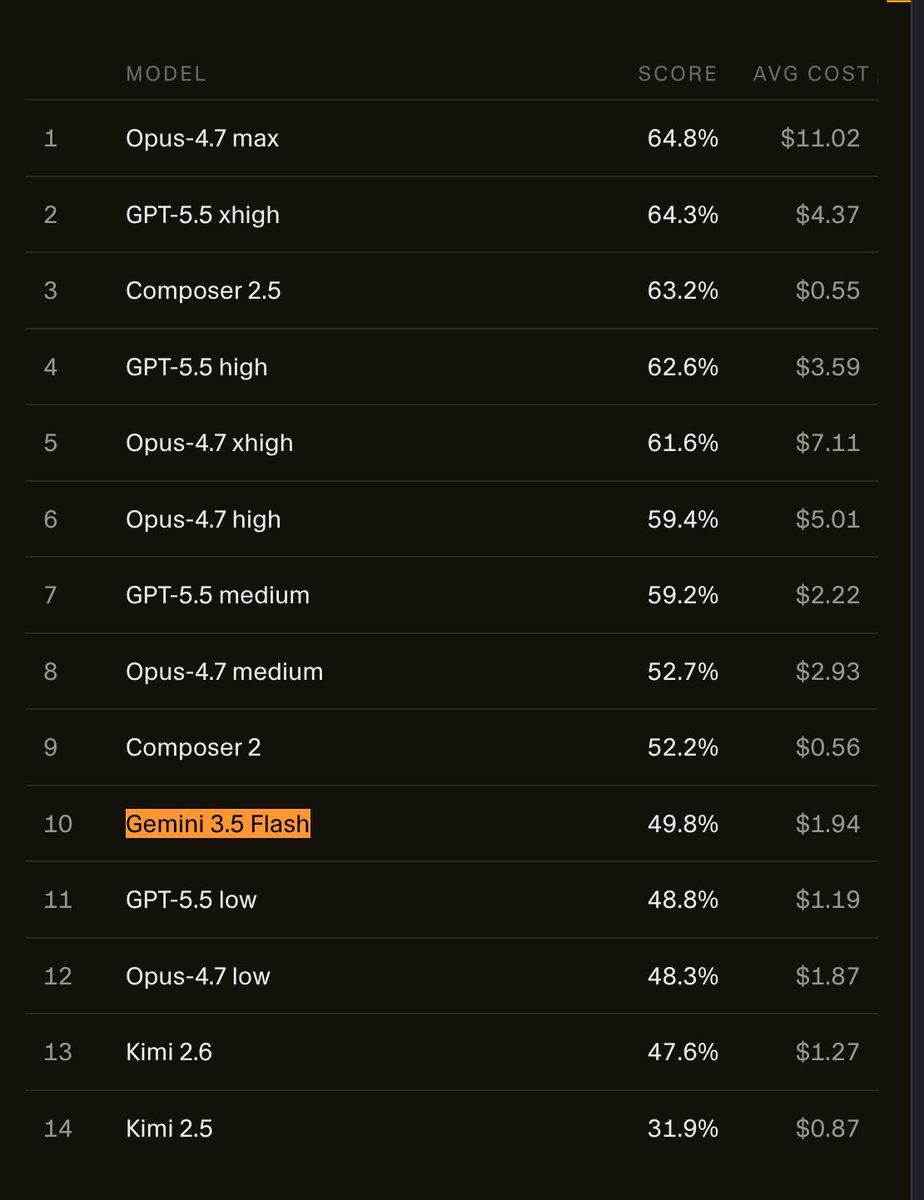
Oh my god it scored worse than Composer 2! Not even 2.5! And it cost 4x more to run!!!
This might be the worst major lab model drop of all time. Llama 4 tier. Insane.
couldn´t resist visualizing the 4 levels of Hermes Agent set up
there are multiple ways to achive each level
for level 3 and 4, you can either use my agent control room to spin up isolated docker agents, or host all agents under one instance and leverage agent profiles with the multi-agent kanban that hermes supports natively
you can also experiment with hermes as orchestrator and let it control claude / codex / kimi directly as sub agents
I'm currently prototyping inside hermes, refining workflows and automations until they're solid enough to push to an isolated docker instance
from there I can either keep it in a Hermes Agent harness or swap to other models depending on what the agent does
this keeps your agent company dynamic and lets you shape it how you want, since different models are better at different things
for example, I usually use claude for creative marketing work and GPT for infra / coding
There's an official Anthropic plugin that reads your entire project and tells you exactly what to enable, configure, and use in Claude Code.
Most people using Claude Code have no idea it exists.
SAVE IT & RUN IT BEFORE ANYTHING ELSE.
🤯Holy shit...someone just built a tool that:
• spins up its own vector DB
• runs embeddings locally
• indexes your entire codebase
• works with Claude, Cursor, Copilot
and you don’t configure anything
no API keys
no setup
no infra
you just run:
npx -y socraticode
and it handles the rest
this is how dev tools should work
4 levels of Hermes Agent setup:
LEVEL 1: main agent
You → Hermes Agent
this is your main agent and your prototype area, where you test new workflows and refine them. it doubles as your orchestrator until you have something worth breaking out
----
LEVEL 2: specialized agents
You → SEO Agent
You → CMO Agent
You → Ops Agent
once a workflow is solid, break it out into its own agent with its own credentials, memory and scope.
---
LEVEL 3: orchestrated team
You → Orchestrator
↓
Specialist Agents
bring the orchestrator back in. it now steers the company of agents you have built.
----
LEVEL 4: automated team
Cron / Events → Orchestrator
↓
Agent Team
add task lists so the team works async. cron and events fire jobs, the orchestrator routes them through the task bus, the team handles the work without you
----
take small steps, you DO NOT want to automate slop.
if your output at level 1 is mediocre, you are about to scale mediocrity. 20 agents shipping low quality work at speed is worse than 3 shipping great work slowly.
I would rather run fewer agents with better output than MAXXING the agent count and spitting out more of the same.
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
MICROSOFT OPEN SOURCED A 7B PARAMETER MODEL THAT TRANSCRIBES 60 MINUTES OF AUDIO IN A SINGLE PASS
and it's completely free
VIBEVOICE ASR no chunking, no context loss, full speaker diarization baked in
not just speech to text..not a basic wrapper
who spoke, when they spoke, exactly what they said..all in one shot
and it handles the hard stuff too..50+ languages, custom hotwords, long form audio that breaks every other tool
the model doesn't know what "context window" means apparently
Available on macOS and Windows right now.
Free to use. Free to fine tune. Free to build on.
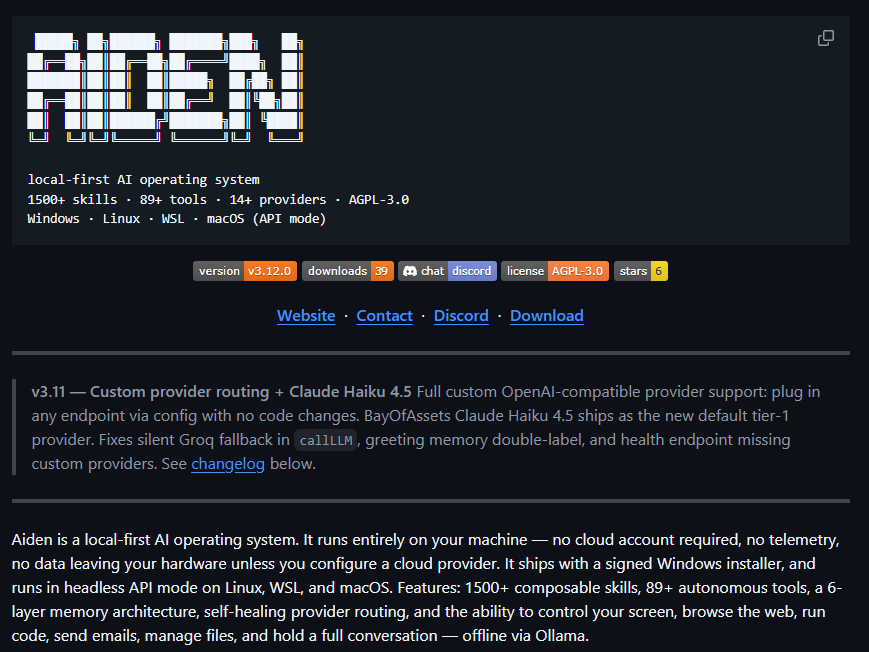
Tu PC está a punto de volverse inteligente de verdad.
Aiden es un Operating System full IA que corre 100% local en tu Windows o Linux:
- 1.500+ skills composables
- 89+ herramientas autónomas
- Controla tu mouse, teclado, pantalla y apps (como JARVIS real)
- Memoria de 6 capas + grafo de conocimiento
- Enjambre de sub-agentes que trabajan en paralelo
- Voz + canales (Discord, Telegram, WhatsApp…)
Todo offline con Ollama.
Sin cuentas.
Sin telemetría.
Sin enviar ni un byte a la nube.
Esto no es un chatbot… es tu nuevo asistente que vive dentro de tu máquina.
El futuro del personal AI ya llegó y es open source
REPOOO👇
HOLY SHIT....someone finally fixed how Claude actually works
125K+ stars on GitHub and growing fast
It’s not a new model, not a plugin gimmick, not another prompt trick
It’s a simple workflow that forces Claude to behave like a real engineer
Normally, you give Claude a task and it jumps straight into coding, makes hidden assumptions, and you end up spending the next hour correcting direction
This changes that completely
Now, Claude is forced to slow down before writing a single line of code. It reads your project, asks the right questions, explores multiple approaches, and lays out a clear plan for approval
Only after that does it start building
So instead of chaotic execution and mid-build confusion, you get structured, predictable output from the start
The biggest shift is this
You see exactly what Claude is going to build before it builds it
Which means no surprises, no constant back-and-forth, and no wasted iterations
It might feel slightly slower at the beginning, but it saves hours once execution starts
That’s why this is blowing up
Because the real problem was never the model
It was the lack of process
Fix the process, and Claude becomes a completely different tool
One line to remember
This doesn’t make Claude better at coding
It makes it better at thinking
ANDREJ KARPATHY COULD HAVE CHARGED $2,000 FOR THIS COURSE.
He put it on YouTube.
The full training stack. Tokenization. Neural network internals. Hallucinations. Tool use. Reinforcement learning. RLHF. DeepSeek. AlphaGo.
3 hours of the most comprehensive LLM education that exists anywhere at any price.
Not how to use the tools.
How the entire system was built from the ground up and why it behaves the way it does.
The engineers who understand this build things the ones who only use the tools cannot even conceive of.
The gap between those two groups is not 3 hours.
It is everything those 3 hours quietly unlock for the rest of your career.
The next step after Karpathy's wiki idea:
Karpathy's wiki works on knowledge that sits still.
A page on how attention works is just as useful today as it was a year ago.
The LLM reads sources, pulls out ideas, writes clean articles, and keeps them cross-linked.
You never have to rebuild the context from scratch when you want to ask something.
But this breaks the moment you ask a question that spans multiple things at once.
"Which authors moved from Google to Anthropic between 2022 and 2024, and what did they publish after the move?"
A Markdown page can't answer that. The answer lives in the connections between people, companies, papers, and dates.
A wiki can describe that pattern only if someone already wrote an article about it.
A graph lets you ask it directly, ask ten variations of it, and get an answer every time without rebuilding anything.
FalkorDB is an open-source graph database built for exactly this kind of question.
The idea underneath it is simple, and it's what makes the whole thing fast enough to be practical.
Most graph databases store connections as chains of pointers and follow them one by one through memory.
FalkorDB stores the entire graph as a grid of zeros and ones (a sparse matrix) where a 1 means "these two things are connected."
Once your graph is a grid, walking through it becomes math. Two hops is one multiplication. Five hops is five multiplications.
That sounds like a small change, but it lets the CPU do work in parallel and reuse decades of math research that nobody had applied to graph queries before.
In practice, this is the difference between a seven-hop question returning in 350ms and the same question timing out.
The wiki and the graph aren't competing. They sit at different layers.
The wiki stores what something is. The graph stores how everything connects.
Any work where the connections matter as much as the things being connected belongs in a graph.
FalkorDB also comes with vector search built in, which matters for GenAI work.
You can find a relevant part of the graph, search for similar items inside it, and return the answer, all in one query.
Most GraphRAG setups build this by hand across two separate databases. Here you get it in one.
You run it through Docker, query it with Cypher, and connect from Python, JavaScript, Rust, Java, Go, or any Redis client.
Open source and multi-tenant by default, so one instance can host thousands of separate graphs without spinning up thousands of servers.
Repo: https://t.co/xZ1rig02JI
Karpathy nailed the foundation. The next layer is here.
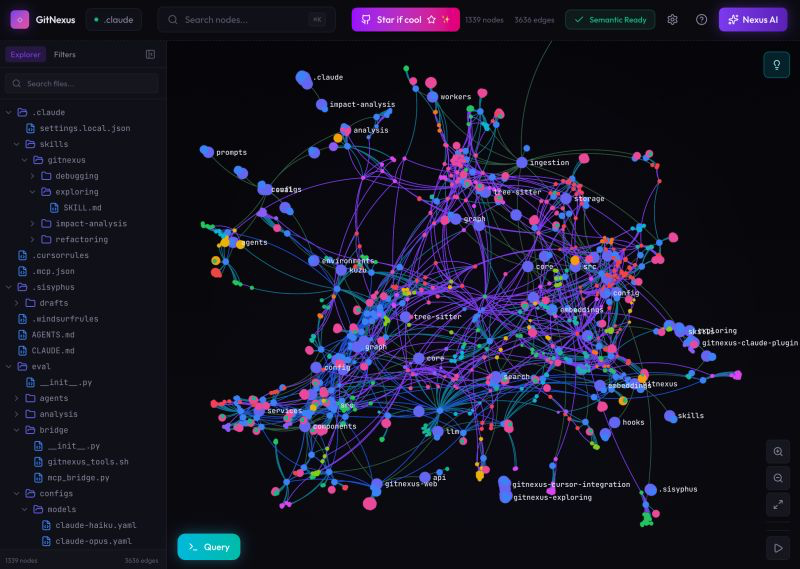
🚨Breaking: Someone open sourced a knowledge graph engine for your codebase and it's terrifying how good it is.
It's called GitNexus. And it's not a documentation tool.
It's a full code intelligence layer that maps every dependency, call chain, and execution flow in your repo -- then plugs directly into Claude Code, Cursor, and Windsurf via MCP.
Here's what this thing does autonomously:
→ Indexes your entire codebase into a graph with Tree-sitter AST parsing
→ Maps every function call, import, class inheritance, and interface
→ Groups related code into functional clusters with cohesion scores
→ Traces execution flows from entry points through full call chains
→ Runs blast radius analysis before you change a single line
→ Detects which processes break when you touch a specific function
→ Renames symbols across 5+ files in one coordinated operation
→ Generates a full codebase wiki from the knowledge graph automatically
Here's the wildest part:
Your AI agent edits UserService.validate().
It doesn't know 47 functions depend on its return type.
Breaking changes ship.
GitNexus pre-computes the entire dependency structure at index time -- so when Claude Code asks "what depends on this?", it gets a complete answer in 1 query instead of 10.
Smaller models get full architectural clarity. Even GPT-4o-mini stops breaking call chains.
One command to set it up:
`npx gitnexus analyze`
That's it. MCP registers automatically. Claude Code hooks install themselves.
Your AI agent has been coding blind. This fixes that.
9.4K GitHub stars. 1.2K forks. Already trending.
100% Open Source.
(Link in the comments)