Here's our ODBC Driver Administrator Skill for creating and testing ODBC Data Source Names (DSNs). It's usable by any AI Agent and platform that supports the SKILLS.md open standard.
Benefit?
It makes ODBC easier to use, which means DBMS independence just got a lot simpler!
Some additional links showcasing different AI agents, AI agent skills, and large language models (LLMs).
Claude Code AI Agent, DeepSeek-v4 LLM, and the same AI agent skills:
1. HTML-based Infographic (notes summary) -- https://t.co/QdzUufBhJM
2. Knowledge Graph Overview via Faceted Search & Browse Page -- https://t.co/Y3WzvmgNUI
Showcasing the combined power of the following for note-taking and the progressive creation and management of knowledge bases:
1. Hyperlinks as powerful super keys for data, information, and knowledge access by reference
2. RDF for entity descriptions in machine-computable form, using subject–>predicate–>object structured data representation
3. HTML for hypermedia document creation
4. A universal filesystem interface for CRUD (Create, Read, Update, Delete) operations
How?
This knowledge base update workflow requires just a few simple steps:
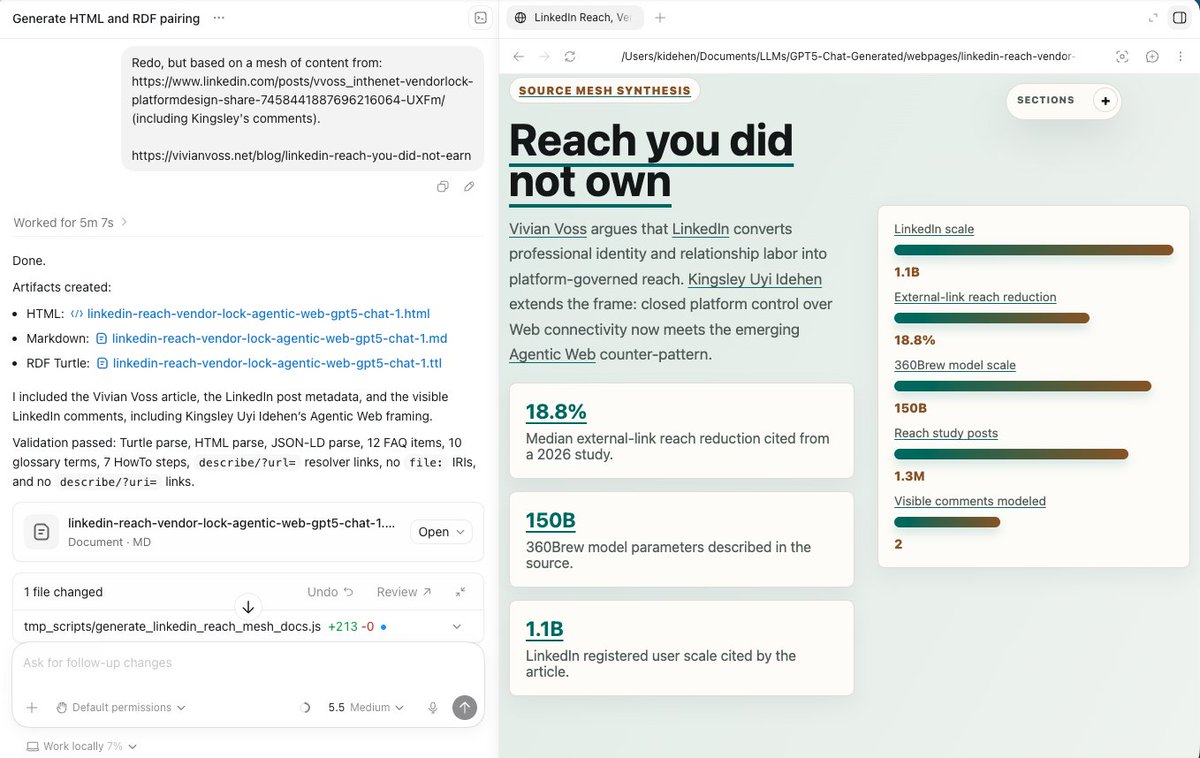
1. Prompt any AI agent (Claude Code, Codex, and similar tools) as follows: Generate an RDF knowledge graph and HTML breakdown document from {document-url}
2. Drag and drop the generated RDF and HTML documents into an HTTP-accessible folder mounted on your local device (desktop, notebook, or phone)
3. Open the HTML document and follow your nose into the underlying knowledge graph
4. Rinse and repeat whenever you encounter content containing knowledge you want to reuse and recall—simply by querying your AI agent of choice
Why should you care?
Because this shifts knowledge work from passive consumption to active, reusable structure.
Instead of re-reading and re-searching, you progressively build a personal (or organizational) knowledge layer that is:
* Queryable via AI agents
* Reusable across contexts and time
* Deterministic in retrieval when combined with structured representations
* Incrementally improving with every document you process
* Independently owned rather than locked inside proprietary silos
In short, it turns everyday reading into compounding intellectual infrastructure.
What makes this “deceptively simple” workflow possible?
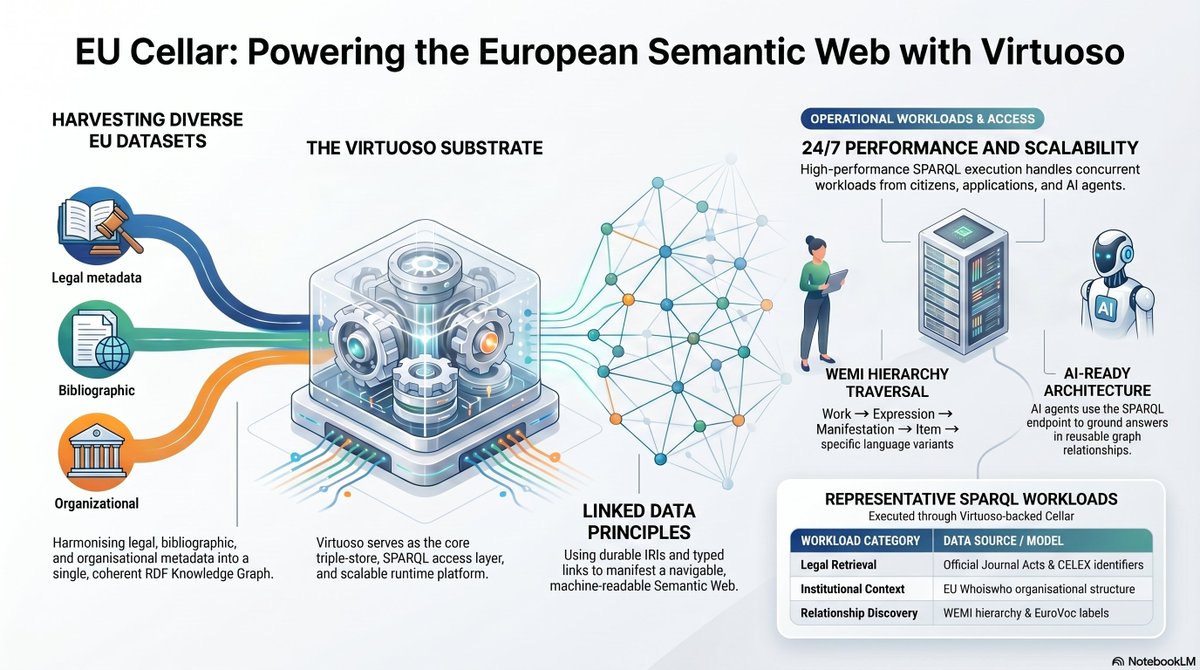
Our Virtuoso platform, which provides modern data space management (databases, knowledge bases, filesystems, and APIs) that blends naturally with the new age of AI agents and agent skills.
See comments section for links to documents generated in the demo.
Oh the darn irony, since I can make the following in an Agentic Web, and Web 2.0 silos can't do a thing about it beyond artificially constraining its distribution range.
https://t.co/NFgoUYLlTi
#NoSilo#Web20#AgenticWeb#SemanticWeb#LinkedData#HowTo
Links:
[1] https://t.co/vvXwGzMceT -- HTML document that breakdown the RDF 1.2 primer doc
[2] https://t.co/93QdkLYPIl -- Mardown rendition of HTML doc
[3] https://t.co/yJ5SuTfgTv -- Faceted Search & Browsing based HTML page
[4] https://t.co/Bi23pwAM6D -- SPARQL Query Results Page
In all cases, just click to explore using the follow-your-nose pattern.
Links:
[1] https://t.co/S1tzUOMMDs -- HTML document generated by an AI Agent Skill that's associated with RDF documents automagically uploaded to Virtuoso's WebDAV filesystem using basic drag and drop.
[2] https://t.co/i1nPLGHNoM -- Folder listing that further demonstrate powerful use of the universal filesystem interface (file types and folders) for progressive knowledge base enrichment using the LLM Wiki flow pattern.
How AI Agent Skills are taking the tedium out of both the representation and access of data, information, and knowledge.
Here's what a skill for generating knowledge graphs from any document did with the European Union's Publishing Office data space, using a variety of document types.
See comments for live links.
💥Boom💥
A new release of our Virtuoso platform for managing data spaces—databases, knowledge bases, filesystems, and APIs—loosely coupled with AI agents and skills.
In this new age of AI, much like the original vision of Semantic Web, Virtuoso is a platform that has effectively been waiting for natural language to become its generic interface, all while remaining grounded in open standards.
Think SQLite, PostgreSQL, etc.—but, in addition to native SQL support, Virtuoso also supports SPARQL, GraphQL, GQL, and openCypher, while handling HTTP and WebDAV natively. This enables hyperlinks to function as superkeys that go far beyond the capabilities of siloed primary and foreign keys.
Virtuoso makes Web connectivity 100x more powerful because it uniquely blends connectivity with sophisticated data, information, and knowledge management.
One more thing: it also uniquely exposes native stored procedures for interaction via the Model Context Protocol (MCP) or as OpenAPI-spec-compliant APIs.
Enjoy!
Demo links in comments section.
The latest open source edition of our Virtuoso platform is now live!
At its core, Virtuoso is a high-performance, secure, and highly scalable, multi-model database management system (DBMS) supporting both relational tables and fine-grained entity relationship graphs.
How is the web changing due to AI?
@kidehen gives me a master class.
Reposted since the people who hacked me yesterday deleted it.
Grok says it is a must watch. More in comments about what you will learn by watching it.
Can't believe that it's been 25 years since Tim Berners-Lee posted his famous paper about the semantic web. Took that long to make it real, and here it is.
Our #VirtuosoRDBMS makes understanding and utilizing the power of a Semantic Web in the age of AI remarkably easy. Just drag and drop a file into a mounted folder and enjoy the magic that makes HTTP connectivity—public or private—100x better.
Dogfooding was one of RDF’s biggest challenges prior to the arrival of LLMs as powerful general-purpose clients. Why? Because transforming and presenting RDF specifications in RDF form was difficult. Today, that problem is gone. Here’s an example of the new RDF 1.2 primer, deployed as a knowledge graph that uses Linked Data principles to manifest a Semantic Web.
Tools used:
1. Anthropic’s Claude Code as the AI agent
2. DeepSeek-v4 as the LLM
3. Virtuoso Data Spaces platform, comprising:
* A WebDAV-based filesystem for hosting generated RDF, HTML, and Markdown documents
* A high-performance DBMS engine that automatically ingests and manages these documents
* Support for RDF graphs and relational tables accessible via SQL, SPARQL, GraphQL, etc. (note: we also have openCypher and GQL in the works to bury all distractions)
Why Should You Care About Dogfooding RDF 1.2 Specs?
You can ask a variety of questions via any AI agent that supports skills against the generated knowledge graph. All you need to do is load the Data Twingler skills and query using natural language, without being tripped up or distracted by hallucinations (since these skills include a KG-only mode that ensures no access to an LLM’s native graph unless you explicitly enable that modality).
See comments for links to live documents.
@Scobleizer’s unfortunate vishing hack also turned into a Semantic Web dogfooding demo, showcasing the power of our #VirtuosoRDBMS and its magic folders that bridge filesystem interactions with knowledge graph uploads into its RDF data management engine.
@Scobleizer got hacked following the release of this Semantic Web chat and demo session with @kidehen (our CEO), yet this document hasn’t missed a beat—courtesy of fundamental Web principles that begin with the use of hyperlinks as unambiguous entity identifiers.
Understanding why a Semantic Web is a 100x boost for the connectivity infrastructure the Web continues to unveil.
For starters, it keeps everything loosely coupled and accessible—i.e., no silos. In addition, it creates a new surface for commerce and markets that are not artificially controlled by algorithms—the biggest business pain point on the planet right now.
See how the session with @Scobleizer is described via skills invoked by an AI agent:
https://t.co/jnutUnMiMO
/cc @timberners_lee (who really should have been denoted by his identifier/handle on this platform) 😀
This Vivian Voss story about the takeover of Web connectivity reads like Shakespeare’s Macbeth (Web 2.0), especially as Macduff (the Agentic Web) begins to take shape.
https://t.co/bZDwqGzOig
My recent session with @Scobleizer explored the Agentic Web, buoyed by a resilient Semantic Web—essentially, how the Semantic Web vision had been waiting for LLM-powered AI.
My iPhone served as the camera.
Enjoy!

![kidehen's tweet photo. Document Links:
[1] RDF-Turtle Document containing the knowledge base, in knowledge graph form constructed using hyperlinks -- https://t.co/kaaWdlspTY
[2] HTML document -- https://t.co/8HAw9kjw7U
[3] Sample Entity Description via HTML doc -- https://t.co/8YMYumQPYh
[4] SPARQL query results page that provides an alternative entry-point for generated Knowledge Graph exploration -- https://t.co/EYl03Bo4lx
#SPARQL #VirtuosoRDBMS #AI #AgenticWeb #LinkedData #KnowledgeGraphs #Explainer #HowTo](https://pbs.twimg.com/media/HHqQ_CMWkAEeUbP.jpg)
![kidehen's tweet photo. Document Links:
[1] RDF-Turtle Document containing the knowledge base, in knowledge graph form constructed using hyperlinks -- https://t.co/kaaWdlspTY
[2] HTML document -- https://t.co/8HAw9kjw7U
[3] Sample Entity Description via HTML doc -- https://t.co/8YMYumQPYh
[4] SPARQL query results page that provides an alternative entry-point for generated Knowledge Graph exploration -- https://t.co/EYl03Bo4lx
#SPARQL #VirtuosoRDBMS #AI #AgenticWeb #LinkedData #KnowledgeGraphs #Explainer #HowTo](https://pbs.twimg.com/media/HHqQ_CLXwAcOeOM.jpg)















![kidehen's tweet photo. Document Links:
[1] RDF-Turtle Document containing the knowledge base, in knowledge graph form constructed using hyperlinks -- https://t.co/kaaWdlspTY
[2] HTML document -- https://t.co/8HAw9kjw7U
[3] Sample Entity Description via HTML doc -- https://t.co/8YMYumQPYh
[4] SPARQL query results page that provides an alternative entry-point for generated Knowledge Graph exploration -- https://t.co/EYl03Bo4lx
#SPARQL #VirtuosoRDBMS #AI #AgenticWeb #LinkedData #KnowledgeGraphs #Explainer #HowTo](https://pbs.twimg.com/media/HHqQ_CRWYAQHuAm.jpg)






![kidehen's tweet photo. Links:
[1] https://t.co/vvXwGzMceT -- HTML document that breakdown the RDF 1.2 primer doc
[2] https://t.co/93QdkLYPIl -- Mardown rendition of HTML doc
[3] https://t.co/yJ5SuTfgTv -- Faceted Search & Browsing based HTML page
[4] https://t.co/Bi23pwAM6D -- SPARQL Query Results Page
In all cases, just click to explore using the follow-your-nose pattern.](https://pbs.twimg.com/media/HIDX3P0WQAAnS17.jpg)