A few weeks ago, I was blown away by @windsurf_ai IDE! Next step: a multimodal approach (video+text+audio) so we can "show" code while explaining logic—like a screen record in a tech issue.
@dunglas Amazing! Thanks for the pointer, @dunglas! I checked the page you shared but couldn’t find any mention of the BoltDB you referenced. Is there any other documentation or guidance you could point me to?
Hey @dunglas, hope all’s well! I’m exploring https://t.co/SjdW8AQTpm for handling SSE auto-retries on network failure. Does Mercure have a built-in feature to store/buffer events for client auto-retry, or is it something we typically manage on the backend?
o3 just dropped and it’s a monumental leap in AI capabilities. From blazing code gen to near-human performance on the ARC AGI test (yes, that test), it changes what we thought AI could do. Exciting? Absolutely. Terrifying? A bit. Hardware is now the real bottleneck. Buckle up!
Our new models — fully integrated alongside our database — bring best-in-class retrieval to your applications:
✔️ Our new sparse embedding model — pinecone-sparse-english-v0 — boosts performance for keyword-based queries, delivering up to 44% and on average 23% better NDCG@10 than BM25 on TREC.
✔️ Our new reranking model — pinecone-rerank-v0 — improves search accuracy by up to 60% and on average 9% over industry-leading models on the BEIR benchmark.
✔️ @cohere's latest model — cohere-rerank-v3.5 — balances performance and latency for a wide range of enterprise search applications.
Learn more by visiting our Model Gallery: https://t.co/AaUJqbB3WH
First-of-its-kind Pinecone Knowledge Platform Powers Best-in-class Retrieval for Customers
💠 Industry-leading vector database capabilities combined with proprietary AI models help developers build up to 48% more accurate AI applications: faster & easier
https://t.co/Pz9GkmUUe8
I’ve been working and building products with generative AI for over 4 years now. It’s hard to impress me at this point. But damn, @windsurf_ai, your IDE is absolutely next-level! 🔥
New in Copilot Chat... enhanced links for any workspace symbols that Copilot mentions 🔗
These links appear in responses as little pills, letting you jump directly to definitions for better understanding.
Pretty excited about this new RAG technique I cooked up 🧑🍳
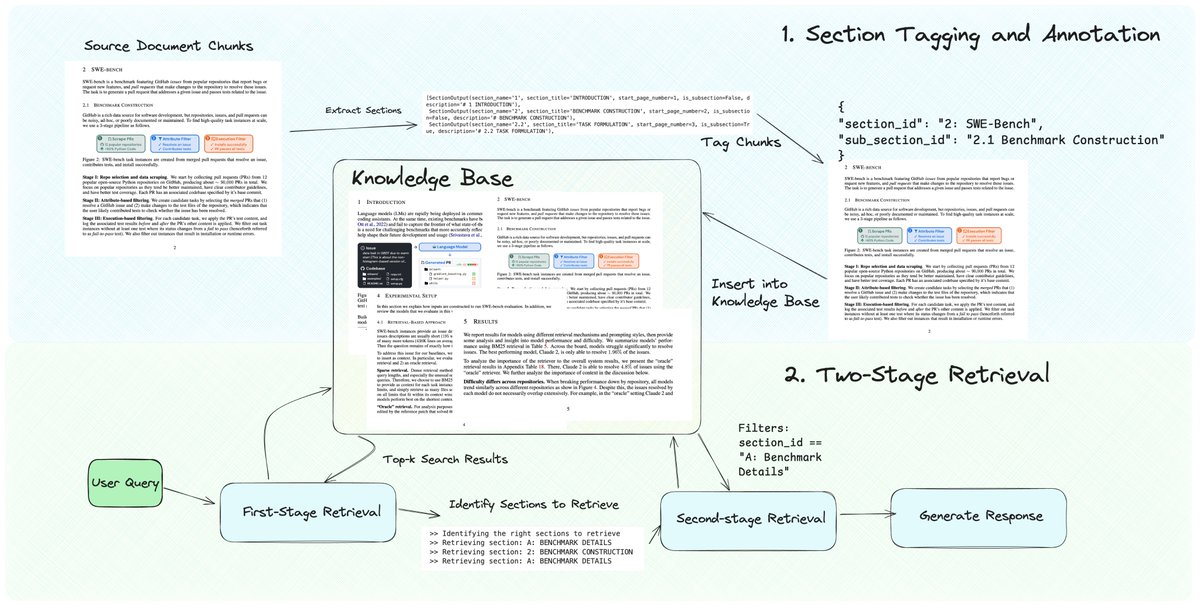
A top issue with RAG chunking is it splits the document into fragmented pieces, causing top-k retrieval to return partial context. Also most documents have multiple hierarchies of sections: top-level sections, sub-sections, etc.
This is also why lots of people are interested in exploring the idea of knowledge graphs - pulling in "links" to related pages to expand retrieved context.
This notebook lets you retrieve contiguous chunks without having to spend a lot of time tuning the chunking algorithm, thanks to GraphRAG-esque metadata tagging + retrieval. Tag chunks with sections, and use the section ID to expand the retrieved set.
Check it out
https://t.co/mIolxuMT12
Text chunking now matches human reading patterns by detecting natural breaks in information flow.
Meta-chunking, proposed in this paper, uses probability patterns to find natural segment boundaries in documents, just like humans do
Original Problem 🎯:
Text chunking in Retrieval-Augmented Generation (RAG) systems often fails to maintain logical coherence between segments, leading to incomplete or fragmented information retrieval. Current methods rely on fixed-length splits or basic semantic similarity, missing crucial logical connections between sentences.
-----
Solution in this Paper ⚡:
• Meta-Chunking: A novel segmentation technique operating between sentence and paragraph levels
• Two key strategies:
- Margin Sampling: Uses LLMs for binary classification to determine segment boundaries based on probability differences
- Perplexity (PPL) Chunking: Analyzes perplexity distribution to identify natural text boundaries
• Dynamic combination approach to balance fine and coarse-grained segmentation
• KV caching mechanism for handling longer texts efficiently
-----
Key Insights 💡:
• Smaller models (1.5B parameters) can effectively perform chunking tasks
• PPL distribution characteristics guide optimal threshold selection
• Dynamic chunk sizing preserves logical integrity better than fixed-length approaches
• Re-ranking performance improves significantly with Meta-Chunking
-----
Results 📊:
• Outperforms similarity chunking by 1.32 on 2WikiMultihopQA while using only 45.8% processing time
• PPL Chunking with Qwen2-1.5B achieves 0.3760 BLEU-1 score on single-hop queries
• Maintains consistent performance across both Chinese and English datasets
• Shows 3.59% improvement in Hits@8 metric when combined with PPLRerank
This project tries to implement a real-time replication of OpenAI’s groundbreaking O1 model.
Exploring advanced reasoning capabilities and a specific "journey learning" mechanisms for AI.
They propose a new approach: “journey learning”. This paradigm goes beyond the traditional focus on specific tasks and emphasizes continuous progress through learning, reflection, and adaptation.
Wow! @HeyGen_Official just released today ability to have an AI avatar join a Zoom meeting and interact.
I invited one of their AI avatars into a Zoom room and recorded this clip. Time to build my own now
Wow! @HeyGen_Official just released today ability to have an AI avatar join a Zoom meeting and interact.
I invited one of their AI avatars into a Zoom room and recorded this clip. Time to build my own now