Subnet 5 (SN5) is excited to announce the next major focus - building the world’s best performing and most general-purpose text embedding model.
Below we explain why this matters, why SN5 and what’s coming next -
Why?
Embedding models are the backbone of many cutting-edge AI applications, from semantic search to natural language understanding. Enhancing them unlocks superior performance for a multitude of downstream applications.
However, determining which embedding models to use, or perform the best in all contexts, can be a challenging task. Each model is trained on a different dataset and generalizes differently when applied to real-world or large-scale datasets, making such evaluations very difficult.
Why SN5?
Subnet 5 aims to develop the best-performing, most general-purpose text embedding model in the world. The model's performance will be evaluated against an infinitely large and dynamic dataset, serving as a proxy for an infinitely generalized benchmark, to ensure the highest possible level of domain generalization.
As a network, our model will continuously improve and adapt to the latest real-world knowledge. This dynamic evaluation will ensure that SN5’s embedding model not only surpasses existing state-of-the-art (SOTA) models, pushing the boundaries of industry performance, but also remains consistently competitive.
What's coming next?
In the coming weeks, we'll release a detailed technical update on our incentive mechanism.
Users and developers will also be able to track our key metrics and see live benchmarking vs existing SOTA embedding models.
Subnet APIs will be available to all, aiming to offer the best performing and most general-purpose embedding solution for developers across the world.
Stay tuned for more details!
OpenKaito Subnet 5 has taken a major step forward in powering large-scale, real-world applications.
The network’s text embedding models are now starting to power @KaitoAI Yaps' new real-time plagiarism checker.
This is one of the first real-time plagiarism checkers on any social media platform, protecting millions of Yaps users from content theft.
In the coming weeks, we plan to gradually scale up throughput while ensuring consistency and uptime.
More results and insights will be shared as well. Stay tuned!
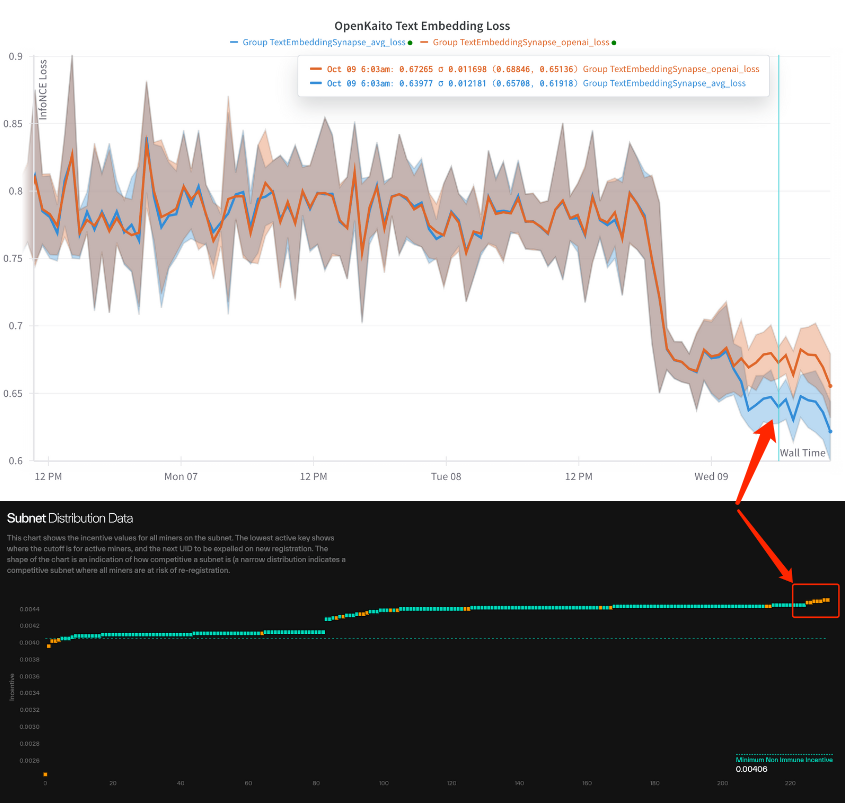
Further to our live benchmark surpassing OpenAI embeddings in both loss and top-1 recall on our infinitely large, dynamically generated synthetic dataset, new results show that SN5 miners are now outperforming OpenAI embeddings on an unincentivized, external, held-out benchmark.
This marks a true demonstration of an incentivized AI network's capability for generalization and practical application, delivering genuinely useful outputs. Stay tuned for more updates!
For more details, please visit the links below:
We’re excited to announce the launch of the SN5 operation dashboard!
The live dashboard provides valuable insights, enabling the entire Bittensor community to track model improvements as they happen.
Stay tuned for many more to come!
Milestone update -
2 weeks since the release of the new embedding task, miner loss has finally started to improve compared to the baseline OpenAI text-embedding model, driven mainly by newly registered miners today.
We expect this gap to further widen as competition continues to push for outperformance over time.
In the meantime, the design and production of the real-time dashboard is underway, allowing the entire Bittensor community to track model improvements as they happen.
Slowly, but surely!
We are excited to announce the upcoming release of OpenKaito v0.6.0, which is now available for public review at https://t.co/uiGQU1wKJ6.
This release includes the following updates:
- Beta release of 'TextEmbeddingSynapse', focusing on decentralized training for the most generalized and effective text-embedding models.
- Dynamic query generation for evaluation using extremely large text corpora.
- Integration of InfoNCE loss and top-k recall calculation for text embedding models.
Please note that this is a beta version of the next OpenKaito release. We have set up a validator on the testnet and assigned a small portion of task weight (20%) on the mainnet to bootstrap the new tasks. This task weight will gradually increase as it becomes the main task within this subnet.
Upon the full release, which we estimate will occur in about two weeks, we will deprecate the current DisordSearchSynapse and StructuredSearchSynapse (Twitter search) tasks. We will also provide a dashboard displaying loss and top-k recall curves for the text embedding models contributed by the community.
Miners can reference the baseline OpenAI text embedding model and train their own models for better performance. Validators should ensure their nodes are updated to the latest version, especially if auto-update is not enabled.
If you have any questions or encounter any issues, please feel free to reach out!
Subnet 5 (SN5) is excited to announce the next major focus - building the world’s best performing and most general-purpose text embedding model.
Below we explain why this matters, why SN5 and what’s coming next -
Why?
Embedding models are the backbone of many cutting-edge AI applications, from semantic search to natural language understanding. Enhancing them unlocks superior performance for a multitude of downstream applications.
However, determining which embedding models to use, or perform the best in all contexts, can be a challenging task. Each model is trained on a different dataset and generalizes differently when applied to real-world or large-scale datasets, making such evaluations very difficult.
Why SN5?
Subnet 5 aims to develop the best-performing, most general-purpose text embedding model in the world. The model's performance will be evaluated against an infinitely large and dynamic dataset, serving as a proxy for an infinitely generalized benchmark, to ensure the highest possible level of domain generalization.
As a network, our model will continuously improve and adapt to the latest real-world knowledge. This dynamic evaluation will ensure that SN5’s embedding model not only surpasses existing state-of-the-art (SOTA) models, pushing the boundaries of industry performance, but also remains consistently competitive.
What's coming next?
In the coming weeks, we'll release a detailed technical update on our incentive mechanism.
Users and developers will also be able to track our key metrics and see live benchmarking vs existing SOTA embedding models.
Subnet APIs will be available to all, aiming to offer the best performing and most general-purpose embedding solution for developers across the world.
Stay tuned for more details!
5 Cool Bittensor Subnets to Test Out
Great write up from Bankless on Bittensor subnets.
Super excited to show you all what we've been building in the background using OpenKaito's Subnet 5.
Soon 👉 @openkaito
Introducing OpenKaito -
At Kaito, our mission has always been to democratize information access in crypto. Since our launch in Q4, we’ve quickly grown to become one of the fastest growing AI companies in the space, solving real pain points and pushing the boundary of what AI can do for crypto.
While we continue to push innovation in our core subscription-based offering, we’ve never forgotten about the large, underserved retail communities. Our partnership with Bittensor @opentensor aligns with our long-term commitment to making search - and ultimately information access - as open, accessible, and decentralized as possible.
This marks our first step in exploring, experimenting, and reimagining how search in a decentralized world could be, and a continuation of some of our recent initiatives, including open sourcing Ethereum-related multimodal content, in collaboration with the Ethereum Foundation.
Over the long term, we envision a decentralized search layer that is fully composable in domain information (web3 or non-web3), transparent in search ranking, and scalable in system design. In that setup, while OpenKaito may leverage our experience to build a freely accessible search engine for crypto, we would welcome any teams to come and build on top of this open layer.
The road ahead is going to be fast-changing and uncertain, but we are calling on every one of you to join us on this journey. Together, we'll work to ensure our future generations will have fair and equal access to high-quality information in a decentralized era.