$VECTA is now LIVE on @Pumpfun
We're building decentralized inference that feels ordinary.
No complex infrastructure.
No confusing user experience.
We make it ordinary:
• OpenAI-compatible endpoints
• Transparent usage-based pricing
• Gas-free settlement on @solana
• Built for autonomous AI agents
The future belongs to agents.
OpenVecta is building the infrastructure they'll rely on.
CA: 4VBvCEMrPEU6yYF43pdahJafdHGaRxtMtKENqYpnpump
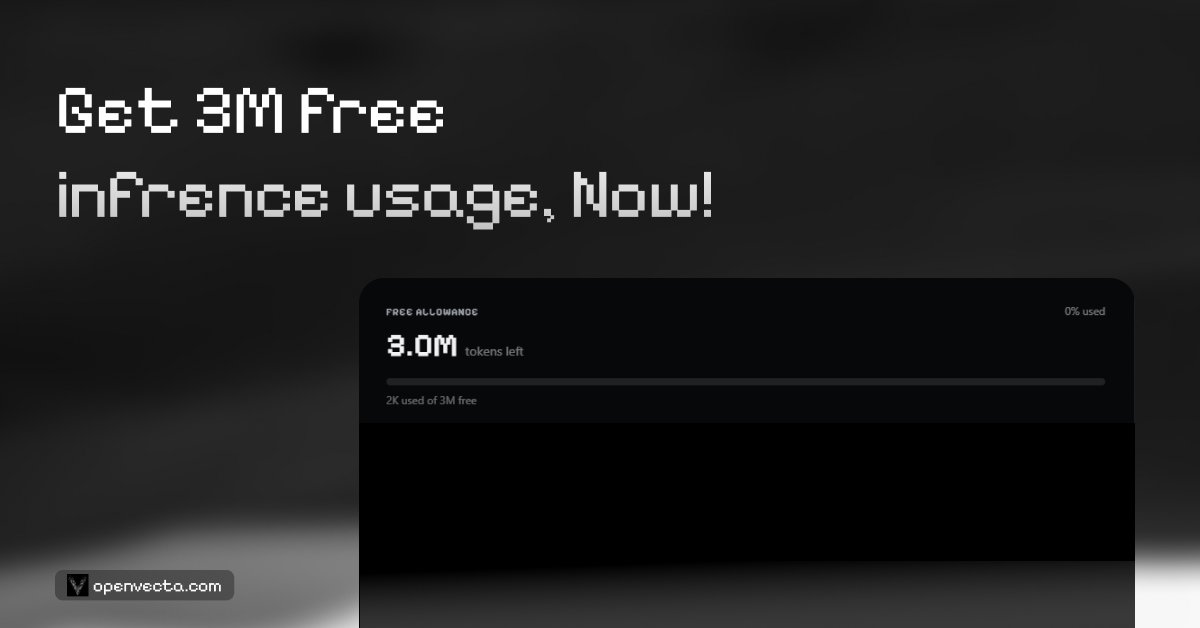
3M free inference tokens for every OpenVecta user.
Try GLM 5.2, Kimi K2.7 Code, Qwen3.5, Llama 3.3 70B, DeepSeek V4 Flash, and more.
Use the playground or plug OpenVecta into your agent stack.
No upfront cost.
OpenAI-compatible access.
Start building with OpenVecta.
Compute. Inference. Infrastructure. Capital.
This is exactly what Vecta is building.
Access multiple AI models through reliable infrastructure, without KYC, subscriptions, or gas fees.
Every request is settled seamlessly on @solana through @x402.
$VECTA is now LIVE on @Pumpfun
We're building decentralized inference that feels ordinary.
No complex infrastructure.
No confusing user experience.
We make it ordinary:
• OpenAI-compatible endpoints
• Transparent usage-based pricing
• Gas-free settlement on @solana
• Built for autonomous AI agents
The future belongs to agents.
OpenVecta is building the infrastructure they'll rely on.
CA: 4VBvCEMrPEU6yYF43pdahJafdHGaRxtMtKENqYpnpump
Shipping another feature.
Per-key spend limits are now live.
Every API key can now have its own spending policy.
Perfect for:
→ Production environments
→ Team access
→ AI agents
→ Cost control
Set your limits.
Monitor usage.
Scale with confidence.
Small feature. Big quality-of-life improvement for developers.
Shipping never stops.
This week on OpenVecta:
✓ MiniMax M3
✓ GPT-OSS-120B & GPT-OSS-20B
✓ Vision
✓ Embeddings
Next up:
→ Spend Limits
→ MCP Server
→ x402 Discovery
We're not here to chase narratives.
We're here to build the inference layer AI agents can rely on.
Same cadence.
More shipping.
The best inference layer isn't the one with the most models.
It's the one developers never have to think about.
One API.
Transparent pricing.
Automatic settlement.
Reliable routing.
When infrastructure disappears into the background, developers can focus on building.
That's the future we're building at Vecta.
Vecta can see now.
Vision is live on MiniMax-M3 and Qwen3.5-397B.
Your AI agents can now understand:
Images
Documents
Charts
Visual inputs
All through the same OpenAI-compatible API.
One endpoint.
Text + Vision.
Built for autonomous AI agents.
More capabilities. Same developer experience.
AI agents don't care who built the model.
They care about getting the right intelligence at the right time.
OpenVecta now supports GPT-OSS-120B and GPT-OSS-20B, bringing OpenAI's open-weight reasoning models to our inference network.
One endpoint.
Transparent usage.
Automatic settlement.
As the AI ecosystem grows, OpenVecta grows with it.
More models.
More intelligence.
One inference layer.
Everyone is building GPU supply.
Who's building the layer that makes it usable?
As sovereign compute and DePIN AI scale, developers need more than GPUs.
They need:
• OpenAI-compatible APIs
• Intelligent routing
• Usage metering
• Automatic settlement
OpenVecta is building that infrastructure.
Connect your private nodes or DePIN cluster.
Expose inference through a single, production-ready gateway.
New model available on Vecta.
@MiniMax_AI M3 is now live.
A powerful open-weight multimodal model optimized for:
→ Coding
→ Long-context reasoning
→ Agentic workflows
Access it through the same OpenAI-compatible endpoint with transparent usage-based pricing.
We're building the inference layer that connects AI agents to the world's best models.
More integrations coming.
Infrastructure should be invisible.
When you make an inference request, you should only pay for what actually happened.
OpenVecta measures every request in real time.
→ Exact input & output tokens
→ Transparent usage-based pricing
→ Automatic settlement behind the scenes
No hidden credits.
No confusing billing.
Just decentralized inference that feels ordinary.
Most AI APIs are built for humans.
AI agents aren't humans.
They shouldn't need credit cards, prepaid balances, or manual top-ups just to access intelligence.
OpenVecta uses @x402 to enable true agent-native payments.
→ Call an OpenAI-compatible endpoint
→ Usage is measured in real time
→ USDC settles automatically on @solana (gas-free)
No babysitting.
No payment friction.
Just inference, built for autonomous agents.
Try it with 3M free tokens → https://t.co/1QUmg7ZbOX
OpenVecta is not just a model access layer.
The first phase was proving that decentralized inference can feel ordinary.
Every request is metered.
Every settlement runs in the background.
Everything is handled gas-free on Solana.
Now the next phase is making inference smarter.
More models.
Better routing.
Inference optimization.
Less wasted usage.
More value from every call.
The goal is simple:
Make inference accessible, usable, and efficient for agents and apps.
3M free tokens for every OpenVecta user.
Test the models.
Try the playground.
Connect your agent.
Build without friction.
OpenVecta gives agents and apps OpenAI-compatible inference with real usage tracking and background settlement.
Your first inference should feel ordinary.
GLM 5.2 by @Zai_org with Hermes by @NousResearch on OpenVecta in action.
Long-horizon reasoning.
Coding workflows.
Agent execution.
OpenAI-compatible access.
Every request is measured.
Settlement runs in the background.
Gas-free on Solana.
Inference built for agents and apps.
Kimi K2.7 Code (@Kimi_Moonshot) on OpenVecta in action.
From a simple prompt to a working website structure, agents and builders can use coding-focused inference directly through OpenAI-compatible endpoints.
Usage is measured.
Settlement runs in the background.
Everything is handled gas-free.
Build faster with OpenVecta.
New model added on OpenVecta.
Llama 3.3 70B Instruct by @Meta is now available for agents and apps through OpenAI-compatible endpoints.
Use it for chat, reasoning, instruction-following, and agent workflows.
Every request is measured.
Settlement runs in the background.
Gas-free on @solana.
More models. More agent-native inference.
Kimi K2.7 Code (@Kimi_Moonshot) on OpenVecta in action.
From a simple prompt to a working website structure, agents and builders can use coding-focused inference directly through OpenAI-compatible endpoints.
Usage is measured.
Settlement runs in the background.
Everything is handled gas-free.
Build faster with OpenVecta.