I'm attending #ICASSP2025 and presenting FlashSR. I’d love to connect with anyone interested in audio super-resolution, audio generation, diffusion, flow matching, or related topics. Please feel free to stop by the session or message me for a coffee chat.
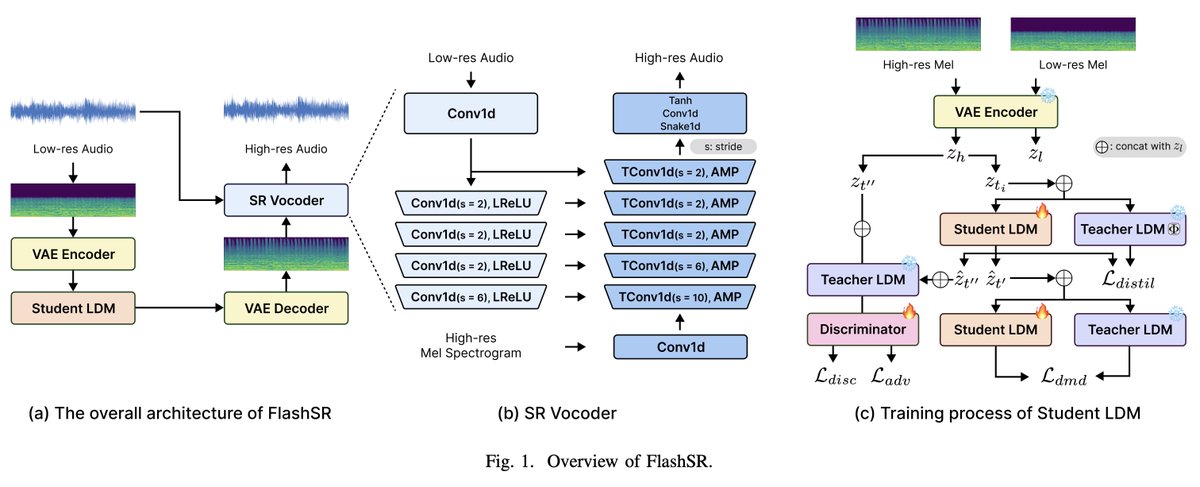
🌟 Excited to announce the release of the code and model weights for FlashSR: One-step Versatile Audio Super-resolution via Diffusion Distillation, accepted at ICASSP 2025! 🎉
🔗 Check out the demo, code, and paper here: https://t.co/I2JfTmWsHl
⚡ Achieves performance approximately 14 times faster than real-time on a single A6000 GPU.
🔬 Applies diffusion distillation to the audio super-resolution task, and introduces the SR Vocoder, specifically designed for SR models operating on mel-spectrograms.
🌟 Excited to announce the release of the code and model weights for FlashSR: One-step Versatile Audio Super-resolution via Diffusion Distillation, accepted at ICASSP 2025! 🎉
🔗 Check out the demo, code, and paper here: https://t.co/I2JfTmWsHl
🚀 A one-step diffusion model for audio super-resolution that can upsample various types of audio—music, speech, and sound effects—from any sampling rate between 4kHz and 32kHz to 48kHz.
hi music people, i wrote a tutorial on large language models and music information retrieval. of course it's called..
LLMs <3 MIR
🥁 have fun!
https://t.co/g7VXyW0lgd
Are you wondering how to make a Synchronized Foley Sound for Sora-made videos? Here’s our work 🔊T-Foley. (ICASSP 2024)
Demo https://t.co/0dm6WUXymQ
Code https://t.co/48OyVRFzaZ
(It was a pleasure to work with @yo__j__)
Super excited to share my work "DIFFRENT: A Diffusion Model for Recording Environment Transfer of Speech" at #ICASSP2024 on April 17th.
Looking forward to connecting with many researchers :).
I'm always up for a coffee chat too!
Demo: https://t.co/PjgAQMHWzT
DIFFRENT: A Diffusion Model for Recording Environment Transfer of Speech
Proposes a diffusion model to transfer the environment from a reference sound to a new recording taking into account the microphone and placement, room acoustics, and ambient noise.
https://t.co/nZ5vALZdOH
https://t.co/z533CBcKuR
Our paper about DCASE Challenge T7 - Foley Sound Synthesis was accepted to the DCASE Workshop 🥳
I can't make it to Finland🇫🇮, but some of the authors will be there to tell you what we went through while organizing the first generative challenge at DCASE.
Organizers:
Keunwoo Choi, Jaekwon Im, Gaudio Labs
Keisuke Imoto, Doshisha U
Mathieu Lagrange, CNRS/Ecole Central de Nantes
Laurie Heller, CMU
Brian McFee, NYU
Yuki Okamoto, Ritsumeikan U
Shinnosuke Takamichi, The U of Tokyo
@KeisukeImoto@keunwoochoi@forthshinji@osalooloo