this is Krea 2.
our first foundation model, built completely from scratch for aesthetic diversity and stylistic control.
learn more and get early access 👇
A breakthrough in real-time video generation.
As a research preview developed with @NVIDIA and shared at @NVIDIAGTC this week, we trained a new real-time video model running on Vera Rubin. HD videos generate instantly, with time-to-first-frame under 100ms. Unlocking an entirely new creative paradigm and bolstering the foundations of our General World Model, GWM-1.
Real-time generation opens a fundamentally different design space for video models and world simulation. We're investing in co-designing our models alongside advances in hardware to keep pushing this frontier.
Introducing Image to Video for Gen-4.5, the world's best video model.
Built for longer stories. Precise camera control. Coherent narratives. And characters that stay consistent.
Gen-4.5 Image to Video is available now for all paid plans.
Meta's ex Chief AI officer is raising €500n at a €3bn valuation for his startup before it's even launched.
Yann LeCun (@ylecun) will be launching his new venture, Advanced Machine Intelligence Labs, in January and he will serve as an executive chair.
The fundraising is in early stages and could change.
According to the FT the startup:
"will focus on creating a new generation of superintelligent AI systems by building so-called world models, which are able to understand the physical world and have a wide range of applications, such as robotics and transport"
Bubble - what bubble?
A short statement on our mission ahead: to train generalist models directly on observations from the universe, in what we believe will be the most important (and fun) technological quest of our time.
Universal World Simulator
Soon, everyone will have access to their own world simulator. This will be the most important technological development of our time.
Video models trained at sufficient scale become world models. To predict the next frame, a video model must learn how the world works. How objects move, how forces propagate, how actions cause effects. General world models are learned approximators of physics.
The hardest problems facing humanity are rooted in physical reality. Robotics, medicine, climate, materials, energy. Language models will not get us there. Text distills existing human knowledge. In order to move beyond that, we need to learn directly from raw observations of the world.
Universal simulation is fundamentally about access. Experiences limited by geography and cost will become available to anyone. Running experiments today requires equipment, funding, and institutional access. With world simulators, the tools of discovery stop being scarce. Small teams will be able to develop autonomous systems and test policies across millions of scenarios without physical infrastructure. A student anywhere in the world will have her own biology lab and her own particle accelerator.
Progress will not happen overnight, but it will happen faster than people expect. We anticipate half a decade before we achieve human-scale world simulation: interactive simulations indistinguishable from the real world. Within a decade, we expect to simulate physics and biology accurately enough to solve a significant percentage of today's scientific challenges.
At Runway, we choose to invest in this long-term research vision rather than short-term optimization. At the same time, we will be deploying world models incrementally: this is how the world comes to understand what they are capable of, and how we learn to build them responsibly.
Science is about understanding reality. Art is about transcending it. These are two expressions of the same capability, which is why we need to advance them together. Runway will always operate at their intersection.
AAC
Anastasis, Alejandro, Cris
Speedrunning ImageNet Diffusion - 360x faster training
There have been many new techniques demonstrating convergence speedups compared to DiT in the past few years, however all of these have been studied in isolation, against increasingly outdated baselines.
I present SR-DiT (SpeedrunDiT), which combines some of the best techniques into one new modern baseline
So thrilled to share our latest research work for the GWM-Worlds simulation model at Runway Research Demo Day 2025!
This is one of the most fun and challenging projects I’ve ever worked on, and I’m so humbled to be part of the team bringing these immersive, interactive experiences to life!
There’s still a lot ahead, yet the future is arriving faster we expected!
Welcome to Research Demo Day 2025. We're sharing a number of exciting announcements towards our mission to build AI systems that simulate the world. https://t.co/8PYXOk8bG2
With Gen-4.5 you can explore worlds that represent very specific points of view and aesthetic characteristics. The model allows you to precisely generate the look, feel and atmosphere of the world you want to create and the stories you want to tell.
Gen-4.5 offers an unprecedented level of visual fidelity and artistic range. Without the need for complex prompting the model can accurately light your scenes to achieve your desired mood and story with realistic light and shadow. Whether you're looking for clean studio set ups or tense cinematic tableaus, Gen-4.5 can light your generations accordingly.
Whisper Thunder is out. New state of the art for video: Runway Gen-4.5.
What an incredible journey. It took so much hard work and care from the most talented team to build something truly special. A small team accomplished what everyone thought was impossible.
You will really enjoy using this model. It feels different from the start and is unique in so many ways. I've been using it nonstop for days.
I'm so excited for everyone to try it out. Oh, and there are more fun surprises ahead!
Introducing our new frontier video model, Runway Gen-4.5. Previously known as Whisper Thunder (aka) David.
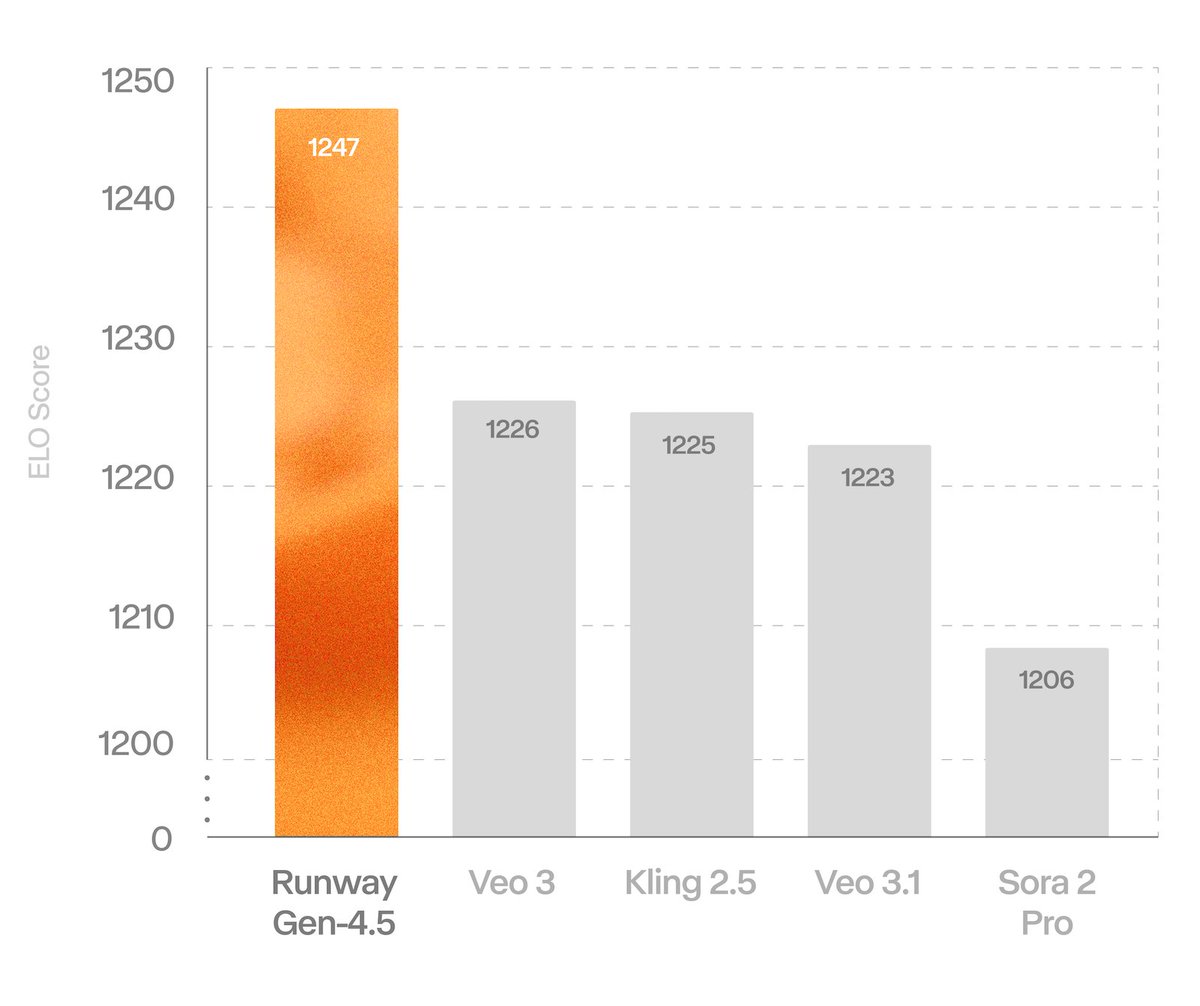
Gen-4.5 is state-of-the-art and sets a new standard for video generation motion quality, prompt adherence and visual fidelity.
Learn more below.
Introducing Terminal Velocity Matching: a scalable, single-stage generative training method that delivers diffusion-level quality with a 25× fewer inference steps, now trained at 10B+ scale.
https://t.co/gFBPorSBEw