterprise swaps two lines of code and their agents get much cheaper and much smarter instantly. The self-serve API is about to open, in a multi-phase rollout.
More soon.
This is the first step.
Together with NEOL, we’ve begun deploying SERV Reasoning into real government-grade AI workloads, already live with the UAE government.
NEOL uses AI agents to surface the right people, relationships, and institutional knowledge for governments and large institutions making high-stakes decisions.
For that to work, “usually right” isn’t enough.
The agent needs to be reliable, reproducible, and auditable.
SERV Reasoning enabled NEOL to move from brittle prompt-based agents to structured reasoning graphs their team can inspect, test, and improve systematically, reaching 100% accuracy on key production agents.
That matters because when a government client asks why a certain person was recommended, NEOL can now point to the reasoning structure behind the decision.
Not a black box.
Not a guess.
A traceable decision process.
This is the beginning of something much larger.
Every enterprise, government, and public institution trying to deploy AI into serious workflows will run into the same wall: agents that are too unreliable, too opaque, and too difficult to audit.
That is exactly the wall SERV Reasoning was built to break through.
Our aim is to keep expanding what we unlock with NEOL, deepen the relationship across more institutional use cases, and bring this same reasoning infrastructure to the enterprises and governments that need AI they can actually trust in production.
The future of institutional AI cannot run on todays infra, it needs specialized AI reasoning that can be tested, audited, reproduced, and trusted.
That is the institutional gap SERV is plugging.
MESH is the privacy-first AI router: one OpenAI-compatible endpoint in front of 46+ models, a signed receipt on every call, and zero payload retention.
SERV is the reasoning layer adding structured, schema-forced, auditable reasoning that routes each step to the right model instead of burning frontier tokens on everything.
Soon you'll be able to switch SERV on as an optional layer over every model and agent already on MESH
What that unlocks:
> Reasoning that stays inside defined bounds instead of drifting
> Signed receipts for the privacy, structured auditable steps for the logic
> Frontier-grade results without frontier-grade token bills
MESH's verifiable privacy meets .@openservai's SERV reasoning. Coming soon.
Orbit agents just got a major reasoning upgrade.
Previously, we upgraded the core XONA agent with SERV Reasoning by @openservai.
Now, we’re bringing the same upgrade across Orbit.
All 266 agents already built on Orbit are now aligned with SERV Reasoning, giving them faster execution, lower cost, and the same reliability we benchmarked on our production workflow.
This means Orbit agents can now reason, execute, and access XONA resources more efficiently across the Agentic Commerce ecosystem.
Build agents with Orbit. Power them with XONA. Reason with SERV.
at google play we looked for teams that had an "unfair advantage"; at least one of the following:
- a tech moat (proprietary IP, novel architecture)
- a structural moat (switching costs, lock-in)
- execution speed and quality (a moat in itself, especially in commoditised verticals)
rarest of unicorns are the ones that can combine all three.
with @openservai we're seeing how they all combine -> genuine tech differentiation in reasoning architecture. structural lock-in once enterprises integrate. a team executing faster and cleaner than anyone else in the category.
4 years of working with AI models, and using SERV Reasoning is their best experience yet…
Xona is building their own on-chain agent infrastructure, and now with SERV they’ve gained:
- 100% accuracy
- 30+% lower latency
- 5x more cost efficiency
This is not just a nice to have, its a game changer for an entire business.
One of many already supercharging their AI products with SERV, welcome.
Huge appreciation to the @openservai team for their full support throughout the process.
After 4 years of working with AI models, I can honestly say SERV Reasoning is one of the best combinations of performance and cost efficiency I’ve used.
Better reasoning. Faster responses. Lower cost.
A significant step forward for XONA.
Another independent benchmark from SERV Reasoning Private Beta:
serv-nano at 100% accuracy, while being 5x more cost-efficient and faster than raw Google Gemini
More cost-efficient
Faster
Reliable
Single-line swap and no vendor lock-in. no brainer for anyone building agents
Our agent just got a major upgrade - XONA agent is now powered by SERV Reasoning by @openservai.
We have been testing SERV in the Private Beta and it has far outpaced our default production stack running on Gemini frontier model. SERV delivers faster responses at a significantly lower cost, while maintaining the same 100% reliability in our workflow benchmark.
SERV Reasoning vs. Gemini on our agent workflow:
→ Accuracy & reliability: 100% for both models (20/20)
→ Latency: SERV responded 1,004 ms faster
→ Cost efficiency: SERV is 5x more cost-efficient
This upgrade helps us deliver better-performing resources for agents across the Agentic Commerce ecosystem.
Same reliability. Faster execution. Lower cost
Breaking: Product-market-fit for SERV Reasoning is here and is here to stay.
Anthropic currently does 25x subsidization to acquire their users. $200 in user spending incurs $5000 in costs on their books.
Their shareholders won’t allow this to last. Pricing WILL go up.
And concurrently, raw token consumption is exploding.
A solution that makes AI agents usable in high stakes settings with economics that actually work at scale, is desperately needed.
That solution is SERV Reasoning, and it’s already being adopted at lightning pace.
We’ve been working towards it for 2 years by a cracked research and engineering team.
The entire agent economy needs SERV Reasoning, it won’t work without it.
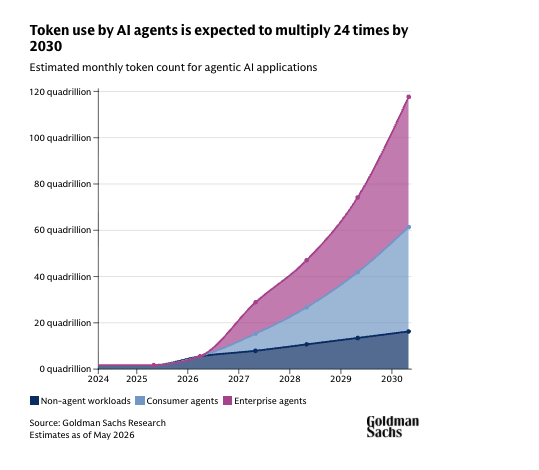
🚨 LATEST: Token consumption by AI agents is expected to surge 24x to 120 quadrillion tokens per month by 2030, driven by the rise of agentic AI, per Goldman Sachs Research.
🚨 THE AI COST CRISIS HAS STARTED.
Microsoft reportedly told engineers to stop using Claude because AI bills were exploding, while Uber says its entire yearly AI budget was already destroyed by April.