I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
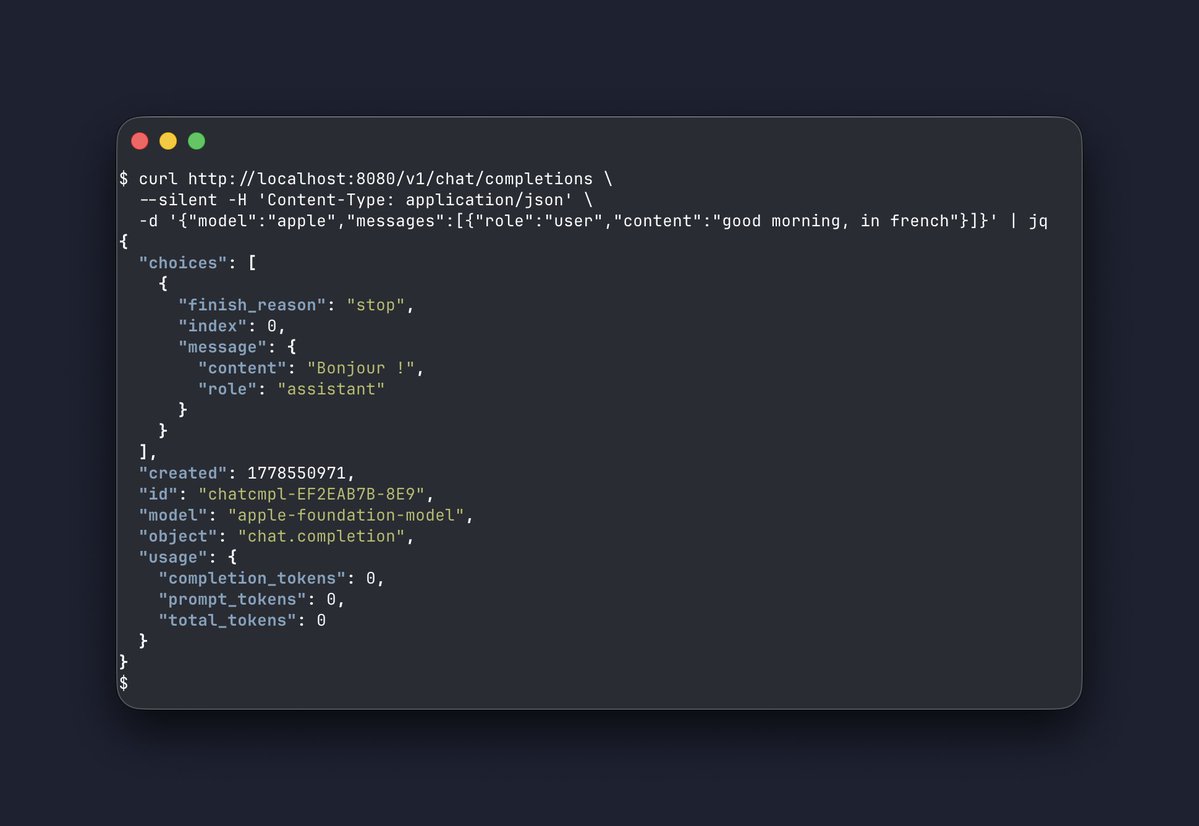
Modern macOS contains a fully local inference model. No network calls, stays fully on device.
Here's a single file script to turn it into an OpenAI API compatible completions server:
https://t.co/07ieY8ASKu
@shubhamJReacts@mattpocockuk I think you have it backwards. Markdown is interpreted pretty permissively, but HTML way more so.
HTML is probably the most permissively interpreted file format out there. Renderers and parsers will wade on no matter how malformed it is.
@techgirl1908 100% agree on "just give it more context" being unhelpful.
But I remain skeptical on automatically managed memories, until I see compelling results. I'm not ready to trust the quality of context being injected behind the scenes, at least when it comes to coding agents.
the funniest thing about the token grift is most folks who pushed token burn in q1 are now having a falling out with their CFOs because they don’t have a metric that correlates to business outcomes
Inputs -> outputs -> outcomes
If you can’t measure revenue, measure KPIs
If you cant measure KPIs, measure customer outcomes
If you cant measure customer outcomes, measure task throughput (features, tickets, bugs)
If you cant measure task throughput, measure work throughput (PRs)
If you cant measure PRs, measure LOC
If you cant measure LOC, measure tokens
if you’re a leader and you’re not focused on improving your ability to measure things that matter, you’re cooked
You cannot outsource the need for tasteful judgement.
There's times you don't need it - when a good-enough decision is fine - and in those situations you should be using an LLM every time.
But when thoughtful design decisions pay dividends, you still need an experienced human.
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
Doing some experiments today with Opus 4.6's 1M context window.
Trying to push coding sessions deep into what I would consider the 'dumb zone' of SOTA models: >100K tokens.
The drop-off in quality is really noticeable. Dumber decisions, worse code, worse instruction-following.
Don't treat 1M context window any differently.
It's still 100K of smart, and 900K of dumb.
slop creep is what happens when you turn your brain off and hand the thinking to coding agents
each individual change is fine, but all together, you have a pile of crap
we're witnessing this happen in real-time across everything
https://t.co/2hkDx8RAhE
I designed a simple little thing and printed it and use it in my home.
Some random people in other parts of the world needed the same thing too. They printed it, and now they use it in their homes.
That's nice.
https://t.co/0eSz99IreP
Being an Old, I have a bit of nostalgia for The Good Old Days of OSS where you shared a thing and maybe some people used it, and there wasn't any influencing or fancy websites or weird drama.
It's nice to rediscover that vibe in the 3D printing community...
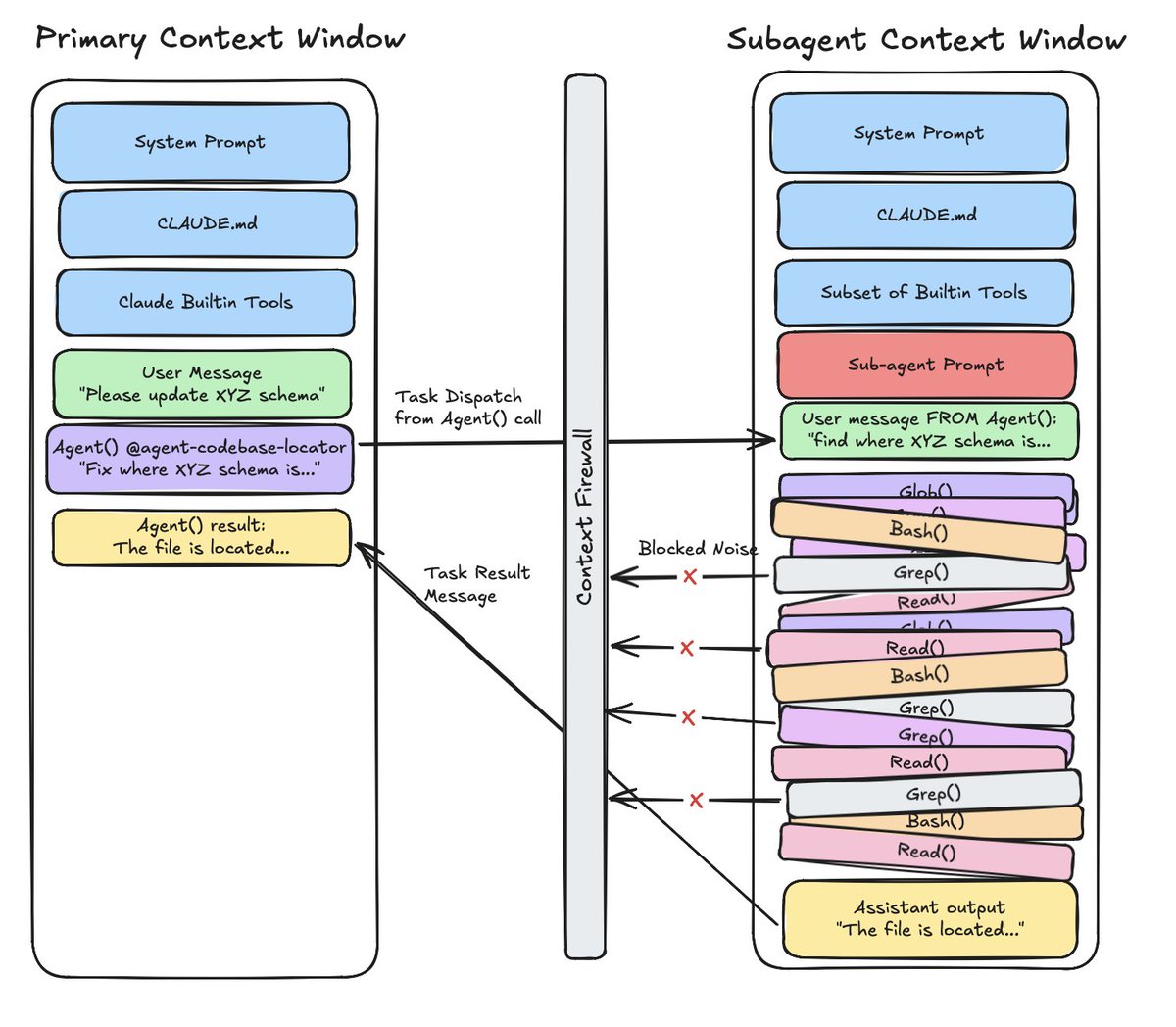
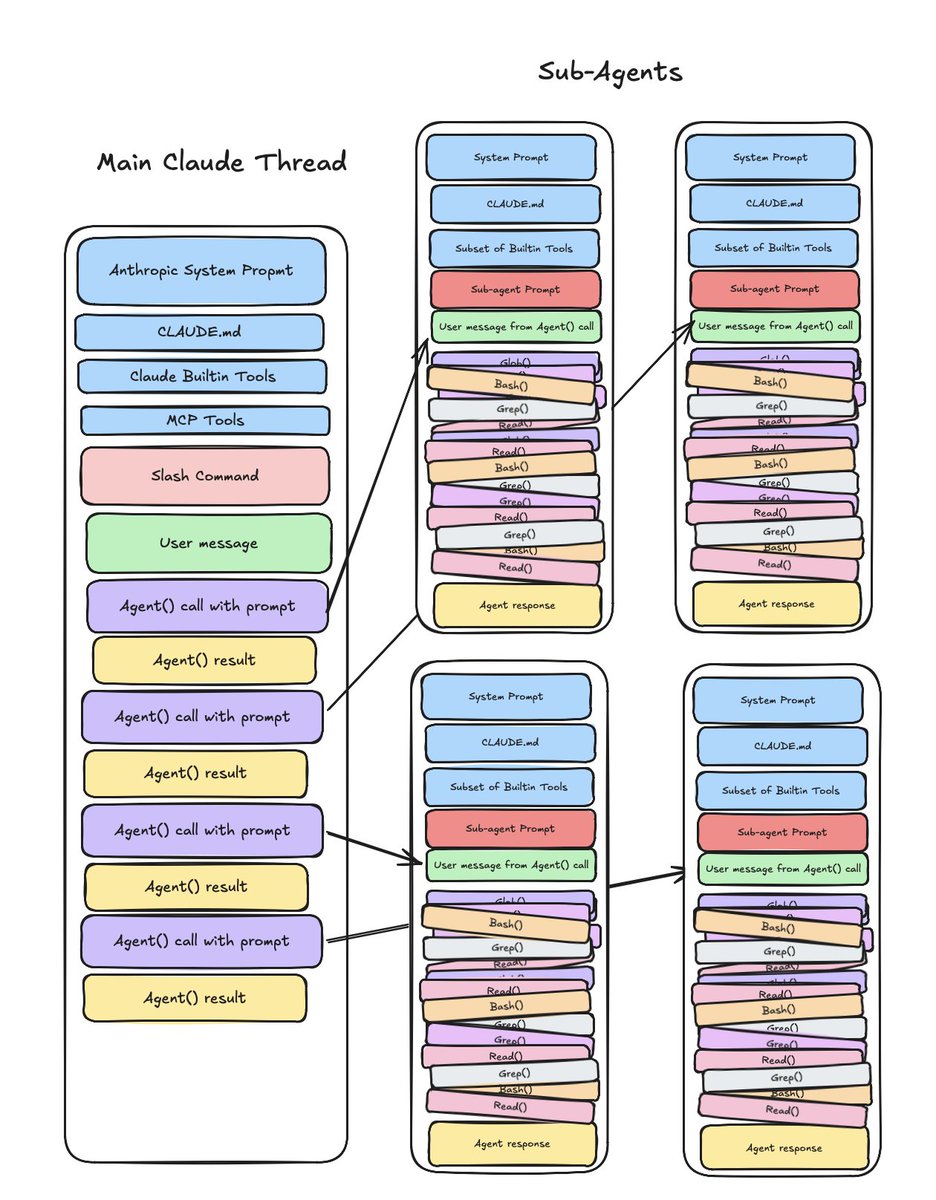
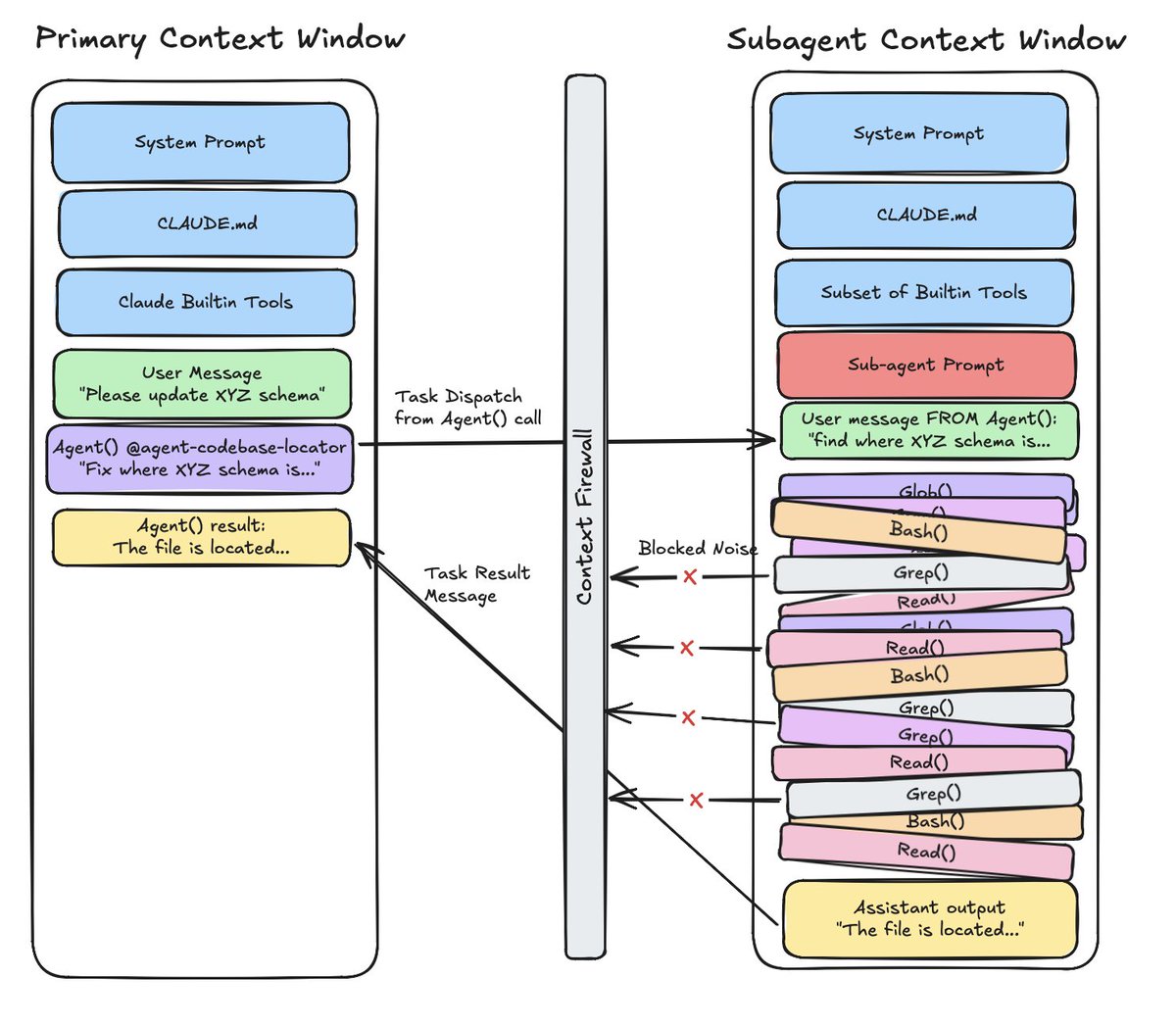
@0xblacklight Amazing write-up! Can I steal your subagent context window visualization for a presentation (w. credit!)?
Also FYI in "Distributing Tools with Skills" you say you can't package MCPs, scripts etc. in a skill. It's true, but Claude Code's plugins solve exactly for that.
Here’s what’s gonna happen:
- you replace your code review with feedback loops (sentry, datadog, support tickets, etc)
- you stop reading the code
- software factory fixes everything
- one day something breaks at 3am, agent can’t fix it
- nobody’s read the code in 3 months
- you have 3 weeks of downtime trying to re-onboard and fix it
- you lose significant % of your contracts and users
- your company is now dead
sent this to the team today
everything great comes from being able to delay gratification for as long as possible
and it feels like we're collectively losing our ability to do that
@GergelyOrosz What percentage of code in large enterprises and public sector do you think is written by an LLM? My educated guess would be 25%, optimistically.