What Midjourney is:
- No investors, fully community-funded research lab
- Revenue from image generation product funds all R&D
- ~$100M in first 9 months, $200M by month 12, still growing
- 8 active projects: 4 hardware, 4 software
----2 hardware products coming to market soon (consumer-purchasable)
----2 are large-scale machines
DAVID HOLZ: Background and Philosophy
- Grew up in Florida, parents in medicine, dad had a dental office on a sailboat
- Physics and math background: drawn to the tension between predicting reality vs. absolute truth
- Core thesis: the interaction between humans and technology is the biggest limitation, not compute power
- Founded Leap Motion at 22: $10M in pre-orders in 48 hours from a website (not Kickstarter)
- Built hand-tracking VR: 600M-parameter mixture-of-experts model, 2015, CPU cluster, pre-TensorFlow
- Also shipped Northstar, an open-source AR headset
- Left Leap Motion wanting a “home,” not a 100x return
- Mentor Bill Warner told him he could bootstrap; he listened this time
- Started Midjourney with ~$200K, called Google for 10,000 GPUs on trust alone
THE SCANNER: Full Body Ultrasonic CT
- First new whole-body medical imaging modality in ~50 years
- Concept: “as powerful as an MRI, as casual as a trip to the spa”
- No radiation, no magnets, no x-rays; safe for unlimited scans
How it works:
- 40 rings, each with 8,960 transducers (200 microns wide), totaling 358,000 elements
- Fires ultrasonic waves at 100M times/second; sound travels through water at 1,481 m/s
- Sensors resolve motion down to picometers (sub-atomic range)
- Captures 17 GB/second of raw data; 806 TB per full scan reconstruction
- 21 on-site servers, 2 petaflops of compute
- Patient lowers into water at 4 cm/second; ~60 seconds for several hundred body slices
- Produces sub-millimeter 3D maps of internal tissue
Already outperforming MRI in some tissue boundary and muscle fiber detail on DAY ONE.
10x cheaper and 60x faster than MRI machines; scan cost effectively near zero.
Gen 2 scanner planned by end of 2026; Gen 3 will use custom silicon.
SCANNER vs. MRI: Key Differences
- MRI: 60-minute tube, loud, requires sedation for children, expensive, radiation-adjacent.
- This scanner: water immersion, 30-60 seconds, no sedation, no radiation, repeatable daily.
- Current limitation: not yet FDA-cleared beyond body composition; no AI layer yet applied.
- Already better than MRI in certain muscle/fiber/vein boundary resolution at day one
THE MIDJOURNEY SPA:
- First location: Union Square, San Francisco
- 25,000 sq ft, 4 floors
- Amenities: hot tubs, saunas, cold plunges, European spa features, gym
- 9-10 full scanners on-site
- Goal: open by end of 2027
Target:
- 50,000 scanners globally, capable of 1 billion scans/month
- 5,000 spa locations needed at ~10 scanners each
- Estimated $20B capex to scale; Midjourney self-funds the first location
- Payback period modeled at ~6 months per location
ROADMAP & REGULATORY PATH:
- FDA discussions already started; body composition on a clear path
- Ascending approval ladder planned:Body composition (near-term, easy)
- Sharing data with physicians
- Doppler / blood flow imaging
- Pregnancy / fetal imaging (ultrasound already approved; this is a natural extension)
- Therapeutic applications (tendon/muscle healing, eventually incisionless surgery)
AI not yet applied to imaging; planned as a layer once data volume grows
LONG-TERM VISION:
- Flag anomalies automatically, substitute some blood tests, enable daily health tracking
PRICING:
- No firm numbers yet; likely spa memberships plus walk-in and scan-only tiers; cost of scan itself is near zero
- Data analysis: day one is body composition only; physician sharing gated on FDA progression
- Form factors: current design is throughput-optimized (up/down elevator); bathtub and gym-sized variants possible later
- Blood test substitution: sub-millimeter daily differentials with AI may eventually replace some tests; acknowledged as frontier science
- Cancer destruction via focused ultrasound: technically possible, not on near-term roadmap
NEXT STEPS:
- Sign up for Midjourney Medical email list for research trial scan invitations
- Visit https://t.co/mWHl3Bj5WC for jobs and updates (page now live)
Gen 2 scanner presentation planned before end of 2026
More secret projects to be announced soon.
Liftoff of Starship V3, from the dunes right outside the pad.
This is the most insane shockwave action I have ever seen on video. Absolutely mad.
📽️ Me for @WeAreSpaceScout
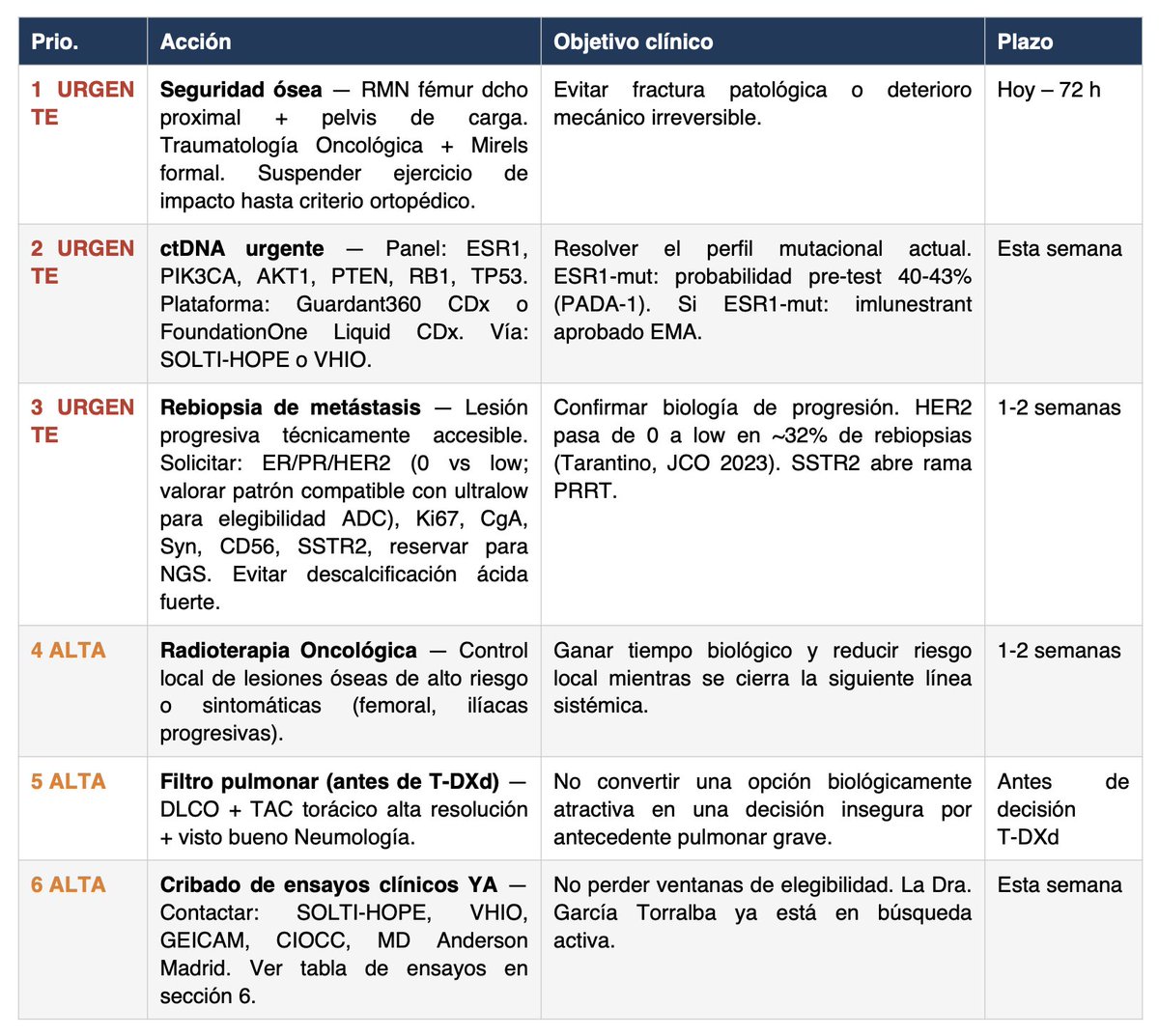
🔴 NECESITO TU ATENCIÓN
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: https://t.co/KEEWc8WNvW Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: https://t.co/CDSQ8HpZoc
Nuevamente la ciudadanía haciendo el trabajo que el Estado no hace. @paumrch ha hecho https://t.co/HoHKKvLVrN:
"Tu guía completa del IRPF 2025. Deducciones estatales y autonómicas explicadas de forma clara, con datos oficiales de la AEAT".