CLI tools are becoming agentic: developers define goals, and AI agents plan, use tools, iterate, request approval when needed, and execute tasks.
This #InfoQ article compares the planning approaches used by:
➢ Gemini CLI
➢ Claude Code
➢ Auto-GPT
🔗 https://t.co/vHMOTnPTlR
¡Esto es oro! 4 Cursos gratuitos de Ciberseguridad:
✓ Introducción y Fundamentos
✓ Seguridad de la red
✓ Ataques y defensa en la nube
✓ Centro de operaciones (SOC)
De la reputada firma PaloAlto Networks
→ https://t.co/9wpZSdxBP1
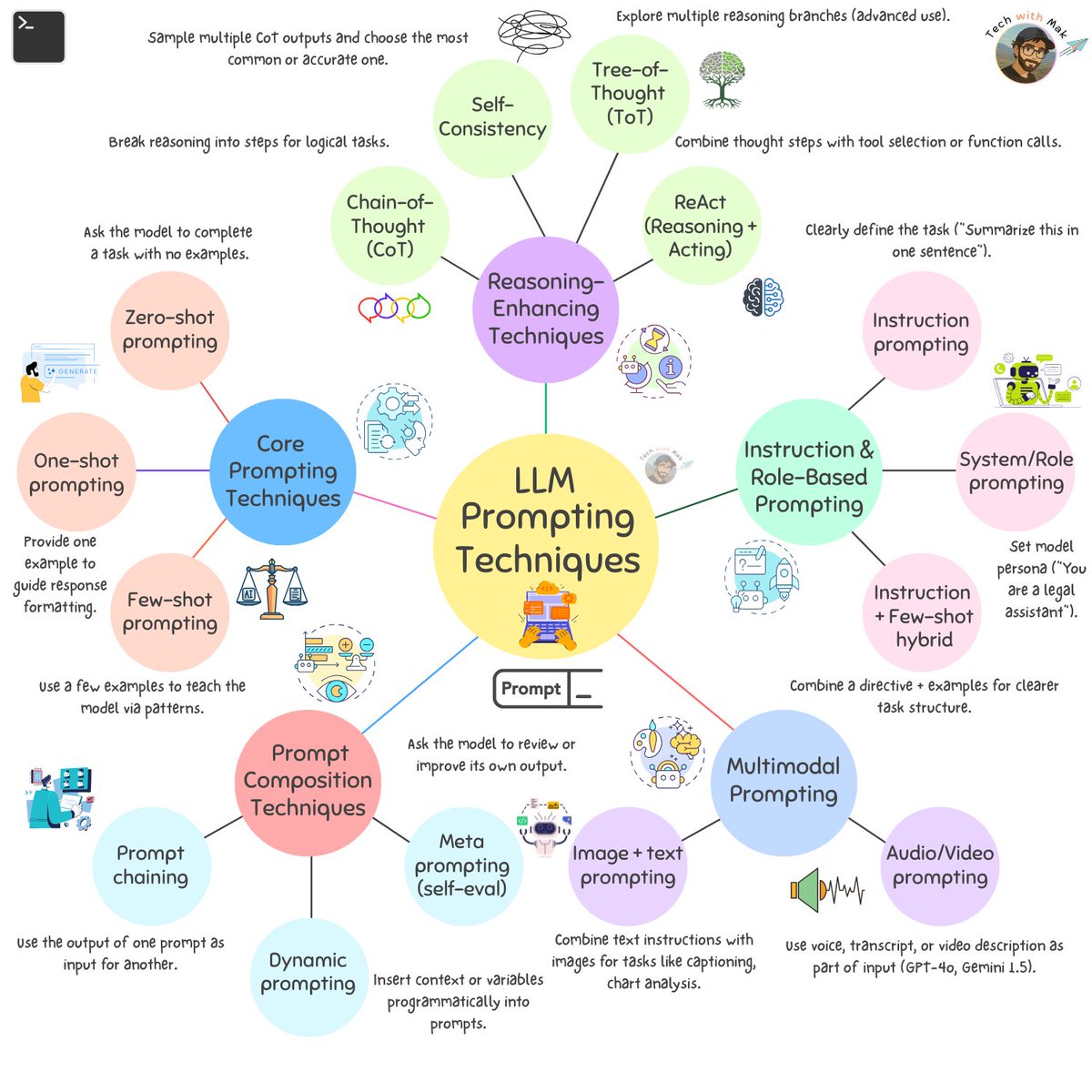
Prompting isn’t just asking the AI a question. It’s a deliberate, engineered input design process, and a critical skill when working with Large Language Models (LLMs).
Let's breakdown the prompting techniques.
✅ 1. Core Prompting Techniques
▪ Zero-shot - No examples provided. Just the task.
▪ One-shot - One example shown before the task.
▪ Few-shot - A handful of examples used to teach patterns.
🧠 2. Reasoning-Enhancing Techniques
▪ Chain-of-Thought (CoT) - Encourage step-by-step reasoning.
▪ Self-Consistency - Sample multiple CoTs; choose the best.
▪ Tree-of-Thought (ToT) - Explore multiple reasoning paths (advanced).
▪ ReAct - Combine reasoning steps with action/tool use (e.g., API calls).
🧾 3. Instruction and Role-Based Prompting
▪ Instruction prompting - Clear directives (“Summarize this…”).
▪ System / Role prompting - Define persona or behavior (“You are a legal assistant”).
▪ Hybrid (Instruction + Examples) - Combine clarity with few-shot grounding.
⚙️ 4. Prompt Composition Techniques
▪ Prompt chaining - Use one prompt’s output in the next.
▪ Dynamic prompting - Inject real-time variables or context.
▪ Meta prompting - Ask the model to improve or verify its own response.
🖼️ 5. Multimodal Prompting
▪ Image + text - Provide both visual and textual context.
▪ Audio/Video + text - Use transcripts or sensory input (model-dependent, e.g., GPT-4o, Gemini 1.5).
🧑⚕️ 6. Domain-Specific Prompting
▪ Code prompting - Constrained, tool-specific inputs (e.g., Python, SQL).
▪ Medical / Legal prompting - High-precision language with strict format and accuracy needs.
🧪 7. Prompt Evaluation & Debugging
(Not prompting techniques, but crucial tools.)
▪ Prompt ablation - Remove elements to test contribution.
▪ Injection testing - Evaluate prompt robustness in apps or agents.
❌ What’s Not a Prompting Technique
▪ RAG: A retrieval + generation architecture. Prompts are used inside it.
▪ Agents / Tool-use systems - Orchestration frameworks (e.g., LangGraph, AutoGPT). Prompting is one component, not the technique itself.
🔧 Prompting is no longer “just prompt engineering.” It’s system design.
If you're working with LLMs, know these cold.
Follow @techNmak for your daily dose of learning.
𝗛𝗼𝘄 𝘁𝗼 𝗗𝗲𝘀𝗶𝗴𝗻 𝗮 𝗣𝗮𝘆𝗺𝗲𝗻𝘁 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 𝗦𝘆𝘀𝘁𝗲𝗺 (𝗦𝘁𝗿𝗶𝗽𝗲)
Design a 𝗵𝗶𝗴𝗵𝗹𝘆 𝘀𝗲𝗰𝘂𝗿𝗲, 𝗿𝗲𝗹𝗶𝗮𝗯𝗹𝗲, 𝗮𝗻𝗱 𝗿𝗲𝗴𝘂𝗹𝗮𝘁𝗲𝗱 𝘀𝘆𝘀𝘁𝗲𝗺 that can authorize, process, and settle financial transactions between merchants, customers, banks, and card networks with strong consistency, fraud detection, and near-perfect uptime.
The system operates on a 𝗱𝗲𝗰𝗼𝘂𝗽𝗹𝗲𝗱, 𝗲𝘃𝗲𝗻𝘁-𝗱𝗿𝗶𝘃𝗲𝗻 𝗺𝗶𝗰𝗿𝗼𝘀𝗲𝗿𝘃𝗶𝗰𝗲𝘀 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲. Core flows,payment intents, card tokenization, fraud scoring, bank settlement,are handled by isolated services. This allows each part to scale independently and contain failures, crucial for financial systems.
When a customer submits payment, the flow is split into two critical phases orchestrated by a Payment Orchestrator. First, the 𝗔𝘂𝘁𝗵𝗼𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 phase: the system tokenizes sensitive card data, routes the request to the correct bank or card network via a Payment Gateway, and reserves funds. Second, the 𝗖𝗮𝗽𝘁𝘂𝗿𝗲 & 𝗦𝗲𝘁𝘁𝗹𝗲𝗺𝗲𝗻𝘁 phase (which can be hours or days later): the merchant finalizes the charge, funds are moved, and records are reconciled across all parties.
The platform's core consists of 𝗵𝗶𝗴𝗵𝗹𝘆 𝘀𝗽𝗲𝗰𝗶𝗮𝗹𝗶𝘇𝗲𝗱 𝘀𝗲𝗿𝘃𝗶𝗰𝗲𝘀:
. Payment Orchestrator: Manages the state machine of a transaction from start to finish.
. Vault Service: Securely stores and tokenizes sensitive payment data (PCI-DSS compliant).
. Fraud Engine: Scores transactions in real-time using machine learning rules.
. Routing & Gateway Service: Intelligently routes payments to acquiring banks & networks for optimal success rates and cost.
. Payouts & Reconciliation Service: Manages batched transfers to merchant bank accounts and matches internal records with bank settlements.
Behind the scenes, a 𝗱𝘂𝗮𝗹-𝘄𝗿𝗶𝘁𝗲, 𝗮𝘂𝗱𝗶𝘁-𝗿𝗲𝗮𝗱𝘆 𝗱𝗮𝘁𝗮 𝗽𝗮𝘁𝘁𝗲𝗿𝗻 is essential. Every state change in a transaction is written as an immutable event to a ledger (like Apache Kafka). This event stream is the source of truth for idempotent retries, audit logs, real-time analytics, and triggering downstream processes like invoicing or reporting.
This domain demands 𝗳𝗼𝗿𝘁𝗿𝗲𝘀𝘀-𝗹𝗲𝘃𝗲𝗹 𝘀𝗲𝗰𝘂𝗿𝗶𝘁𝘆. All services are hardened, communication is encrypted (TLS), and access is controlled via strict IAM policies. A Idempotency Service ensures that retried API calls due to network timeouts don't result in duplicate charges.
𝗖𝗿𝗶𝘁𝗶𝗰𝗮𝗹 𝗗𝗲𝘀𝗶𝗴𝗻 𝗣𝗿𝗶𝗻𝗰𝗶𝗽𝗹𝗲𝘀: 𝟭) 𝗦𝘁𝗿𝗼𝗻𝗴 𝗖𝗼𝗻𝘀𝗶𝘀𝘁𝗲𝗻𝗰𝘆 & 𝗔𝘁𝗼𝗺𝗶𝗰𝗶𝘁𝘆 for financial data, 𝟮) 𝗜𝗱𝗲𝗺𝗽𝗼𝘁𝗲𝗻𝗰𝘆 𝗯𝘆 𝗗𝗲𝘀𝗶𝗴𝗻 to prevent duplicate processing, 𝟯) 𝗜𝗺𝗺𝘂𝘁𝗮𝗯𝗹𝗲 𝗧𝗿𝗮𝗻𝘀𝗮𝗰𝘁𝗶𝗼𝗻 𝗟𝗲𝗱𝗴𝗲𝗿 for auditing, 𝟰) 𝗗𝗲𝗰𝗼𝘂𝗽𝗹𝗲𝗱 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 to isolate failures and ensure uptime.
𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲 𝗦𝘁𝗮𝗰𝗸:
. 𝗔𝗣𝗜 𝗟𝗮𝘆𝗲𝗿: REST, GraphQL, official client libraries
. 𝗕𝗮𝗰𝗸𝗲𝗻𝗱 𝗦𝗲𝗿𝘃𝗶𝗰𝗲𝘀: Ruby on Rails, Java, Go, Scala
. 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲𝘀: PostgreSQL (for transactions), distributed KV stores (for metadata)
. 𝗠𝗲𝘀𝘀𝗮𝗴𝗶𝗻𝗴 & 𝗦𝘁𝗿𝗲𝗮𝗺𝘀: Apache Kafka, RabbitMQ
. 𝗖𝗮𝗰𝗵𝗲: Redis, Memcached
. 𝗙𝗿𝗮𝘂𝗱 𝗗𝗲𝘁𝗲𝗰𝘁𝗶𝗼𝗻/𝗠𝗟: Python, TensorFlow, proprietary rule engines
. 𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲: AWS, Google Cloud, Kubernetes, Docker
. 𝗦𝗲𝗰𝘂𝗿𝗶𝘁𝘆: Hardware Security Modules (HSMs), PCI-DSS compliant vaults
👉 Learn more in the System Design Handbook: https://t.co/aE1KNO7yX5
👉 Grab the System Design Case Studies Handbook: https://t.co/hccIPge4WF
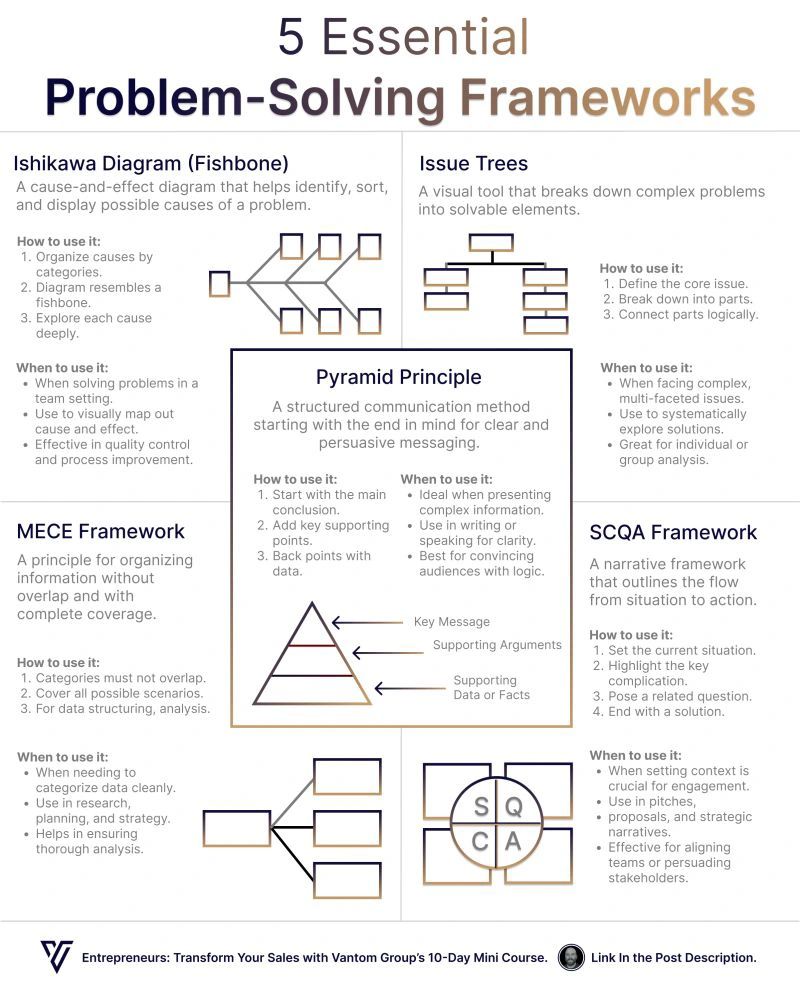
The easiest way to get ahead is to commit to a period of skill development. 6-12 months. Pure focus for 2-4 hours a day. Learning and building. Not just binge watching tutorials, but creating quality projects that you, others, or businesses could actually benefit from. But don't just let those projects sit around. Tell the world about them. See if people care enough to pay you. Fix what doesn't work until they do. That's it. That's what most people need to completely turn their life around.
Thinking of building AI agents?
Before you dive into tools like LangChain or AutoGen, master these essential skills first:
1. Python Programming Basics
Learn core concepts like variables, loops, and functions. Get comfortable writing scripts and using packages.
2. API & JSON Knowledge
Understand REST APIs, make requests using Python, and work with structured JSON outputs for data handling.
3. Prompt Engineering
Write clear prompts. Practice few-shot & role-based prompting. Know how to format system/user prompts properly.
4. Tool & Function Calling
Understand how LLMs select tools, define inputs, and call functions using frameworks like LangChain.
5. High-Level LLM Concepts
Know about tokens, context windows, memory limits, and sampling techniques like top-k or temperature.
6. Task Automation & Logic Building
Use https://t.co/AJQRix30HU or Zapier for workflows. Practice logical flow control using if-else, loops, and try-except.
7. Agent Framework Familiarity (Optional)
Explore LangChain, CrewAI, AutoGen. Learn agents, tools, and planning-based vs. reactive setups.
8. Iterative Debugging Mindset
Debug in small steps. Log outputs. Improve based on errors like prompt issues or tool mismatches.
Mastering these gives you a solid foundation for building real-world AI agents.
Save this list before jumping into agent workflows.
🚨 Google acaba de publicar un documento de 424 páginas sobre cómo diseñar sistemas de IA con agentes.
Cubre patrones reales de diseño, coordinación multi-agente y razonamiento, con código en cada capítulo.
Si estás construyendo con IA, esto te interesa 👇
Cuando se tratan de proyectos web pequeños, tengo muy claro qué herramientas usar. No porque sean “las mejores”, sino porque resuelven lo común rápido y sin fricción:
Next.js → frontend + backend en un solo proyecto
PostgreSQL → base de datos estable y fácil de alojar
Prisma → ORM para ir rápido sin escribir SQL desde el día uno
shadcn/ui → UI decente sin perder tiempo en CSS
React Hook Form + Zod → formularios y validaciones compartidas
DigitaloceanSpaces → Storage tipo S3, subida de archivos sin cargar la DB
Brevo → correos transaccionales sin montar SMTP
Better Auth → autenticación simple y moderna
@Railway → deploy rápido con CI/CD
Claude Code (IA) → acelerar, no pensar por mí
👉 Con esto puedes crear casi cualquier sistema común: ecommerce, dashboards, paneles administrativos, MVPs, herramientas internas…
⚠️ Aunque usando esto se hace fácilmente:
- APIs de WebSockets o GraphQL
Porque Next.js no es un framework de backend.
Es un framework de frontend que permite algo de backend para resolver lo común.
El resto ya no depende del stack, sino de la funcionalidad real, el diseño del sistema y qué tan bien entiendas el problema.
No todos los proyectos son grandes.
Y para cosas pequeñas, muchas veces solo se necesita poco… y esto es suficiente para empezar.
Video 👉 https://t.co/kX98aCCn7B
Muchos SaaS populares tienen alternativas Open Source (o más abiertas) que te permiten reducir costos y tener más control sobre tus datos.
Te comparto algunas equivalencias 👇
📝 Notion → AppFlowy / BookStack / Logseq
📊 Airtable → NocoDB / Baserow / Grist
🔥 Firebase → Supabase / Appwrite / PocketBase / Convex
🚀 Vercel / Heroku → Coolify / Dokku / CapRover / Dokploy
🧪 Postman → Hoppscotch / Bruno / Insomnia / HTTPie
💬 Slack → Mattermost
🎥 Zoom → Jitsi Meet
📋 Jira → Plane / OpenProject
🏢 Salesforce / ERP → ERPNext / Odoo
📧 Mailchimp → Mautic
📈 Google Analytics / Mixpanel → PostHog / Matomo
☁️ Dropbox → Nextcloud
📌 Trello → Wekan
✍️ DocuSign → Docuseal
No siempre son mejores que los SaaS comerciales,
pero sí ofrecen algo clave:
👉 privacidad, control y menos dependencia de suscripciones.
🎥 En este video explico cuándo vale la pena usar cada uno: https://t.co/Df7mvrkOaB
¿A cuál SaaS te gustaría dejar de pagar primero? 👇
Caching Implementation in Backend
→ Caching is the process of storing frequently accessed data in a fast storage layer to reduce latency and backend load.
→ It improves performance, scalability, and user experience in high-traffic backend systems.
✓ Why Caching is Important
→ Reduces repeated database queries
→ Improves API response time
→ Lowers server and database load
→ Enhances system scalability
✓ Common Caching Layers
→ Client-Side Cache → Browser cache, mobile app cache
→ CDN Cache → Caches static assets closer to users
→ Application Cache → In-memory caching inside backend services
→ Database Cache → Query result caching
✓ Popular Caching Technologies
→ Redis → In-memory data store, supports persistence and advanced data structures
→ Memcached → Simple, high-speed key-value caching
→ CDN Caches → Cloudflare, CloudFront for static content
✓ Caching Strategies
→ Cache-Aside (Lazy Loading)
✓ Application checks cache first
✓ On cache miss, fetches from database and stores in cache
→ Write-Through Cache
✓ Data written to cache and database at the same time
✓ Ensures consistency
→ Write-Behind (Write-Back) Cache
✓ Writes go to cache first
✓ Database updated asynchronously
→ Read-Through Cache
✓ Cache automatically loads data from database on a miss
✓ What to Cache
→ Frequently accessed data
→ Read-heavy queries
→ Configuration data
→ Session data
→ Computed or aggregated results
✓ Cache Invalidation Strategies
→ Time-Based Expiry (TTL)
→ Event-Based Invalidation
→ Manual Cache Clearing
→ Versioned Cache Keys
✓ Common Challenges
→ Stale data issues
→ Cache consistency
→ Cache stampede during high traffic
→ Memory limits
✓ Best Practices
→ Always define TTLs for cached data
→ Avoid caching highly volatile data
→ Use cache keys carefully
→ Monitor cache hit/miss ratios
→ Combine caching with database indexing
✓ Analogy
→ Cache is like keeping frequently used tools on your desk
→ Database is like a storage room
→ Faster access comes from keeping essentials nearby
→ Grab the Backend Development with Projects Ebook to master caching with Redis, Memcached, and real-world backend performance projects
https://t.co/QdeNEmpNfI
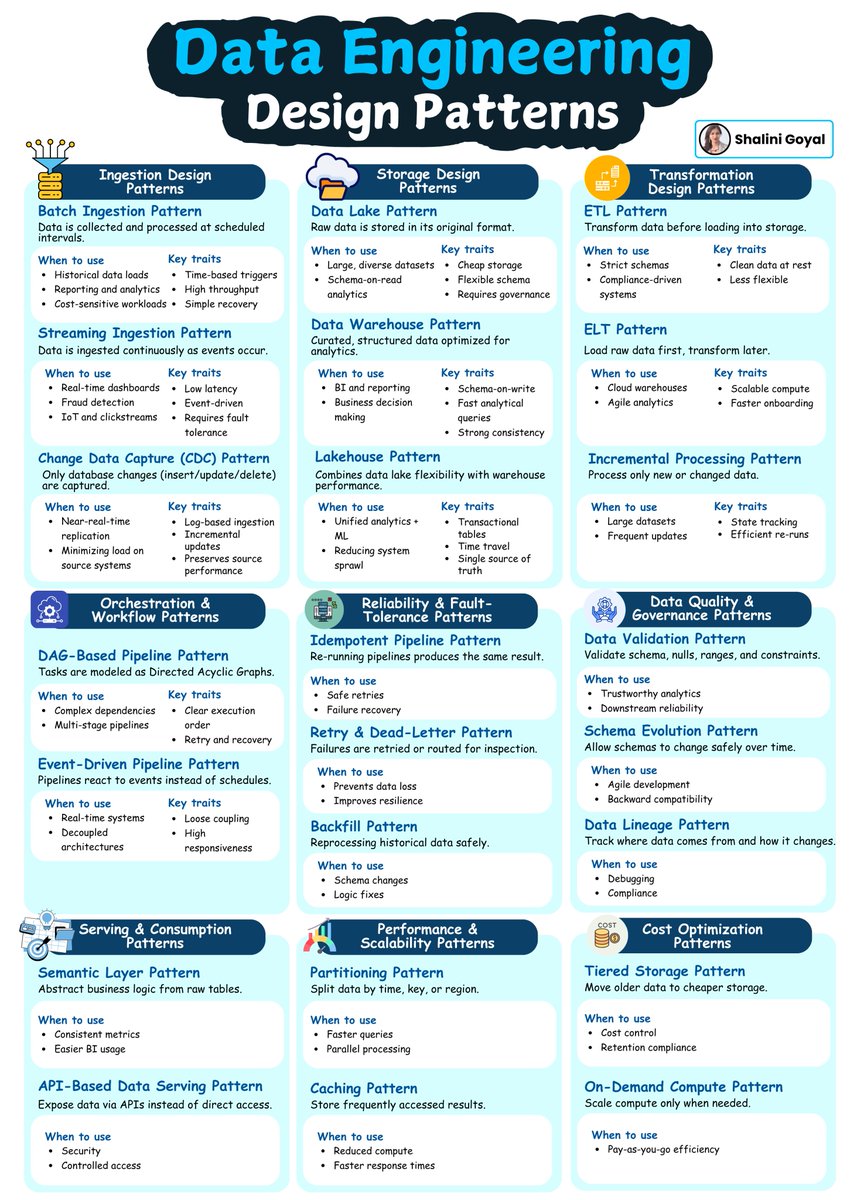
Modern data systems are not just built with tools - they’re built with design patterns that ensure reliability, scalability, and clarity as pipelines grow more complex.
Here’s the breakdown of the core Data Engineering Design Patterns every engineer should understand. Each pattern solves a specific challenge across ingestion, storage, transformation, orchestration, quality, and scalability.
Here’s a concise overview of the patterns:
1. Ingestion Design Patterns
Data enters systems in different ways depending on freshness and volume needs.
Batch ingestion handles scheduled loads, streaming ingestion captures real-time events, and CDC captures only row-level changes - ensuring efficient, timely, and fault-tolerant data collection.
2. Storage Design Patterns
Choosing the right storage model shapes everything downstream.
Data lakes keep raw, flexible data; data warehouses offer structured, analytics-ready storage; and lakehouses bridge both worlds by combining schema flexibility with high-performance querying.
3. Transformation Design Patterns
ETL and ELT define when and where transformations happen.
ETL transforms data before loading for strict governance, while ELT loads raw data first for faster, scalable cloud-based processing. Incremental processing focuses only on changed data to improve efficiency.
4. Orchestration & Workflow Patterns
Pipelines require coordination.
DAG-based workflows define execution order clearly, while event-driven patterns trigger pipelines based on system activity rather than schedules - improving responsiveness and decoupling systems.
5. Reliability & Fault-Tolerance Patterns
Failure is inevitable, so pipelines must be resilient.
Idempotent pipelines ensure repeated runs produce the same results, retry and dead-letter patterns detect or recover from failures, and backfill patterns safely reprocess historical data when needed.
6. Data Quality & Governance Patterns
Trustworthy pipelines depend on clean, governed data.
Validation enforces correctness, schema evolution handles safe structural changes, and lineage tracks how data flows - enabling debugging, compliance, and confident analytics.
7. Serving & Consumption Patterns
How data is exposed matters as much as how it's processed.
Semantic layers provide consistent business definitions, while API-based serving enables secure, controlled access for apps and downstream systems.
8. Performance & Scalability Patterns
Systems grow, and patterns keep them fast.
Partitioning improves query performance by slicing data, while caching accelerates repeated lookups and reduces compute cost.
9. Cost Optimization Patterns
Efficient systems balance performance with spend.
Tiered storage moves cold data to cheaper layers, and on-demand compute scales resources only when needed - reducing waste and controlling cost.
These patterns form the foundation of modern data platforms - helping engineers design pipelines that are scalable, reliable, and easy to evolve.
this repo teaches you how to build agents from scratch, step by step. it goes from fundamentals to advanced, all you need to master agents:
→ local LLMs and inference
→ LLMs through APIs
→ prompt engineering
→ GPU parallel processing
→ streaming and response control
→ function calling (tools)
→ persistent agentic memory
→ reasoning and ReACT
it includes 9 examples, each chapter building on top of the previous.
why is it important to learn how agents work from scratch? because the problem with frameworks is too many abstraction layers. when things go wrong (and they will) debugging them would be very hard, unless you really know what is going on under the hood.
this also means that you will be more expert in creating or customizing agents for your own needs.
all in all, i really suggest this one.
https://t.co/tfiAGz9oiR