In twelve months, EVERY company will be running a Company Brain.
The teams who build it this year will spend the next year compounding. Everyone else is going to play catch up.
Here's what it actually is. You connect your Slack, your GitHub, HubSpot, all your tools into one intelligence layer, then build the org chart around it: a main brain up top, a fleet commander running the agent fleet, specialist sub-agents handling execution.
The reason it works is change management basically disappears. Your team already lives in Slack. You're just adding agents to the room they're already in.
You NEED to start building yours now. In a year this will stop being an advantage and will become table stakes.
AMD CEO Lisa Su just killed Nvidia’s $4,000 AI box with a $1,499 lunchbox.
She walked on stage, held it in one hand, and ran a 235 billion parameter model live. No data center. No cloud. No rented GPU.
The chip inside is something nobody saw coming. AMD’s Ryzen AI Max+ 395 is the first x86 silicon where CPU and GPU share the same 128GB of memory. That single trick lets a desktop run models that used to need a server rack.
Out of those 128GB, Linux hands the GPU 110GB to play with. For context, an RTX 5090 gives you 32GB. A 4090 gives you 24. This box gives you more than three times either of them, in a chassis the size of a thick paperback.
The benchmark that broke the room: this chip beat an Nvidia RTX 5080 by more than 3x on DeepSeek R1 inference. A $1,499 lunchbox outrunning a $1,000 discrete graphics card on a real AI workload. Nvidia spent a decade convincing the world you needed their hardware for serious AI. AMD just put that on a desk for half the price.
Here is what nobody is telling you. A heavy AI user right now pays $200 for Claude Code Max, $200 for ChatGPT Pro, $20 for Cursor, $20 for Gemini. That is $5,280 a year leaving your account. The box pays itself off in 9 months and then runs free for the rest of its life.
Install Ollama. Pull Qwen3 235B. Point Claude Code at localhost. Same interface you already use, except now nothing leaves your machine, nothing costs per request, and no company throttles your usage at 3am when you finally have time to build.
This is the moment every AI subscription becomes optional. Lawyers stop fearing OpenAI leaks. Developers stop watching the token meter. Founders stop renting H100s for prototypes that never ship because the bill scared them.
The first thousand people to figure this out will own the next two years of private AI consulting.
Save this, and read the full breakdown article below you are watching the next shift hit before everyone else does.
Karpathy said something you'll regret ignoring:
"Remove yourself as the bottleneck. Maximize your leverage. Put in very few tokens, and a huge amount of stuff happens on your behalf."
Loop engineering is the exact thing that does that.
In a hand-run session, the operator handles two things:
- deciding what the agent runs next
- and checking its output before the next step
Both are manual, and both decide how far the agent gets on its own without the operator.
Loop engineering moves both steps into the system.
A core operating structure surrounds the loop, and the diagram below depicts it.
- A schedule decides what to run
- Loop is the maker that produces the work
- A separate checker agent grades the output
- A file on disk holds the state they both read.
The loop runs until either done, max iterations, or an exhausted budget.
Here are some practical engineering considerations:
1) A model grading its own output justifies what it already did instead of catching where it failed.
That's why a separate checker's findings return to the maker as the next instruction. And the cycle repeats until the checker finds nothing left to fix.
2) A loop with no stop condition burns tokens, and the cost climbs fast once sub-agents and long runs add up.
That's why the exit must be set before the loop runs, not while it is running.
A simple exit could be:
↳ fix only the major issues, run one final pass, and stop after two loops, with "all tests pass and lint clean" as the rule that ends it.
3) State has to live on disk, not in context.
The model forgets everything between runs, so an MD file or a knowledge graph holds what is done and what is still open.
Each run reads it and writes back to it, which lets a loop pick up again after days.
4) The lower the verification bar, the safer the loop.
Boring, repetitive checks like a stale version string or a missing test are trivial to verify, so a loop runs them with little risk while the operator is away.
Judgment-heavy work is loopable too, but only as far as the checker can confirm the result.
Let's look at how an unattended loop fails in two ways.
1) It reports done when nothing is actually verified.
The separate checker exists to prevent it, but it merges code faster than anyone reads it, so over weeks, the team stops understanding its own codebase while every check stays green.
Green tests say the code passed the tests, not that anyone knows what shipped. Someone still has to read what the loop merges.
2) The checker keeps a running loop honest, but it only catches failures inside a run.
The harness around the loop, like the prompts, tools, and checks wrapped around the model, still drifts and breaks in production as models change.
That repair loop is usually run by hand based on observability traces.
My co-founder wrote a detailed walkthrough (with code) on making that harness repair itself, where a failing trace gets diagnosed, the fix is verified against the exact input that failed, and the failure is locked as a regression test so it cannot recur.
Read it below.
Ramp is solving a very difficult problem. Token utilization for intelligence gained is the mystery black box of our times...and they have taken a good first stab at solving the problem
Today, Ramp raised $750M at a $44B valuation.
Last time we grew this fast, we were 1/20th the size.
For 2000 years, business was built on two pillars. Today, a third: intelligence.
It’s your least governed cost. It’s also your single greatest opportunity.
We uncovered something far bigger than I ever expected. After seeing coordinated false attacks against the Utah data center project, we brought in an advanced data science team to trace where the content was coming from and the results were shocking. What we found led back to organized networks, political activist groups, and funding trails tied to massive international entities. We dug through IRS 990 filings, tracked IP data from around the world, and uncovered what appears to be a coordinated campaign targeting energy and data center projects across multiple regions.
I shared 90 pages of evidence with federal law enforcement and raised concerns directly with contacts at the White House. This isn’t speculation. The filings, funding records, dates, and connections are documented. There’s a coordinated PR war happening around energy infrastructure and data centers, and we’re not going to ignore it.
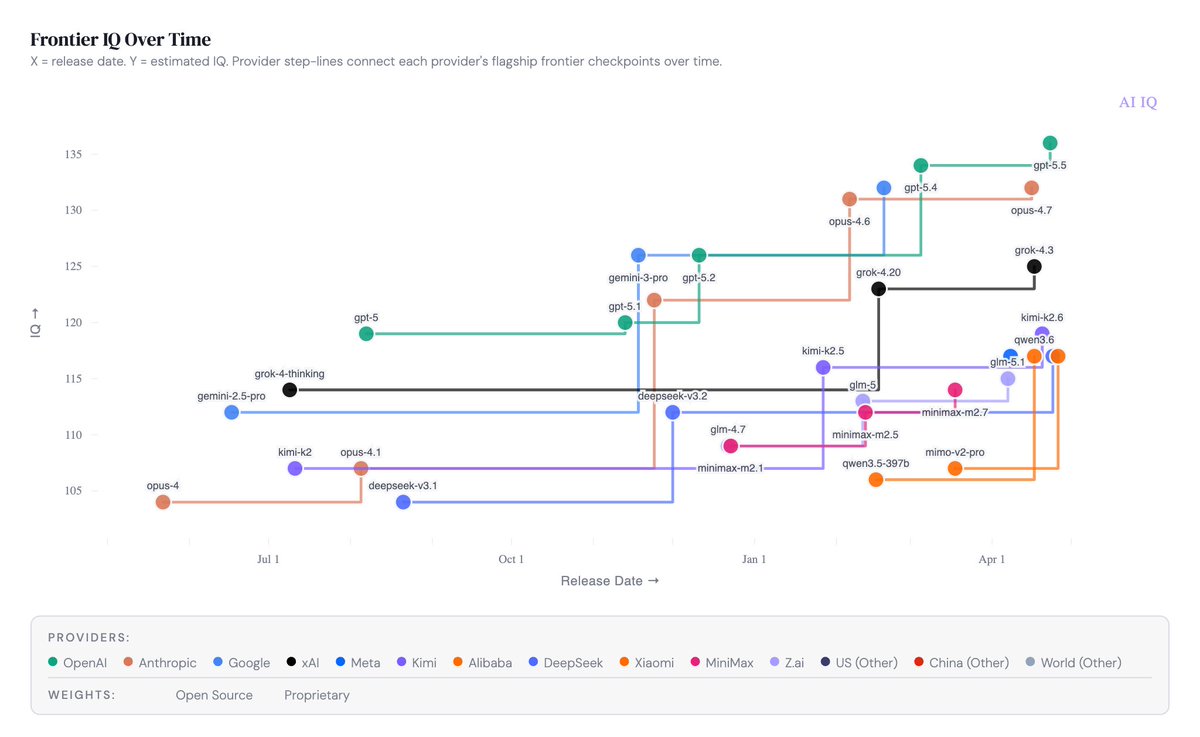
Today I’m launching AI IQ — frontier AI models, scored on the human IQ scale.
Instead of endless leaderboard tables, AI IQ shows:
• Where models land on the IQ bell curve
• How frontier IQ is changing over time
• How models compare on IQ and EQ
• What intelligence costs in practice
GPT-5.5, Claude Opus 4.7, Gemini 3.1, Grok 4.3, Kimi K2.6, Qwen3.6, DeepSeek V4, Muse Spark, and more.
Link in the first reply. Curious which chart surprises you most.
I had a chance to interview @jack on Long Strange Trip and then sit in on his Q&A with a bunch of Sequoia founders yesterday. Here's my take followed by my takeaways.
Almost all of us are running a derivative of the playbook laid out in Andy Grove's "High Output Management" book that has been lightly edited down through the generations. Jack's set of ideas is a stark departure from that playbook. It reminds me of the shift I went through at the start of my career (pre web - yes, I'm that old!) to "digital transformation," but this is a much bigger, harder shift.
Some of my CEO friends have pushed back on these ideas saying something to the effect that Jack isn't a great CEO so we shouldn't listen to him. First, I'm not sure if that is true, but even if it is true, he is an undeniable innovator and first principles thinker applying that thinking here to org design, not just product design. Second, @brian_armstrong, a consensus great CEO is running something that sounds VERY similar to this playbook as well as almost every startup created in the last 18 months. Third, the first quarter Jack printed after putting this in place was a banger. ...To that end, I think we should all call this new playbook, "Dorsey Mode" after the guy who stuck his neck out.
If you want to run Dorsey Mode, a lot of things fall out of it that fall out of it:
1. Strategy - Planning cycles are out the window because the speed increases too much. All those 1 way doors you were procrastinating now look like 2 way doors.
2. Distribution - Given how much easier it is going to get to build products, competition and customer confusion will reign. In this new world, distribution is king. Companies with truly creative distribution strategies (rare!) will gain advantage. Also, long live ye olde enterprise sales.
3. Interviewing - All of the startups I work with have changed their interviewing process. Many have a case with a hard ai problem to solve embedded in it or at least have the prospective employee open their laptop and show them something interesting they built with ai. 4. Profile - There was a split in my group of CEOs at the Q&A -- some were learning hard into pilled jr engineers and some were leaning hard into very senior engineers. It roughly seems like the older companies with more code like Meta and HubSpot, are leaning harder into the very senior engineering types. ...Everyone seems keen to hire "curious" types not afraid to go very deep down rabbit holes.
5. Org shape - Triangle shaped org charts are like democracy, its the least bad system we've got. The biggest problem with triangles is that they get worse with size. The new org chart, in theory, is circular with the world model in the middle and very small teams surrounding it. Very few pure managers in the middle anymore. This seems "early," but directionally right to me.
6. Compensation - The difference between a middling employee and a top one is getting much wider which will necessitate a net new pay scale with a much higher standard deviation.
7. Titles - Jack got rid of them and is trying to focus everyone on the work as opposed to the level. As someone who tried this earlier in my career at HubSpot, I'm a little skeptical of this one, but the meta point of trying to focus people on what they "lead" versus who they "manage" is a good one that I hope sticks.
8 Decisions - Almost all decisions these days are made by carbon based life forms. Dorsey Mode turns an increasing amount of decisions over to the system.
9. IT - This is will totally change as their primary function will be to building the scaffolding for the world model and enable the company to keep feeding it the context and taste it will need to improve. EVERYTHING needs to be "legible" (I hate that I'm using that overused word, but it works) ...Btw, an early sign that a company is in Dorsey Mode is when they record every meeting, including the one on one's, cleverly stripping out some HR bits and centralizing them for use by the model. Btw, Ray Dalio had it right, but was just too early.
10. Slop - As more non-technical people build more things, there will be more slop. I didn't grok Jack's answer to this and I'm not sure the answer myself, but Dorsey Mode companies will need to figure out a system to reign in the badly designed systems.
11. Agency - This another word I cringe at using b/c it is so overused, but hiring folks with high agency that are self motivated will be key. The tricky part is that the beef with the current generation is that they are less like this than their predecessors.
12. CEO - This isn't something that will bubble up. The CEO needs to run hard at it and push it down hard and expect to get pushback from laggards. Jack spends 3 hours every morning building hard things with the new tools. ...AI isn't something that lends itself well to learning by reading or watching a video, so CEOs are running hackathons, show & tell's, building days, office hours, and token leader boards. ...Btw, lots of companies are doing the leader board thing (including mine) -- I think this works until it doesn't!
13. Budgets - Budgets in a lot of software orgs are basically enumerated in headcount. The denomination goes back to dollars.
As Jack (and my cofounder @Dharmesh) likes to say, in some cases, it is a lot riskier not to take a risk and this is one of those cases.
What’s happened is that we went from AI chat tools that were relatively cheap and had small context windows, to AI agents that have giant context windows, the ability to keep track of longer running work, and models that cost an order of magnitude more on inference because they’re that much better.
This has compounded far faster than most realized (unless you were paying close attention at the middle or end of last year, which many here were), and the dollars flowing in now are much more real.
What follows is a continued march of AI capability that will continue to be used by anyone with a frontier use-case (like coding, sciences, finance, consulting) and then a peeling off of tasks to lower cost models that are capable enough for the job. Whereas we thought the cost of AI might converge on a single low price per token before, it’s clear the stratification is only widening based on the task you need performed.
This will be yet another component that has to be figured out for broad AI diffusion. Enterprises will need to put in programs, new finance teams, and technology solutions to manage this all. The labs and platforms that can ensure customers can price optimize for the task at hand will be in the best position.
Week of May 18, 1776:
**Outside Montreal, the Continental Army's campaign in Quebec continues to unravel, but Arnold plans a counterattack.
**In Philadelphia, Jefferson moves into a new house on Market Street, where, in a mere 20 days, he will begin authoring the Declaration.
Central Park is great, but it takes up a lot of space and isn’t utilized to its full potential.
That’s why I worked with McKinsey on a plan to make it a state of the art data center, complemented by rooftop parking and nuclear power.
We can still build beautiful things.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.