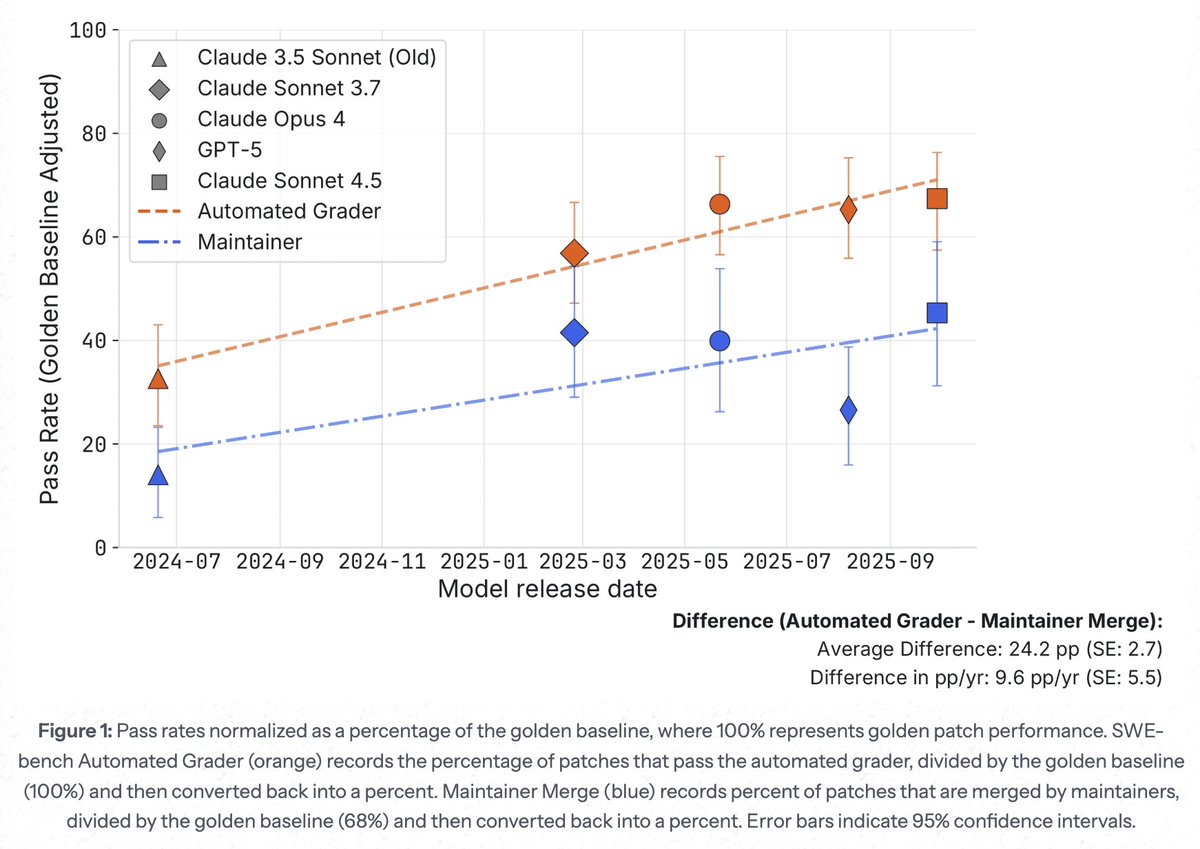
new @METR_Evals research note from @whitfill_parker, @cherylwoooo, nate rush, and me. (chiefly parker!)
we find that *half* of SWE-bench Verified solutions from Sonnet 3.5-to-4.5 generation AIs *which are graded as passing* are rejected by project maintainers.
People who want to get into AI safety should do more than just apply to fellowships. Applications are pretty random and might not reflect your actual abilities. Instead, be agentic! There are many paths to success that require only a bit more proactivity than applications. (1/4)
@andyw_ais Thank you @andyw_ais. This is the validation I needed and timely. I am currently working on extending 1 paper and was wondering if I was on the right path.
We will be seeing many more instances like this. Organizations need to calibrate their risks before letting AI into the driver seat. AI safety is here to stay
@Microsoft released two open source tools to help Agentic AI Engineers to build agents safely. This is huge and will shape the AI security and safety landscape for the next few months
The tools are called RAMPART and Clarity.
https://t.co/Ebn4gVgOqr
Bad actors can smuggle malicious instructions right at the point where the model's faithfulness starts to collapse. LLM-as-a-judge handles the evaluation.
Code is open source. Try it out. https://t.co/3yZK9WVsy8"
Built an AI safety related project. So it has been found that LLMs degrade as context windows expand. It has been shown empirically so it is not just theory.
I built a tool to find the exact breaking point where local LLMs start hallucinating. You can run it on your local machine
You can plug in your own models too.
Planning to expand it to more models and larger contexts when compute allows. There's also a red teaming angle here that I think is underexplored. As a model weakens at long contexts, that's a window for prompt injection attacks.
You have a point but not at the current rate or with the very low barrier to entry we have now. People are legit vibe coding their way into effective attacks. Mini shai hulud is now open source and there are even monetary incentives ($1000 Monero) for successful breaches
For those of you just now paying attention to cybersecurity, large companies got hacked before AI.
Colonial Pipeline, SolarWinds, OPM, Kaseya, Aramco, Change Healthcare, Equifax, Target, Home Depot, TJX, etc
@gozkybrain4u It was a supply chain attack. Same people behind most of the attacks since march. TeamPCP. They did Trivy, litellm, Mistral AI and Grafana. And GitHub most recently
I guess the era of Security by obscurity is fading or has faded away. The barrier to entry has been removed by AI and threat actors can even vibe code their way into breaching your critical systems. Now can we all give cybersecurity the deserved budgets and attention it needs?