AI needs vastly more data than we do. One idea might close the gap: don't predict raw signals (tokens), predict your own abstract latent representation (JEPA, data2vec).
With @DanKorchinski@MatthieuWyart, on a toy model, we prove how much that helps: the gap is exponential.
🧵
The lesson: on a fundamental level, solutions to these games are low-dimensional. No matter how hard you hit them with from-scratch training, tiny models will work about as well as big ones. Why? Because there's just not that many bits to learn.
Yann LeCun (AMI Labs Founder): "The AI industry is completely LLM-pilled. Everybody is working on the same thing. They're all digging the same trench."
LeCun explains why no lab dares break from the pack:
"They are stealing each other's engineers. So they can't afford to do something different because if they start going on a tangent, they're going to fall behind the other guys. And so they're all doing the same thing."
This groupthink is exactly what drove him out of Meta.
"Meta also became LLM-pilled with sort of recent reshuffling. And it's fine, a strategic decision that maybe makes sense for them. It's just not what I'm interested in."
For @ylecun, the problem runs deeper than strategy.
LLMs are missing something essential about how intelligence actually works:
"I cannot imagine that we can build agentic systems without those systems having an ability to predict in advance what the consequences of their actions are going to be. The way we act in the world is that we can predict the consequences of our actions and that's what allows us to plan."
His broader critique is that the industry has mistaken fluency for intelligence.
Language turned out to be the easy part. The hard part is the physical world.
It's why we still don't have domestic robots or level-five self-driving cars, even though today's systems can pass the bar exam and write code.
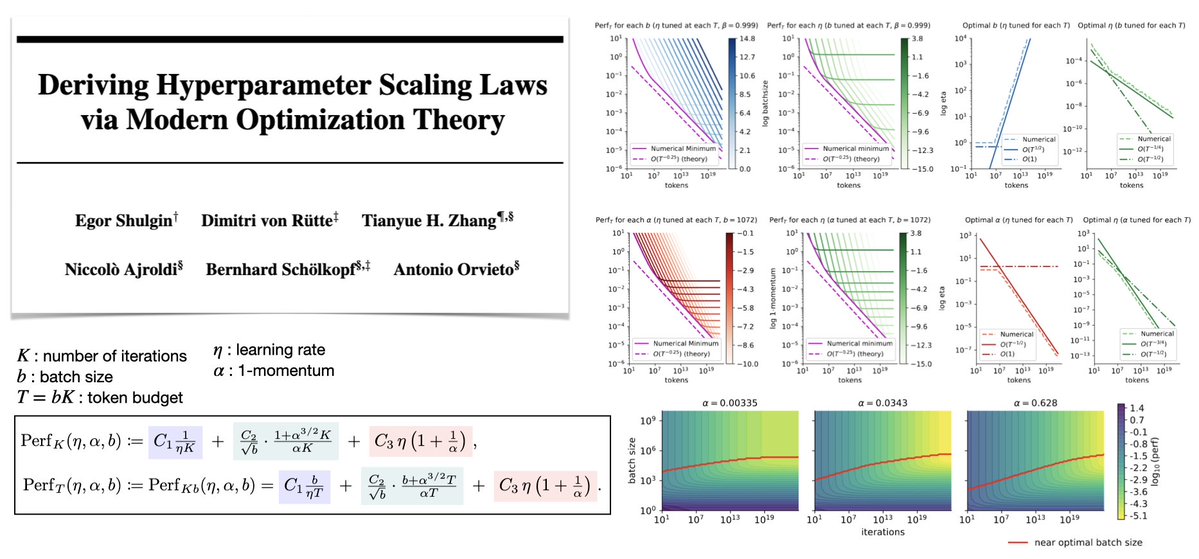
Optimization theory for adaptive methods actually predicts most of what we know about hyperparameter scaling in LLM pretraining, and suggests new strategies as well. We did a deep dive here.
Apple Research just published something really interesting about post-training of coding models.
You don't need a better teacher. You don't need a verifier. You don't need RL.
A model can just… train on its own outputs. And get dramatically better.
Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it.
Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. +30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%.
Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels.
SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it.
The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table.
paper: https://t.co/YsT3OSmbq3
code: https://t.co/OX58FzDVqy
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
We are pleased to share that using Gauss, we have completed a ~200K LOC formalization of Maryna Viazovska’s 2022 Fields Medal theorems on optimal sphere packing in dimensions 8 and 24.
This is the only Fields Medal-winning result from this century to be completely formalized, and is the largest single-purpose Lean formalization in history.
We are honored to have assisted @SidharthHarihar1 and the rest of the sphere packing team in this achievement.
https://t.co/DhGDQzLkpH
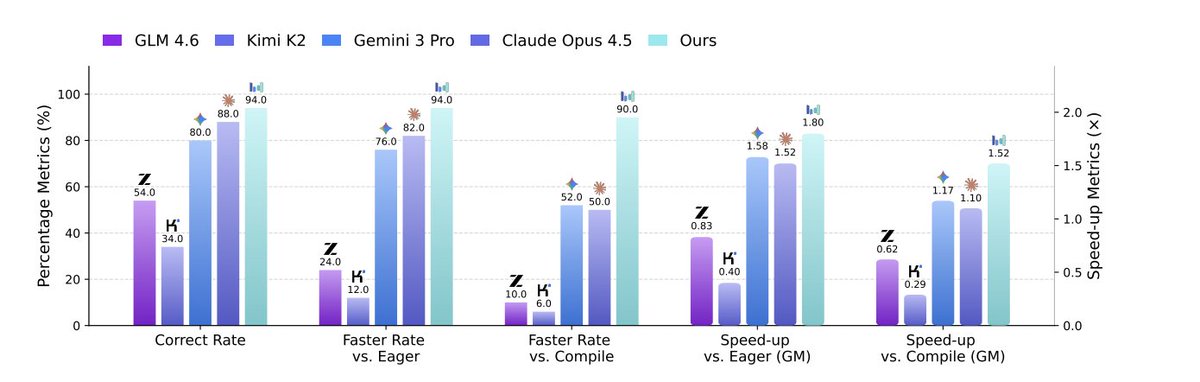
ByteDance just published something I've been waiting for someone to build: CUDA Agent!
It trained a model that writes fast CUDA kernels. Not just correct ones — actually optimized ones.
It beats torch.compile by 2× on simple/medium kernels, ~92% on complex ones, and even outperforms Claude Opus 4.5 and Gemini 3 Pro by ~40% on the hardest setting.
The key idea is simple but kind of brilliant:
CUDA performance isn’t about correctness, it’s about hardware. Warps, memory bandwidth, bank conflicts — the stuff you only see in a profiler.
So instead of rewarding “did it compile?”, they reward actual GPU speed. Real profiling numbers. RL trained directly on performance.
That’s a big shift.
Paper: https://t.co/EYx7QKosgk
Project: https://t.co/pTCfzQIBes
What if all AI models share a hidden, low-dimensional "brain"?
Johns Hopkins University reveals that neural networks, regardless of task or domain, converge to remarkably similar internal structures.
Their analysis of 1,100+ models (Mistral, ViT, LLaMA) shows they all use a few key "spectral directions" to store information.
This universal structure outperforms assumptions of randomness, offering a blueprint for more efficient multi-task learning, model merging, and drastically cutting AI's computational and environmental costs.
The Universal Weight Subspace Hypothesis
Paper: https://t.co/hLcByUvaPZ
Page: https://t.co/yaGc26dZnR
Our report: https://t.co/jnoqPLOgiO
This seems like a pretty big deal to me. OpenAI's circuit-sparsity release potentially entails that MoEs are a dead end.
We've been isolating weights into "experts" as a crude approximation of sparsity just to appease dense matrix kernels. It fragments the manifold.
The real target is inherent sparsity: projecting into massive nominal dimensions (d \gg d_{model}) with strict k-sparse activation. This forces features to be monosemantic and orthogonal by design, solving superposition natively rather than relying on router hacks to disentangle interference.
It appears that we aren't just scaling parameters anymore, we're scaling the basis!
A reset button for rotation could change how we control them all.
Is it possible to cancel out a complicated spin without painstakingly reversing every single move? Surprisingly, the answer is yes.
Mathematicians Jean-Pierre Eckmann (University of Geneva) and Tsvi Tlusty (UNIST, South Korea) recently proved that almost any object—whether it’s a spinning top, a tumbling satellite, a twisted protein, or even a scrambled Rubik’s Cube—has a hidden “reset button” for its orientation.
Instead of undoing the motion step by step in reverse order, you can take the entire original sequence of rotations, scale it by a certain constant factor (make every turn bigger or smaller by the same proportion), perform that scaled version once, then do it again—and the object snaps perfectly back to its starting orientation. Two scaled copies of the same motion are enough to erase it completely.
It feels deeply counterintuitive. We’re used to thinking that rotations in 3D space don’t commute and that the only safe way to return home is to retrace your path exactly backward. Yet this new result reveals a previously unknown geometric symmetry: certain scaling factors turn the rotation group into something that has a kind of built-in “double and cancel” feature.
The discovery applies to any rigid body moving in three dimensions and may simplify algorithms in robotics (for reorienting a robot arm without tracking every prior move), computer graphics, molecular dynamics simulations, spacecraft attitude control, and even some problems in quantum mechanics.
In short, nature has been hiding a remarkably simple trick: sometimes the fastest way to undo a complex dance of spins isn’t to moonwalk backward through every step; it’s to perform an enlarged (or shrunken) version of the same dance twice.
["Walks in Rotation Spaces Return Home when Doubled and Scaled." Physical Review Letters, 2025]
This paper from Tsinghua University and Shanghai Jiao Tong University received perfect scores (6, 6, 6, 6) at NeurIPS 2025!
It aims to answer a key question: Does reinforcement learning really make large language models better reasoners?
The authors study Reinforcement Learning with Verifiable Rewards (RLVR) and find that while it improves accuracy for small k, it doesn’t create new reasoning patterns—meaning the base model still determines the upper limit of reasoning ability.
Across six RLVR variants, performance gains plateau, suggesting that current RL setups mainly refine reasoning rather than reinvent it.
Interestingly, it’s distillation, not RL, that shows genuine signs of emergent reasoning.
This research points to the next frontier for truly self-improving large language models.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Paper: https://t.co/jOvAn6eGIZ
Page: https://t.co/o951L62oR6
Our report: https://t.co/nnMLg0FC5p
📬 #PapersAccepted by Jiqizhixin
Thrilled to share our new #NeurIPS2025 paper done at @GoogleDeepMind, Plasticity as the Mirror of Empowerment
We prove every agent faces a trade-off between its capacity to adapt (plasticity) and its capacity to steer (empowerment)
Paper: https://t.co/prWpkdPojb
🧵🧵🧵👇
""70, 80, 90% of the code written in Anthropic is written by Claude. (...) "I said something like this 3 or 6 months ago, people think of it as falsified because they think of it as like we're going to fire 70 80 or 90% of the software engineers but what really happens is that the 10% were still writing, you know, humans become managers of AI systems."




























![Rainmaker1973's tweet photo. A reset button for rotation could change how we control them all.
Is it possible to cancel out a complicated spin without painstakingly reversing every single move? Surprisingly, the answer is yes.
Mathematicians Jean-Pierre Eckmann (University of Geneva) and Tsvi Tlusty (UNIST, South Korea) recently proved that almost any object—whether it’s a spinning top, a tumbling satellite, a twisted protein, or even a scrambled Rubik’s Cube—has a hidden “reset button” for its orientation.
Instead of undoing the motion step by step in reverse order, you can take the entire original sequence of rotations, scale it by a certain constant factor (make every turn bigger or smaller by the same proportion), perform that scaled version once, then do it again—and the object snaps perfectly back to its starting orientation. Two scaled copies of the same motion are enough to erase it completely.
It feels deeply counterintuitive. We’re used to thinking that rotations in 3D space don’t commute and that the only safe way to return home is to retrace your path exactly backward. Yet this new result reveals a previously unknown geometric symmetry: certain scaling factors turn the rotation group into something that has a kind of built-in “double and cancel” feature.
The discovery applies to any rigid body moving in three dimensions and may simplify algorithms in robotics (for reorienting a robot arm without tracking every prior move), computer graphics, molecular dynamics simulations, spacecraft attitude control, and even some problems in quantum mechanics.
In short, nature has been hiding a remarkably simple trick: sometimes the fastest way to undo a complex dance of spins isn’t to moonwalk backward through every step; it’s to perform an enlarged (or shrunken) version of the same dance twice.
["Walks in Rotation Spaces Return Home when Doubled and Scaled." Physical Review Letters, 2025]](https://pbs.twimg.com/media/G7V5AsFXEAEFeMc.png)































