Intelligence should be open, accessible, and ready to build with, empowering every developer, everywhere.
GLM-5.2 is now available to all GLM Coding Plan users, including Lite, Pro, Max, and Team plans.
https://t.co/AedZACyzej
As our new flagship model, GLM-5.2 delivers powerful coding capabilities, usable 1M-context support, and continued strengths in long-horizon tasks.
API and Chatbot services will launch next week. The model will also be officially open-sourced next week under the MIT License.
The future of AI is open, and it belongs to the people.
ComfyUI just added @OpenRouter support.
Instead of being locked into a single LLM, you can now access 20+ models directly inside Comfy.
More flexibility, less friction, same workflow.
Links to the workflows below👇
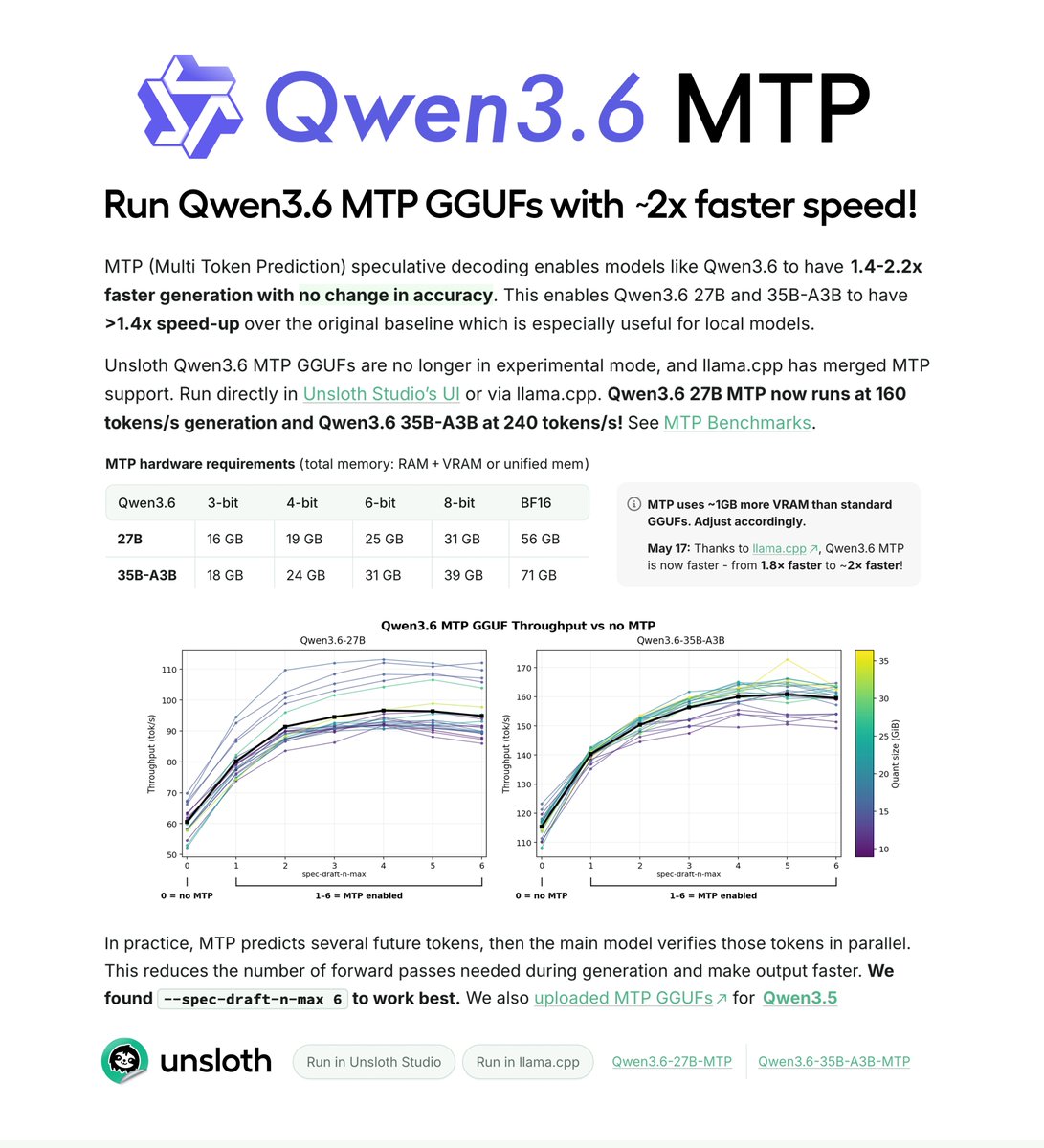
Qwen3.6 now runs 2x faster with MTP GGUFs! Run locally on just 18GB RAM. ⚡️
MTP enables Qwen3.6 to generate ~1.4–2.2× faster with no accuracy change.
Qwen3.6-27B MTP runs at 160 tokens/s. 35B-A3B reaches 240 t/s.
GGUFs: https://t.co/7gWhKnseZo
Guide: https://t.co/7qzk6ypWDQ
GLM-5.1 from @Zai_org is now live on OrcaRouter
• #1 open-source model on SWE-Bench Pro
• Beats closed source models on real-world repo repair benchmarks
• MIT licensed
• 200K context
• Built for long-horizon agentic coding
We’ve also seen strong results using GLM-5.1 inside OrcaRouter’s adaptive routing strategy as a fallback coding model.
Open-source coding models are getting scary good. https://t.co/a0WruoaJSc
How to Convert Your ComfyUI Workflow into an APP Mode Workflow
App Mode is a new way to view and run any ComfyUI workflow.
When you enter App Mode, the node graph disappears and is replaced by a clean, purpose-built interface: just the inputs your user needs.
When your tool is open source and free, your creativity has no ceiling. The ComfyUI skill in @NousResearch Hermes Agent lets you compose sophisticated workflows by chatting to an agent. Try it today.
🔥DeepSeek Input Cache Price Drop!
Effective immediately, the price for input cache hits across the ENTIRE DeepSeek API series is reduced to just 1/10th of the original price! Build more efficiently for less.
📌Reminder: The DeepSeek-V4-Pro 75% OFF promotion is still active until May 5th, 2026, 15:59 (UTC Time).
Comfy exists because our community builds, teaches, experiments, and shares. In that same spirit, we're launching the Comfy Affiliate program.
If you’re making tutorials, workflows, videos, threads, templates, or just showing how you use Comfy in the wild, we want to support you and amplify your work.
Learn more and apply here: https://t.co/D1x65HBzfM
Finally, Python 3.14 lets you disable GIL!
It's a big deal because earlier, even if you wrote multi-threaded code, Python could only run one thread at a time, giving no performance benefit.
But now, it can run your multi-threaded code in parallel.
And uv fully supports it!
You can now run 70B LLMs on a 4GB GPU.
AirLLM just killed the "you need expensive hardware" excuse.
It runs 70B models on 4GB VRAM.
It loads models one layer at a time, runs 405B Llama 3.1 on 8GB VRAM.
→ No quantization needed by default
→ Run Llama, Qwen, Mistral, Mixtral locally
→ Works on Linux, Windows, and macOS
100% Opensource.